Download

1 / 35
350 likes | 518 Views
Map-Reduce and Parallel Computing for Large-Scale Media Processing. Youjie Zhou. Outline. Motivations Map-Reduce Framework Large-scale Multimedia Processing Parallelization Machine Learning Algorithm Transformation Map-Reduce Drawbacks and Variants Conclusions. Motivations.

E N D
Map-Reduce and Parallel Computing for Large-Scale Media Processing Youjie Zhou
Outline • Motivations • Map-Reduce Framework • Large-scale Multimedia Processing Parallelization • Machine Learning Algorithm Transformation • Map-Reduce Drawbacks and Variants • Conclusions
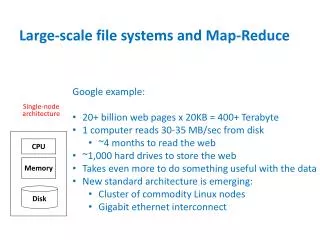
Motivations • Why we need Parallelization? • “Time is Money” • Simultaneously • Divide-and-conquer • Data is too huge to handle • 1 trillion (10^12) unique URLs in 2008 • CPU speed limitation
Motivations • Why we need Parallelization? • Increasing Data • Social Networks • Scalability! • “Brute Force” • No approximations • Cheap clusters v.s. expensive computers
Motivations • Why we choose Map-Reduce? • Popular • A parallelization framework Google proposed and Google uses it everyday • Yahoo and Amazon also involve in • Popular Good? • “Hides” parallelization details from users • Provides high-level operations that suit for majority algorithms • Good start on deeper parallelization researches
Map-Reduce Framework • Simple idea inspired by function language (like LISP) • map • a type of iteration in which a function is successively applied to each element of one sequence • reduce • a function combines all the elements of a sequence using a binary operation
Map-Reduce Framework • Data representation • <key,value> • map generates <key,value> pairs • reduce combines <key,value> pairs according to same key • “Hello, world!” Example
Map-Reduce Framework split0 map reduce data split1 map reduce reduce output split2 map reduce
Map-Reduce Framework • Count the appearances of each different word in a set of documents • void map (Document) • for each word in Document • generate <word,1> • void reduce (word,CountList) • int count = 0; • for each number in CountList • count += number • generate <word,count>
Map-Reduce Framework • Different Implementations • Distributed computing • each computer acts as a computing node • focusing on reliability over distributed computer networks • Google’s clusters • closed source • GFS: distributed file system • Hadoop • open source • HDFS: hadoop distributed file system
Map-Reduce Framework • Different Implementations • Multi-Core computing • each core acts as a computing node • focusing on high speed computing using large shared memories • Phoenix++ • a two dimensional <key,value> table stored in the memory where map and reduce read and write pairs • open source created by Stanford • GPU • 10x higher memory bandwidth than a CPU • 5x to 32x speedups on SVM training
Large-scale Multimedia Processing Parallelization • Clustering • k-means • Spectral Clustering • Classifiers training • SVM • Feature extraction and indexing • Bag-of-Features • Text Inverted Indexing
Clustering • k-means • Basic and fundamental • Original Algorithm • Pick k initial center points • Iterate until converge • Assign each point with the nearest center • Calculate new centers • Easy to parallel!
Clustering • k-means • a shared file contains center points • map • for each point, find the nearest center • generate <key,value> pair • key: center id • value: current point’s coordinate • reduce • collect all points belonging to the same cluster (they have the same key value) • calculate the average new center • iterate
Clustering • Spectral Clustering • S is huge: 10^6 points (double) need 8TB • Sparse It! • Retain only S_ij where j is among the t nearest neighbors of i • Locality Sensitive Hashing? • It’s an approximation • We can calculate directly Parallel
Clustering • Spectral Clustering • Calculate distance matrix • map • creates <key,value> so that every n/p points have the same key • p is the number of node in the computer cluster • reduce • collect points with same key so that the data is split into p parts and each part is stored in each node • for each point in the whole data set, on each node, find t nearest neighbors
Clustering • Spectral Clustering • Symmetry • x_j in t-nearest-neighbor set of x_i ≠ x_i in t-nearest-neighbor set of x_j • map • for each nonzero element, generates two <key,value> • first: key is row ID; value is column ID and distance • second: key is column ID; value is row ID and distance • reduce • uses key as row ID and fills columns specified by column ID in value
Classification • SVM
Classification • SVM SMO • instead of solving all alpha together • coordinate ascent • pick one alpha, fix others • optimize alpha_i
Classification • SVM SMO • But we cannot optimize only one alpha for SVM • We need to optimize two alpha each iteration
Classification • SVM • repeat until converge: • map • given two alpha, updating the optimization information • reduce • find the two maximally violating alpha
Feature Extraction and Indexing • Bag-of-Features • features feature clusters histogram • feature extraction • map • takes images in and outputs features directly • feature clustering • clustering algorithms, like k-means
Feature Extraction and Indexing • Bag-of-Features • feature quantization histogram • map • for each feature on one image, find the nearest feature cluster • generates <imageID,clusterID> • reduce • <imageID,cluster0,cluster1…> • for each feature cluster, updating the histogram • generates <imageID,histogram>
Feature Extraction and Indexing • Text Inverted Indexing • Inverted index of a term • a document list containing the term • each item in the document list stores statistical information • frequency, position, field information • map • for each term in one document, generates <term,docID> • reduce • <term,doc0,doc1,doc2…> • for each document, update statistical information for that term • generates <term,list>
Machine Learning Algorithm Transformation • How can we know whether an algorithm can be transformed into a Map-Reduce fashion? • if so, how to do that? • Statistical Query and Summation Form • All we want is to estimate or inference • cluster id, labels… • From sufficient statistics • distances between points • points positions • statistic computation can be divided
Machine Learning Algorithm Transformation • Linear Regression reduce map reduce map reduce map Summation Form
Machine Learning Algorithm Transformation • Naïve Bayesian reduce map
Machine Learning Algorithm Transformation • Solution • Find statistics calculation part • Distribute calculations on data using map • Gather and refine all statistics in reduce
Map-Reduce Systems Drawbacks • Batch based system • “pull” model • reduce must wait for un-finished map • reduce “pull” data from map • no iteration support directly • Focusing too much on distributed system and failure tolerance • local computing cluster may not need them
Map-Reduce Systems Drawbacks • Focusing too much on distributed system and failure tolerance
Map-Reduce Variants • Map-Reduce online • “push” model • map “pushes” data to reduce • reduce can also “push” results to map from the next job • build a pipeline • Iterative Map-Reduce • higher level schedulers • schedule the whole iteration process
Map-Reduce Variants • Series Map-Reduce? Map-Reduce? MPI? Condor? Multi-Core Map-Reduce Multi-Core Map-Reduce Multi-Core Map-Reduce Multi-Core Map-Reduce
Conclusions • Good parallelization framework • Schedule jobs automatically • Failure tolerance • Distributed computing supported • High level abstraction • easy to port algorithms on it • Too “industry” • why we need a large distributed system? • why we need too much data safety?
References [1] Map-Reduce for Machine Learning on Multicore [2] A Map Reduce Framework for Programming Graphics Processors [3] Mapreduce Distributed Computing for Machine Learning [4] Evaluating mapreduce for multi-core and multiprocessor systems [5] Phoenix Rebirth: Scalable MapReduce on a Large-Scale Shared-Memory System [6] Phoenix++: Modular MapReduce for Shared-Memory Systems [7] Web-scale computer vision using MapReduce for multimedia data mining [8] MapReduce indexing strategies: Studying scalability and efficiency [9] Batch Text Similarity Search with MapReduce [10] Twister: A Runtime for Iterative MapReduce [11] MapReduce Online [12] Fast Training of Support Vector Machines Using Sequential Minimal Optimization [13] Social Content Matching in MapReduce [14] Large-scale multimedia semantic concept modeling using robust subspace bagging and MapReduce [15] Parallel Spectral Clustering in Distributed Systems
Thanks Q & A