Download

1 / 37
390 likes | 646 Views
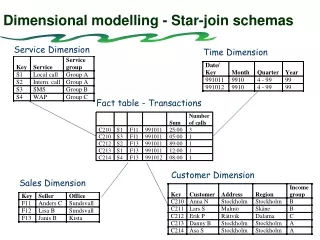
Dimensional Modelling. II. Factless Fact Table. Generally Fact Table contains concatenated primary key linking it to dimension tables facts or measures Task: Keep track of student attendance Dimensions: student, course, date, room, Instructor What is the measurement ?

E N D
Factless Fact Table • Generally Fact Table contains • concatenated primary key linking it to dimension tables • facts or measures • Task: Keep track of student attendance • Dimensions: • student, • course, • date, • room, • Instructor • What is the measurement ? • In the fact Table, attendance can be indicated with the number one. • Every fact table row will contain the number one as attendance • If fact table represents events => Factless Fact table
Data Granularity • Granularity : level of detail in the fact table • Lowest grain: facts or metrics are at the lowest possible level at which they could be captured from the operational systems. • What are the advantages of keeping the fact table at the lowest grain? • users can drill down to the lowest level of detail from the data warehouse without the need to go to the operational systems themselves. • Base level fact tables must be at the natural lowest levels of all corresponding dimensions. By doing this, queries for drill down and roll up can be performed efficiently. • What then are the natural lowest levels of the corresponding dimensions? • Example from sales department with the dimensions of product, date, customer, and sales representative, • an individual product, • a specific individual date, • an individual customer, • individual sales representative, respectively. • => Fact table contains measurements at the lowest level • Fact tables at the lowest grain facilitate “graceful” extensions. • Adding an attribute to a dimension table or even adding a new dimension table will NOT effect old queries. • Granular fact tables serve as natural destinations for current operational data : Less Transformations rquirements • Data mining applications need details at the lowest grain. • Data warehouses feed data into data mining applications. • What is the trade-off? • Increased storage and maintenance requirements • large numbers of fact table rows. • Aim : build aggregate fact tables to support queries looking for summary numbers.
Star Schema Keys • Each dimension table must have a Primary Keys • Each row in a dimension table is identified by a unique value of an attribute designated as the primary key of the dimension. • Can we use the primary keys of the operational system? • Example: Customer already has a unique Primary Key in the OLTP system • Possible scenarios when these are used as PK of dimension tables. • Products table has a PK product code with 8-position chars: Two indicate the code of the warehouse where the product is normally stored, and two other positions denote the product category …. Assume productcode is used as PK of the dimension table: • What happens if the product code gets changed in the middle of a year, because the product is now stored in a different warehouse of the company. • Remember : The data warehouse contains historic data
Primary keys of Dimension tables • Avoid PKs with built in meanings • Run away from PKs with multiple meanings! • Avoid PKs that may be re-used • PK of a an old customer is assigned to new customers • Use Surrogate Keys : System generated “meaningless” keys • Keep the OLTP PKs as additional attributes in the dimension tables
Primary Key of Fact Table • The Fact table is on the many side of 1:M relationships with dimension tables=> It contains the PKs of the dimension tables as Foreign Keys. • What should be the PK of the Fact Table: • A single compound primary key whose length is the total length of the keys of the individual dimension tables. • Foreign keys must also be kept in the fact table as additional attributes • Increases the size of the fact table. • A concatenated primary key that is the concatenation of all the primary keys of the dimension tables. • NO need to keep the primary keys of the dimension tables as additional attributes to serve as foreign keys. • Individual parts of the primary keys themselves will serve as the foreign keys. • A generated primary key independent of the keys of the dimension tables. • Foreign keys must also be kept in the fact table as additional attributes. • Increases the size of the fact table.
Advantages of the Star Schema • Easy for users to understand • Data warehouse users must understand the data structures used. • Formulate queries and reference data structures (tables) • Star schema is based on business Dimensions + metrics • Optimizes navigation • Relationships used for joining tables (fact table to dimension table) are • easy to understand • Optimized • Short • Straight forward join paths • More suitable for query processing. All queries are executed/formulated in the same way • Use filtering conditions to select rows from dimension tables • Find corresponding rows in the fact table • Star-join and star-index • STARJoin: single pass, high speed, parallelizable, multitable join • STARIndex: specialized index to increase STARjoin performance
Snowflake Schema • Snowflake Schema A variant of the star schema where each dimension can have its dimensions. Starflake schema is a hybrid structure that contains a mixture of star (denormalized) and snowflake (normalized) schemas. Allows dimensions to be present in both forms to cater for different query requirements. -- Kimball Ralph, Data Warehouse Toolkit ---
When to Snowflake? ‘Snowflaking’ is a method of normalizing the dimension tables in a Star schema. City Classification table Customer Dimension table Customer Key Customer name address Zip City class key City class key (pk) City code Class description Population range Cost of living Pollution index Public trans Customer indes Fact Table Customer key Other keys metrics • If a dimension is very large, the savings in storage could be substantial. If the dimension table is normalized • Users may now browse the additional attributes in the new normalized table only when required.
Updates • Updates to the fact table • Frequent: Addition of rows • Rare: Changes in row (adjustments in values) • Rare: Addition of attributes (new fact or metric) • Updates to dimension tables • Slow addition of rows • Slow addition of attributes • New dimensions
Updates to the Dimension Tables • Most dimensions are generally constant over time • If not constant, change slowly over time • The key of the source record does not change • The description and other attributes change slowly over time • In the source OLTP systems, the new values overwrite the old values Overwriting is not always the best option for dimension table attributes The way updates are made depends on the type of change
Type 1 Changes: Correction of Errors • Properties • Usually, the changes relate to correction of errors in source systems. • Sometimes the change in the source system has no significance. • The old value in the source system needs to be discarded. • The change in the source system need not be preserved in the data warehouse Correcting a spelling mistake in name Changing name due to marriage Changing marital Status?????
Type 1 Changes: Correction of Errors • Approach • Overwrite the attribute value in the dimension table row with the new value • The old value of the attribute is not preserved • No other change are made in the dimension table row • The key of this row or any other key value are not affected • This type is easiest to implement
Type 2 Changes: Preservation of History • Properties • They usually relate to true changes in source systems • There is a need to preserve history in the data warehouse • This type of change partitions the history in the data warehouse • Every change for the same attribute must be preserved Change of Address Change in marital status Track orders by marital status, state …
Type 2 Changes: Preservation of History • Approach • Add a new dimension table row with the new value of the changed attribute • An effective data field may be added into the dimension table • There are no changes to the original row of the dimension table • The new row is inserted with a new surrogate key • The key of the original row is not affected
Type 3 Changes: Tentative Soft Revisions • Properties • They usually apply to “soft” or tentative changes in the source systems • There is a need to keep track of history with old and new values of the changed attribute • They are used to compare performances across the transition • They provide the ability to track forward and backward
Type 3 Changes: Tentative Soft Revisions • Approach • Add an “old” field in the dimension table for the affected attribute • Push down the existing value of the attribute from the “current” field to the “old” field • Keep the new value of the attribute in the “current” field • Also, you may add a “current” effective date field for the attribute • The key of the row is not affected • No new dimension row is needed
Junk Dimensions • Dimensions for a DW are typically taken from operational source systems • Source systems contain many additional attributes (such as flags, text, descriptions, etc) that may not be useful in a DW • What are the options • Discard all such fields in the source systems • Include them in the fact table • Include all of them as dimensions • Select some and add them to a single “junk” dimension table
Large Dimensions • Large dimensions? • Large number of rows (deep) • Large number of attributes (wide) • Dimensions can become large because of frequent changes (what type?) and need to have many attributes for analysis • Consequence • Slow and inefficient • Solution • Proper logical and physical design • Indexes • Optimized algorithms
Large Dimensions: Vertical Segmentation Dividing a large, rapidly changing dimension table
Vertical Segmentation • Separate attributes in other tables • Overhead of shared locks may be reduced • Table scans can be faster • Could cause excessive joins
Vertical Segmentation Separate attributes into other tables Branch_id PKSchool_id PK Month_yr School_nameSchool_Address Ref School Branch Branch_id PKSchool_id PK Month_yr School_nameSchool_Address Number_of_GraduatesNumber_of_underGraduate Semaster_Tuition Branch_id PKSchool_id PK Month_yr Number_of_GraduatesNumber_of_underGraduates Semaster_Tuition
Horizontal Segmentation • Separate subset of data to another table • For example, separate yearly sales data into tables containing only monthly data • Separate subsets of data to another table (Jan, Feb, ..) • Use UNION to query multiple tables. • Multiple queries of multiple tables (UNION) • Breaking up tables will speed table scans
Multiple Hierarchies Multiple hierarchies in a large product dimension Notice that some attributes are “shared” among the multiple hirerarchies
Shared Dimension Tables Time Newspaper owner Fact Table Fact Table Branch PropertySale Advertisement Promotion Property For sale Star Constellation
Property Sales With Normalized Version of Branch Dimension Table : Snowflake Schema PropertySale Branch Id (PK) Branch no Branch type City (FK) timeId key propertyid key branchid key Clinetid key Promotionid Key Staffid key Ownerid key This is not an ERD City City ID(PK) Region ID (FK) Region Roll Up (Dimension Hierarchies) Region ID (PK)
Some Design Issues • Too Few Dimensions • Dimensions Are Lacking Aggregate Level • Too Many Dimensions- • One Possibility Combine Dimensions • Overly Complex Dimensions • One Possibility: Split Dimensions • Vertical/Horizontal • Another Possibility: The Snowflake Schema • Multiple Fact tables • Star constellations