Download

1 / 21
210 likes | 360 Views
Map-Reduce for large scale similarity computation. Lecture 2. …from last lecture. H ow to convert entities into high-dimensional numerical vectors H ow to compute similarity between two vectors. For example, is x and y are two vectors then . ..from last lecture. Example:

E N D
…from last lecture How to convert entities into high-dimensional numerical vectors How to compute similarity between two vectors. For example, is x and y are two vectors then
..from last lecture Example: X = (1,2,3) ; Y= (3,2,1) ||X|| = (1+4+9) = 140.5 = 3.74 ||Y|| = ||X|| Sim(X,Y) = (1.3 + 2.2 + 3.1)/(3.742 ) = 10/14 = 5/7 We also learnt that for large data sets computing pair-wise similarity can be very time consuming.
Map-Reduce Map-Reduce has become a popular framework for speeding up computations like pair-wise similarity Map-Reduce was popularized by Google and then Yahoo! (through the Hadoop open-source implementation) Map-Reduce is a programming model built on top of “cluster computing”
Cluster Computing Put simple (commodity) machines together, each with their own CPU, RAM and DISK, for parallel computing Switch rack rack
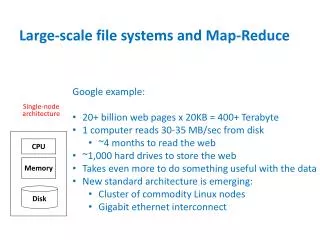
Map-Reduce • Map-Reduce consists of two distinct entities • Distributed File System (DFS) • Library to implement Mapper and Reducer functions • A DFS seamlessly manages files on the “cluster computer.” • A file is broken into “chunks” and these chunks are replicated across the nodes of a cluster. • If a node which contains chunk A fails, the system will re-start the computation on a node which contains a copy of the chunk.
Distributed File System A DFS will “chunk” files and replicated them across several nodes and then keep track of the chunks. Only practical when data is mostly read only (e.g., historical data; not for live data –like airline reservation system). File Node 2,6,7 Node 3,2,18
Node failure • When several nodes are in play the chances that a singlenodegoes down at any time goes up significantly. .. • Suppose they are n nodes and let p be the probability that a single node will fail.. • (1-p) that single node will not fail • (1-p)n that none of the nodes will fail • 1 – (1-p)n that at least one will fail.
Node failure The probability that at least one node failing is: f= 1 – (1-p)n When n =1; then f =p Suppose p=0.0001 but n=10000, then: f = 1 – (1 -0.0001)10000 = 0.63 [why/how ?] This is one of the most important formulas to know (in general).
Example: “Hello World” of MR Task: Produce an output which, for each word in the file, counts the number of times it appears in the file. Answer: (Java, 3); (Silent, 2), (mind,3)……
Example • For example • {doc1, doc2} machine 1 • {doc3,doc4} machine 2 • {doc5,doc6} machine 3 • Each chunk is also duplicated to other machines.
Example • Now apply the MAP operation to each node and emit the pair (key, 1). • Thus doc1 emits: • (silent,1); (mind,1); (holy, 1); (mind,1) • Similarly doc6 emits: • (silent,1);(road,1); (to,1); (Cairns,1)
Example Note in the first chunk which contains (doc1, doc2)..each doc emits (key,value) pairs. We can think that each computer node emits a list of (key, value) pairs. Now this list is “grouped” so that the REDUCE function can be applied.
Example • Note now that the (key,value) pairs have no connection with the docs… • (silent,1),(mind,1), (holy, 1), (mind,1), (road,1),(to,1),(Cairns,1); (Java,1),(programming,1),(is,1),(fun,1),……. • Now we have a hash function h:{a..z} {0,1} • Basically two REDUCE nodes • And (key,value) effectively become (key, list)
Example • For example suppose the hash functions maps {to, Java, road} to one node. Then • (to,1) remains (to,1) • (Java,1);(Java,1);(Java,1) (Java, [1,1,1]) • (road,1);(road,1)(road,[1,1]); • Now REDUCE function converts • (Java,[1,1,1]) (Java,3) etc. • Remember this is a very simple example…the challenge is to take complex tasks and express them as Map and Reduce!
Schema of Map-Reduce Tasks [MMDS] chunks (key,value) pairs [k,(v,u,w,x,z)] (k,v) chunks chunks Output Group By Keys Map Task Reduce Task
The similarity join problem Last time we discussed about computing the pair-wise similarity of all articles/documents in Wikipedia. As we discussed it was time consuming problem because if N is the number of documents, and d is the length of each vector, then the running time proportional to O(N2d). How can this problem be attacked using the Map Reduce framework.
Similarity Join • Assume we are given two documents (vectors) d1 and d2. Then (ignoring the denominator) • Example: • d1 = {silent mind to holy mind}; d2 = {silent road to cairns} • sim(d1,d2) = 1silent,d11silent,d2 + 1to,d111to,d2 = 2 • Exploit the fact that a term (word) only contributes if it belongs to at least two documents.
Similarity Example [2] Notice, it requires some ingenuity to come up with key-value pairs. This is key to suing map-reduce effectively
Amazon Map Reduce • For this class we have received an educational grant from Amazon to run exercises on their Map Reduce servers. • Terminology • EC2 – is the name of Amazon’s cluster • S3 – is the name of their storage machines • Elastic Map Reduce – is the name Amazon’s Hadoop implementation of Map-Reduce • Lets watch this video.
References Massive Mining of Data Sets (Rajaram, Leskovec, Ullman) Computing Pairwise Similarity in Large Document Collection: A Map Reduce Perspective (El Sayed, Lin, Oard)