Download

1 / 28
280 likes | 517 Views
Chi Squared Tests. Chapter 16. 16.1 Introduction. Two statistical techniques are presented, to analyze nominal data. A goodness-of-fit test for the multinomial experiment. A contingency table test of independence. Both tests use the c 2 as the sampling distribution of the test statistic.

E N D
Chi Squared Tests Chapter 16
16.1 Introduction • Two statistical techniques are presented, to analyze nominal data. • A goodness-of-fit test for the multinomial experiment. • A contingency table test of independence. • Both tests use the c2 as the sampling distribution of the test statistic.
16.2 Chi-Squared Goodness-of-Fit Test • The hypothesis tested involves the probabilities p1, p2, …, pk.of a multinomial distribution. • The multinomial experiment is an extension of the binomial experiment. • There are n independent trials. • The outcome of each trial can be classified into one of k categories, called cells. • The probability pi that the outcome fall into cell i remains constant for each trial. Moreover, p1 + p2 + … +pk = 1. • Trials of the experiment are independent
16.2 Chi-squared Goodness-of-Fit Test • We test whether there is sufficient evidence to reject a pre-specified set of values for pi. • The hypothesis: • The test builds on comparing actual frequency and the expected frequency of occurrences in all the cells.
The multinomial goodness of fit test - Example • Example 16.1 • Two competing companies A and B have enjoy dominant position in the market. The companies conducted aggressive advertising campaigns. • Market shares before the campaigns were: • Company A = 45% • Company B = 40% • Other competitors = 15%.
The multinomial goodness of fit test - Example • Example 16.1 – continued • To study the effect of the campaign on the market shares, a survey was conducted. • 200 customers were asked to indicate their preference regarding the product advertised. • Survey results: • 102 customers preferred the company A’s product, • 82 customers preferred the company B’s product, • 16 customers preferred the competitors product.
The multinomial goodness of fit test - Example • Example 16.1 – continuedCan we conclude at 5% significance level that the market shares were affected by the advertising campaigns?
The multinomial goodness of fit test - Example • Solution • The population investigated is the brand preferences. • The data are nominal (A, B, or other) • This is a multinomial experiment (three categories). • The question of interest: Are p1, p2, and p3 different after the campaign from their values before the campaign?
The multinomial goodness of fit test - Example • The hypotheses are: H0: p1 = .45, p2 = .40, p3 =.15 H1: At least one pi changed. The expected frequency for each category (cell) if the null hypothesis is true is shown below: What actual frequencies did the sample return? 90 = 200(.45) 80 = 200(.40) 102 82 30 = 200(.15) 16
The multinomial goodness of fit test - Example • The statistic is • The rejection region is
The multinomial goodness of fit test - Example • Example 16.1 – continued
The multinomial goodness of fit test - Example • Example 16.1 – continued c2 with 2 degrees of freedom Conclusion: Since 8.18 > 5.99, there is sufficient evidence at 5% significance level to reject the null hypothesis. At least one of the probabilities pi is different. Thus, at least two market shares have changed. Alpha P value 5.99 8.18 Rejection region
Required conditions – the rule of five • The test statistic used to perform the test is only approximately Chi-squared distributed. • For the approximation to apply, the expected cell frequency has to be at least 5 for all the cells (npi³ 5). • If the expected frequency in a cell is less than 5, combine it with other cells.
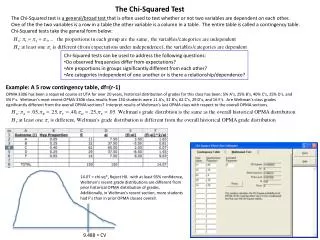
16.3 Chi-squared Test of a Contingency Table • This test is used to test whether… • two nominal variables are related? • there are differences between two or more populations of a nominal variable • To accomplish the test objectives, we need to classify the data according to two different criteria.
Contingency table c2 test – Example • Example 16.2 • In an effort to better predict the demand for courses offered by a certain MBA program, it was hypothesized that students’ academic background affect their choice of MBA major, thus, their courses selection. • A random sample of last year’s MBA students was selected. The following contingency table summarizes relevant data.
If each classification is considered a nominal variable, are these two variables dependent? If each undergraduate degree is considered a population, do these populations differ? Contingency table c2 test – Example The observed values There are two ways to address the problem
The test statistic • The rejection region k is the number of cells in the contingency table. Contingency table c2 test – Example • Solution • The hypotheses are: H0: The two variables are independent H1: The two variables are dependent Since ei = npi but pi is unknown, we need to estimate the unknown probability from the data, assuming H0 is true.
Estimating the expected frequencies Undergraduate MBA Major Degree Accounting Finance Marketing Probability 60 BA 60 60/152 BENG 31 31/152 39 BBA 39 39/152 Other 22 22/152 152 61 44 152 61 44 47 152 Probability 61/152 44/152 47/152 Under the null hypothesis the two variables are independent: P(Accounting and BA) = P(Accounting)*P(BA) = [61/152][60/152]. The number of students expected to fall in the cell “Accounting - BA” is eAcct-BA = n(pAcct-BA) = 152(61/152)(60/152) = [61*60]/152 = 24.08 The number of students expected to fall in the cell “Finance - BBA” is eFinance-BBA = npFinance-BBA = 152(44/152)(39/152) = [44*39]/152 = 11.29
(Column j total)(Row i total) Sample size eij = The expected frequencies for a contingency table • The expected frequency of cell of raw i and column j in the contingency table is calculated by
Calculation of the c2 statistic • Solution – continued Undergraduate MBA Major Degree Accounting Finance Marketing 31 24.08 BA 31 (24.08) 13 (17.37) 16 (18.55) 60 BENG 8 (12.44) 16 (8.97) 7 (9.58) 31 31 24.08 BBA 12 (15.65) 10 (11.29) 17 (12.06) 39 7 6.80 5 6.39 Other 10 (8.83) 5 (6.39) 7 (6.80) 22 31 24.08 61 44 47 152 7 6.80 5 6.39 31 24.08 The expected frequency 7 6.80 5 6.39 31 24.08 7 6.80 5 6.39 (31 - 24.08)2 24.08 c2= (5 - 6.39)2 6.39 (7 - 6.80)2 6.80 = 14.70 +….+ +….+
Contingency table c2 test – Example • Solution – continued • The critical value in our example is: • Conclusion: • Since c2 = 14.70 > 12.5916, there is sufficient evidence to infer at 5% significance level that students’ undergraduate degree and MBA students courses selection are dependent.
Using the computer Select the Chi squared / raw data Option from Data Analysis Plus under tools. See Xm16-02 Define a code to specify each nominal value. Input the data in columns one column for each category. Code: Undergraduate degree 1 = BA 2 = BENG 3 = BBA 4 = OTHERS MBA Major 1 = ACCOUNTING 2 = FINANCE 3 = MARKETING
Required condition Rule of five • The c2 distribution provides an adequate approximation to the sampling distribution under the condition that eij >= 5 for all the cells. • When eij < 5 rows or columns must be added such that the condition is met. Example 4 (5.1) 7 (6.3) 4 (3.6) 18 (17.9) 23 (22.3) 12 (12.8) 14 + 4 12.8 + 5.1 16 + 7 16 + 6.3 8 + 4 9.2 + 3.6 We combine column 2 and 3
16.5 Chi-Squared test for Normality • The goodness of fit Chi-squared test can be used to determined if data were drawn from any distribution. • The general procedure: • Hypothesize on the parameter values of the distribution we test (i.e. m = m0,s = s0 for the normal distribution). • For the variable tested X specify disjoint ranges that cover all its possible values. • Build a Chi squared statistic that (aggregately) compares the expected frequency under H0 and the actual frequency of observations that fall in each range. • Run a goodness of fit test based on the multinomial experiment.
15.5 Chi-Squared test for Normality • Testing for normality in Example 12.1 For a sample size of n=50 (see Xm12-01) ,the sample mean was 460.38 with standard error of 38.83. Can we infer from the data provided that this sample was drawn from a normal distribution with m = 460.38 and s = 38.83? Use 5% significance level.
.3413 .3413 .1587 .1587 421.55 c2 test for normality Solution First let us select z values that define each cell (expected frequency > 5 for each cell.) z1 = -1; P(z < -1) = p1 = .1587; e1 = np1 = 50(.1587) = 7.94 z2 = 0; P(-1 < z< 0) = p2 = .3413; e2 = np2 = 50(.3413) = 17.07 z3 = 1; P(0 < z < 1) = p3 = .3413; e3 = 17.07 P(z > 1) = p4 = .1587; e4 = 7.94 The cell boundaries are calculated from the corresponding z values under H0. The expected frequencies can now be determined for each cell. e2 = 17.07 e3 = 17.07 z1 =(x1 - 460.38)/38.83 = -1; x1 = 421.55 e4 = 7.94 e1 = 7.94 499.21 460.38
c2 test for normality • The test statistic (10 - 7.94)2 7.94 c2= (13 - 17.07)2 17.07 (19 - 17.07)2 17.07 (8 - 7.94)2 7.94 = 1.72 + + + f3 = 19 e3 = 17.07 e2 = 17.07 f2 = 13 f1 = 10 f4 = 8 e4 = 7.94 e1 = 7.94
c2 test for normality • The test statistic Conclusion: There is insufficient evidence to conclude at 5% significance level that the data are not normally distributed. (10 - 7.94)2 7.94 c2= (13 - 17.07)2 17.07 (19 - 17.07)2 17.07 (8 - 7.94)2 7.94 = 1.72 + + + • The rejection region