Download

1 / 37
370 likes | 543 Views
BACKGROUND LEARNING AND LETTER DETECTION USING TEXTURE WITH PRINCIPAL COMPONENT ANALYSIS (PCA). CIS 601 PROJECT SUMIT BASU FALL 2004. OUTLINE. Introduction Background Learning and Letter Detection What is “Texture”? PCA based texture representation Texture detection approach Results

E N D
BACKGROUND LEARNING AND LETTER DETECTION USING TEXTURE WITH PRINCIPAL COMPONENT ANALYSIS (PCA) CIS 601 PROJECT SUMIT BASU FALL 2004
OUTLINE • Introduction • Background Learning and Letter Detection • What is “Texture”? • PCA based texture representation • Texture detection approach • Results • Analysis and Conclusions • References
INTRODUCTION • Document image understanding involves: Layout segmentation Logical labeling of blocks at different levels. • Simplest : Text/Non-text separation • Knowledge of further information such as type style should be useful in many applications e.g.logical layout recognition, document image indexing and retrieval. • Proposed generic method based on visual perception “TEXTURE”
What is “Texture”? • An Important approach for describing a region is to quantify its texture content • Texture can be defined as that where “there is a significant variation in intensity levels between nearby pixels; that is, at the limit of resolution, there is non-homogeneity.
APPLICATIONS OF “TEXTURE” • Simplest use : Physical segmentation by classification of blocks using 2 or 3 classes (text/non-text, text/image/line drawing) by simple features like “black/white transitions” • Further analysis of document structuring: Characterizing of fonts (using geometrical properties, statistical features or generic techniques like Feature Based Interaction Maps (FBIM)), skew-detection.
APPLICATIONS OF “TEXTURE” ( contd…) • Application specific to this project : Background learning and Letter detection using “Texture” with “Principal Component Analysis” (PCA). This document analysis is a necessary pre-processing stage for many document-processing systems such as : • Optical Character Recognition. (OCR) • Document Retrieval. • Document Compression.
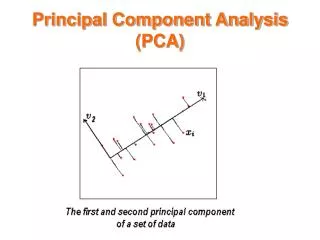
PRINCIPAL COMPONENT ANALYSIS (PCA) • Technique capable of deriving low dimensional representation which is applied extensively to identify texture of images. • Involves a mathematical procedure that transforms a number of possibly correlated variables into a smaller number of uncorrelated variables called principal components.
PRINCIPAL COMPONENT ANALYSIS (PCA) (contd…) • The first principal component accounts for as much of the variability in the data as possible, and each succeeding component accounts for as much of the remaining variability as possible. • Since images are array of data points with each point representing color, PCA can be used for reducing the image data (extracting features) to smaller dimension to represent the image qualities. remaining variability as possible. • The reduced feature represents the spatial distribution of the pixel gray values.
PRINCIPAL COMPONENT ANALYSIS (PCA) (contd…) • PCA (Principal Component Analysis): • Project the samples (points) perpendicularly onto the axis of ellipsoid • Rotates the ellipsoid to be parallel to the coordinate axes • Use the fewer and more important coordinates to represent the original samples • Transforms of PCA: The first few eigenvectors of the covariance matrix
BACKGROUND LEARNING FOR LETTER-DETECTION • Given a document image we first convert it to a gray level image. Since we are working with local texture representation only, this is not going to effect the processing of the image. • Then we divide the document image into sub-images where all sub-images are non-overlapping blocks of a specific size (We intend to use height = 32 and width = 32 pixels) • Normalize each sub-image independent of the other sub-images by subtracting the mean of the sub-image from each pixel.
BACKGROUND LEARNING FOR LETTER-DETECTION(contd…) • Normalizing would help in getting rid of any deviation that a specific sub-image might have from the other sub-images, for instance difference in brightness. • We then wish to use the sub-images to compute the principal components using PCA. • Use first few principal components to obtain a projection matrix to project each sub-image to an n-dimensional vector that constitutes its texture representation. The number of principal components to be used would be decided on an image-to-image basis.
BACKGROUND LEARNING FOR LETTER-DETECTION(contd…) • We now project all sub-images to their texture representation as n-dimensional vectors. • Now we use this background learning to exclude background sub-images from further image processing. • The remaining sub-images are the informative ones. We can now use the remaining sub-images for letter detection. • In order to exclude background sub-images, we use k-means clustering on the n-dimensional vectors corresponding to the sub-images.
BACKGROUND LEARNING FOR LETTER-DETECTION(contd…) • We developed MATLAB programs to do the above-mentioned processing and then use it on several document images to compare the performance of this procedure and try to further improve it. • We approximate k by observing the resultant image from PCA and vary k by trial and error method. • The cluster corresponding to the maximum number of sub-images represents the background. By removing these sub-images, we would be reducing the background and thus reduce total scan area for OCR software.
RESULTS : Original Document After PCA with sub-image size 16 and 25 first PCA components
RESULTS… Sub-image size 16 using all principal components Sub-image size 32 using all principal components
RESULTS… k-means with k = 4 k-means with k = 8
RESULTS… k-means with k = 12 k-means with k = 15
RESULTS… Text Image after removing background
RESULTS… Original Document After PCA with sub-image size 32 and 80 first PCA components
RESULTS… Sub-image size 16 using all principal components Sub-image size 32 using all principal components
RESULTS… k-means with k = 6 k-means with k = 12
RESULTS… k-means with k = 18 k-means with k = 30
RESULTS… Text Image after removing background
RESULTS… Original Document After PCA with sub-image size 16
RESULTS… k-means with k = 6 k-means with k = 30
RESULTS… Text Image after removing background
RESULTS… Original Document After PCA with sub-image size 16
RESULTS… k-means with k = 6 k-means with k = 30
RESULTS… Text Image after removing background
RESULTS… Original Document After PCA with sub-image size 16
RESULTS… Text Image after removing background
ANALYSIS & CONCLUSION • We tried with sub-images of different sizes: 16, 32, 64 etc. Initially we were under the impression that smaller sub-images would perform better but take more time to execute. • We figured out that is not necessarily true and that depends on the image.
ANALYSIS & CONCLUSION.. • PCA seemed to be pretty successful in identifying the text blocks in the images. In most of the images we used, we got a pretty good success rate using the sub-images as the training set. • The cluster corresponding to the maximum number of sub-images was the background in all cases.
ANALYSIS & CONCLUSION • More number of clusters doesn’t necessarily produces more text. Some text which was visible with less number of clusters, wasn’t visible with more. • However, more number of clusters reduced removed background. • There seems to be a trade off and an optimal cluster size specific to each image.
ANALYSIS & CONCLUSION • Removing the background by replacing the cluster corresponding to the maximum number of sub-images seems to be a pretty good method of reducing space to be scanned by OCR. • The number of clusters to be used is very much image dependent. The image produced by the PCA gives some idea.
ANALYSIS & CONCLUSION • In all our images PCA followed by clustering was successful in removing some background space. • It also seem to do a pretty good work of image detection. • We conclude that this method works and could be used as a tool to reduce space to be scanned by OCR.
REFERENCES • Image Retrieval Using Local PCA Texture Representation by Longin Jan Latecki, Venugopal Rajagopal, Ari Gross • Gonzalez, Woods, Eddins. Digital Image Processing Using MATLAB • Web material and Notes.