Download
1 / 80
800 likes | 965 Views
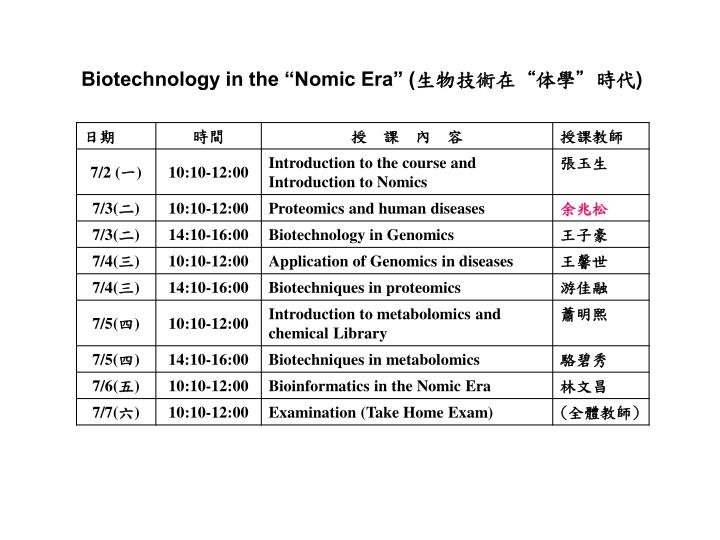
Biotechnology in the “Nomic Era” ( 生物技術在 “ 体學 ” 時代 ). Proteomics and human diseases. Jau-Song Yu ( 余兆松 ) Department of Cell and Molecular Biology, Institute of Basic Medical Sciences, Medical College of Chang Gung University. ( 長庚大學基礎醫學所分子生物學科 ). Genomics:

E N D
Biotechnology in the “Nomic Era” (生物技術在“体學”時代)
Proteomics and human diseases Jau-Song Yu (余兆松) Department of Cell and Molecular Biology, Institute of Basic Medical Sciences, Medical College of Chang Gung University (長庚大學基礎醫學所分子生物學科)
Genomics: • Identification and characterization of genes (gene expression) and their • arrangement in chromosomes • Proteomics (Functional Genomics): • Functional analysis of gene products (proteins) --- Global analysis of • hundreds to thousands of proteins in cells or tissues simultaneously • Bioinformatics: • Storage, analysis and manipulation of the information from genomics • and proteomics Genomics Proteomics Bioinformatics
What is “proteomics”? (“蛋白質體學”) “the PROTEin complement of the genOME” The term proteome, refers to proteins that are encoded and expressed by a genome, and was first suggested in 1994 byMarc Wilkins. Wilkins defines proteomics as "the study of proteins, how they're modified, when and where they're expressed, how they're involved in the metabolic pathways and how they interact with each other." The University of New South Wales (UNSW), Sydney, Australia Research Description: Interactome research, proteomics, bioinformatics for proteomics and its application to biomedical research.
Diseases Medical research Changes of physiological functions Alterations of functional molecules 99% sequence of human genome published Global changes of DNA, RNA and protein 15 February 2001 16 February 2001The Human Genome
Global gene expression analysis --- cDNA microarray Breast cancer samples vs. normal tissues PNAS USA 98, 10869–10874 (2001)
The extent of gene expression (i.e. the amount of mRNA) is only one of the many factors determining the protein function in cells mRNA stability, alternative splicing, etc. Post-translational Modification of proteins (covalent modification, proteolytic cleavage, activator, inhibitor, etc) C2H5 PO4
How to analyze hundreds to thousands of proteins in cells or tissues simultaneously? Separation of proteins on one or more matrixes --- 2D-gel MDLC Identification and/or quantitation of separated proteins in a high-throughput way --- mass spectrometry * MS *
General principle and protocol of 2-dimension gel electrophoresis Ampholytes sample Isoelectric focusing (1st dimension) pH 9 - pH 3 + polyacrylamide 2nd dimension SDS-PAGE MW pH gradient
Traditional equipment for isoelectric focusing (IEF) Ampholytes polyacrylamide Cathode (-) electrode solution Anode (+) electrode solution
Immobilized pH Gradient (IPG) Acrylamide monomer Acidic buffering group: COO- CH2 - CH-C-NH-R Basic buffering group: NH3+ O Polyacrylamide gel
acidic basic Production of Immobilized pH Gradient (IPG) strip Gradient maker A D plastic support film B E C F pH 3 pH 10
IPG strip rehydration and sample loading Strip holder Anode (+) electrode Cathode (-) electrode 30 voltage 12hr
Electrode pads Holder cover IPG strip Electrode Voltage Time First dimension: Isoelectric focusing 1. Place electrode pads (?) 2. 200 V step-n-hold 1.5hr 3. 500 V step-n-hold 1.5hr 4. 1000 V gradient 1500vhr 5. 8000 V gradient (?)36000vhr
SDS SDS-PAGE SDS-PAGE Marker in paper 0.5% agarose in running buffer SDS-PAGE • Second dimension: SDS-PAGE • SDS equilibration • SDS-PAGE SDS equilibration buffer 50 mM Tris-HCl 6 M Urea 30% Glycerol 2% SDS Trace Bromophenol IPG strip
Detection of proteins separated on gels --- Protocol of silver stain: 50% methanol 25% acetic acid 4hr ddH2O 30 sec ddH2O x 3 times 30min/time 3% Na2CO3 0.0185% formaldehyde 0.004% DTT solution 30min 2.3M citric acid 0.1% AgNO3 30min 5% acetic acid 25% methanol Fluorescent dyes: Sypro Ruby, Cy3, Cy5, Cy2 etc.
3 pH 10 kDa 200 116 97 66 55 36 31 20 14
How to analyze hundreds to thousands of proteins in cells or tissues simultaneously? ●Separation of proteins on one or more matrixes --- 2D-gel MDLC ● Identification and/or quantitation of separated proteins in a high-throughput way --- mass spectrometry MS
What is a mass spectrometer and what does it do? Gary Siuzdak (1996) Mass Spectrometry for Biotechnology, Academic Press
Mass spectrometers used in proteome research Two ionization methods Electrospray ionization (ESI) MALDI NATURE, 422, 198-207, (2003) NATURE REVIEWS MOLECULAR CELL BIOLOGY, 5, 699-711 (2004)
MALDI-TOF MS (Matrix-assisted laser desorption/ionization-Time of flight) (基質輔助雷射脫附游離-飛行時間質譜儀) Target plate Time of Flight Target plate M/Z
Mass Analyzer-Time of Flight (TOF) Kinetic Energy = ½ mv2 v = (2KE/m) m/z
Sensitivity of MALDI-TOF MS ~10 fg 1347.7 g/mole x 5 x 10 -18 mole = 6.74 x 10 –15 g
How to identify proteins by MALDI-TOF MS? Linking between genomics/bioinformatics/proteomics (?????) Digested by trypsin (Lys, Arg) (854, 931, 935, 1021, 1067, 1184, 1386, 1438) (621, 754, 778, 835, 1204,, 1398, 1476, 1582) (664, 711, 735, 904, 1079, 1188, 1438) (602, 755, 974, 1166, 1244, 1374) (Masses of tryptic peptides are predictable from gene sequence databases) MALDI-TOF MS analysis (M/Z) (854, 935, 1021, 1067, 1184, 1386, 1438) (621, 778, 835, 1204,, 1398, 1582) (735, 904, 1079, 1188, 1438) (755, 974, 1244, 1374) Database search/mapping Protein identified (100%?)
(4) 3 1 2 4 pH 10 3 (1) 170 116.3 66.3 (2) 55.4 29 (3) 21.5 (4)
Direct identification of the amino acid sequence of peptides by tandem mass spectrometry
LC-MS/MS Cell. Mol. Life Sci. 62 (2005) 848–869
How useful is the mass spectrometry-based proteomics? Recent successes illustrate the role of mass spectrometry-based proteomics as an indispensable tool for molecular and cellular biology and for the emerging field of systems biology. These include the study of protein–protein interactions via affinity-based isolations on a small and proteome-wide scale, the mapping of numerous organelles, the concurrent description of the malaria parasite genome and proteome, and the generation of quantitative protein profiles from diverse species. The ability of mass spectrometry to identify and, increasingly, to precisely quantify thousands of proteins from complex samples can be expected to impact broadly on biology and medicine. Nature, 422, 198-207, 2003
“Proteomics” and “Genomics” as the key words Total: 20795 Total: 11102 Paper No. in PubMed Year Year Proteomics (since 1998) Genomics (since 1988)
The Nobel Prize in Chemistry 2002 The Nobel Prize in Chemistry for 2002 is to be shared between scientists working on two very important methods of chemical analysis applied tobiological macromolecules: mass spectrometry (MS) and nuclear magnetic resonance (NMR). Laureates John B. Fenn, Koichi Tanaka (MS) and Kurt Wuthrich (NMR) have pioneered the successful application of their techniques to biological macromolecules. Biological macromolecules are the main actors in the makeup of life whether expressed in prospering diversity or in threatening disease. To understand biology and medicine at molecular level where the identity, functional characteristics, structural architecture and specific interactions of biomolecules are the basis of life, we need to visualize the activity and interplay of large macromolecules such as proteins. To study, or analyse, the protein molecules, principles for their separation and determination of their individual characteristics had to be developed. Two of the most important chemical techniques used today for the analysis of biomolecules are mass spectrometry (MS) and nuclear magnetic resonance (NMR), the subjects of this year’s Nobel Prize award.
Molecular & Cellular Proteomics 5:1703–1707, 2006. A high throughput process including subcellular fractionation and multiple protein separation and identification technology allowed us to establish the protein expression profile of human fetal liver, which was composed of at least 2,495 distinct proteins and 568 non-isoform groups identified from 64,960 peptides and 24,454 distinct peptides. In addition to the basic protein identification mentioned above, the MS data were used for complementary identification and novel protein mining. By doing the analysis with integrated protein, expressed sequence tag, and genome datasets, 223 proteins and 15 peptides were complementarily identified with high quality MS/MS data.
Molecular & Cellular Proteomics 6:64–71, 2007. It has long been thought that blood plasma could serve as a window into the state of one’s organs in health and disease because tissue-derived proteins represent a significant fraction of the plasma proteome. Although substantial technical progress has been made toward the goal of comprehensively analyzing the blood plasma proteome, the basic assumption that proteins derived from a variety of tissues could indeed be detectable in plasma using current proteomics technologies has not been rigorously tested. Here we provide evidence that such tissue-derived proteins are both present and detectable in plasma via direct mass spectrometric analysis ofcaptured glycopeptides and thus provide a conceptual basis for plasma protein biomarker discovery and analysis.
Molecular & Cellular Proteomics 4:1920–1932, 2005. et al. From the ‡Department of Biotechnology, AlbaNova University Center, Royal Institute of Technology (KTH), SE-106 91 Stockholm, Sweden and the ¶Department of Genetics and Pathology, Rudbeck Laboratory, Uppsala University, SE-751 85 Uppsala, Sweden Antibody-based proteomics provides a powerful approach for the functional study of the human proteome involving the systematic generation of protein-specific affinity reagents. We used this strategy to construct a comprehensive, antibody-based protein atlas for expression and localization profiles in 48 normal human tissues and 20 different cancers. Here we report a new publicly available database containing, in the first version, 400,000 high resolution images corresponding to more than 700 antibodies toward human proteins. Each image has been annotated by a certified pathologist to provide a knowledge base for functional studies and to allow queries about protein profiles in normal and disease tissues. Our results suggest it should be possible to extend this analysis to the majority of all human proteins thus providing a valuable tool for medical and biological research.
Other Proteome Databases/Datasets Human natural killer cell secretory lysosome --- 222 proteins --- MCP 2007 Human Jurkat T lymphoma cells protein kinases --- 140 kinases --- MCP 2006 Human amniotic fluid proteome --- 69 proteins --- Electrophoresis 2006 Human platelet proteome --- 641 proteins --- Proteomics 2005 Human salivary proteome --- 309 & 1381 proteins --- Proteomics 2005/J Proteome Res 2006 Human breast tumor interstitial fluid proteome --- 267 proteins --- MCP 2004 Human pituitary adenoma proteome --- 111 proteins --- Proteomics 2003 Human cell line (6) proteomes --- 2341 proteins --- MCP 2003 Human stomach tissue --- 136 proteins --- Electrophoresis 2002 Human colon cancer cell line membrane proteome --- 284 proteins --- Electrophoresis 2000 Human centrosome proteome --- 64 proteins --- Nature 2003 Human pleural effusion proteome --- 1415 proteins --- J Proteome Res 2005 Rat liver rough ER, smooth ER, and Golgi apparatus proteomes - >1400 proteins -Cell 2006 Mouse mitochondria proteome --- 591 proteins --- Cell 2003 Mouse cortical neuron proteome --- 3590 proteins --- MCP 2004 Plasma proteome of lymphoma-bearing SJL mice --- 1079 proteins --- J Proteome Res 2005 Bovine proteome database --- 534 proteins --- J Chromatography B 2005 Drosophila phosphoproteome --- 887 phosphopeptides --- Nat Methods 2007 C. elegans proteome --- 1616 proteins --- J Proteome Res 2003 Snake venom proteome --- 42 proteins --- Toxicon 2006 Malaria parasite Plasmodium falciparum proteome --- 2415 & 1289 proteins --- Nature 2002 Yeast proteome --- 2003 proteins --- Genome Biology 2006 Oral microorganisms proteomes --- 330 proteins --- Oral Microbiol Immunol. 2005 Bacillus subtilis phosphoproteome --- 78 phosphorylation sites --- MCP 2007 Rice proteome database --- 11941 proteins --- Nucleic Acids Res 2004 HMDB: the Human Metabolome Database --- >2180 metabolites --- Nucleic Acids Res 2007
Mass spectrometry (MS)-based proteomics has become a powerful technology to map the protein composition of organelles, cell types and tissues. In our department, a large-scale effort to map these proteomes is complemented by the Max-Planck Unified (MAPU) proteome database. MAPU contains several body fluid proteomes; including plasma, urine, and cerebrospinal fluid. Cell lines have been mapped to a depth of several thousand proteins and the red blood cell proteome has also been analyzed in depth. The liver proteome is represented with 3200 proteins. By employing high resolution MS and stringent validation criteria, false positive identification rates in MAPU are lower than 1:1000.Thus MAPU datasets can serve as reference proteomes in biomarker discovery. MAPU contains the peptides identifying each protein, measured masses, scores and intensities and is freely available at http://www.mapuproteome.com using a clickable interface of cell or body parts. Proteome data can be queried across proteomes by protein name, accession number, sequence similarity, peptide sequence and annotation information. More than 4500 mouse and 2500 human proteins have already been identified in at least one proteome. Basic annotation information and links to other public databases are provided in MAPU and we plan to add further analysis tools.
DATA GENERATION AND VALIDATION trypsin or endoproteinase Lys-C 75 mm chromatography column and eluted using a 2 h gradient. LTQ-FTICR MS or LTQ-Orbitrap MS Figure 1. Workflow for protein identification and validation.
Genome Biology 2006, 7:R72 (doi:10.1186/gb-2006-7-8-r72) Results: In this study, we employ state-of-the-art mass spectrometric identification, using both a hybrid linear ion trap-Fourier transform (LTQ-FT) and a linear ion trap-Orbitrap (LTQ-Orbitrap) mass spectrometer, and high confidence identification by two consecutive stages of peptide fragmentation (MS/MS/MS or MS3), to characterize the protein content of the tear fluid. Low microliter amounts of tear fluid samples were either pre-fractionated with one-dimensional SDSPAGE and digested in situ with trypsin, or digested in solution. Five times more proteins were detected after gel electrophoresis compared to in solution digestion (320 versus 63 proteins). Ontology classification revealed that 64 of the identified proteins are proteases or protease inhibitors. Of these, only 24 have previously been described as components of the tear fluid. We also identified 18 anti-oxidant enzymes, which protect the eye from harmful consequences of its exposure to oxygen. Only two proteins with this activity have been previously described in the literature. Conclusion: Interplay between proteases and protease inhibitors, and between oxidative reactions, is an important feature of the ocular environment. Identification of a large set of proteins participating in these reactions may allow discovery of molecular markers of disease conditions of the eye.