Download
1 / 32
390 likes | 662 Views
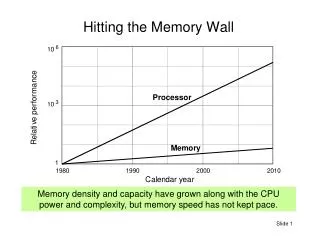
Hitting the Memory Wall. Memory density and capacity have grown along with the CPU power and complexity, but memory speed has not kept pace. The Need for a Memory Hierarchy. The widening speed gap between CPU and main memory Processor operations take of the order of 1 ns

E N D
Hitting the Memory Wall Memory density and capacity have grown along with the CPU power and complexity, but memory speed has not kept pace.
The Need for a Memory Hierarchy The widening speed gap between CPU and main memory Processor operations take of the order of 1 ns Memory access requires 10s or even 100s of ns Memory bandwidth limits the instruction execution rate Each instruction executed involves at least one memory access Hence, a few to 100s of MIPS is the best that can be achieved A fast buffer memory can help bridge the CPU-memory gap The fastest memories are expensive and thus not very large A second (third?) intermediate cache level is thus often used
Typical Levels in a Hierarchical Memory Names and key characteristics of levels in a memory hierarchy.
Main memory: reasonable cost, but slow & small Memory Hierarchy Cache memory: provides illusion of very high speed Virtual memory: provides illusion of very large size Data movement in a memory hierarchy.
The Need for a Cache One level of cache with hit rate h Ceff = hCfast + (1 – h)(Cslow + Cfast) = Cfast + (1 – h)Cslow Cache memories act as intermediaries between the superfast processor and the much slower main memory.
Performance of a Two-Level Cache System Example • CPU with CPIexecution = 1.1 running at clock rate = 500 MHZ • 1.3 memory accesses per instruction. • L1 cache operates at 500 MHZ with a miss rate of 5% • L2 cache operates at 250 MHZ with local miss rate 40%, (T2 = 2 cycles) • Memory access penalty, M = 100 cycles. Find CPI. • CPI = CPIexecution + Mem Stall cycles per instruction • With No Cache, CPI = 1.1 + 1.3 x 100 = 131.1 • With single L1, CPI = 1.1 + 1.3 x .05 x 100 = 7.6 • Mem Stall cycles/instruction = Mem accesses /instruction x Stall cycles / access • Stall cycles per memory access = (1-H1) x H2 x T2 + (1-H1)(1-H2) x M • = .05 x .6 x 2 + .05 x .4 x 100 • = .06 + 2 = 2.06 • Mem Stall cycles/instruction = Mem accesses/instruction x Stall cycles/access • = 2.06 x 1.3 = 2.678 • CPI = 1.1 + 2.678 = 3.778 • Speedup = 7.6/3.778 = 2
Cache Memory Design Parameters (assuming a single cache level) Cache size(in bytes or words). A larger cache can hold more of the program’s useful data but is more costly and likely to be slower. Block or cache-line size (unit of data transfer between cache and main). With a larger cache line, more data is brought in cache with each miss. This can improve the hit rate but also may bring low-utility data in. Placement policy. Determining where an incoming cache line is stored. More flexible policies imply higher hardware cost and may or may not have performance benefits (due to more complex data location). Replacement policy. Determining which of several existing cache blocks (into which a new cache line can be mapped) should be overwritten. Typical policies: choosing a random or the least recently used block. Write policy. Determining if updates to cache words are immediately forwarded to main (write-through) or modified blocks are copied back to main if and when they must be replaced (write-back or copy-back).
What Makes a Cache Work? Temporal locality Spatial locality Assuming no conflict in address mapping, the cache will hold a small program loop in its entirety, leading to fast execution.
Temporal: Accesses to the same address are typically clustered in time Spatial: When a location is accessed, nearby locations tend to be accessed also Temporal and Spatial Localities Addresses From Peter Denning’s CACM paper, July 2005 (Vol. 48, No. 7, pp. 19-24) Time
Desktop, Drawer, and File Cabinet Analogy Once the “working set” is in the drawer, very few trips to the file cabinet are needed. Items on a desktop (register) or in a drawer (cache) are more readily accessible than those in a file cabinet (main memory).
Caching Benefits Related to Amdahl’s Law Example In the drawer & file cabinet analogy, assume a hit rate h in the drawer. Formulate the situation shown in previous figure in terms of Amdahl’s law. Solution Without the drawer, a document is accessed in 30 s. So, fetching 1000 documents, say, would take 30 000 s. The drawer causes a fraction h of the cases to be done 6 times as fast, with access time unchanged for the remaining 1 – h. Speedup is thus 1/(1 – h + h/6) = 6 / (6 – 5h). Improving the drawer access time can increase the speedup factor but as long as the miss rate remains at 1 – h, the speedup can never exceed 1 / (1 – h). Given h = 0.9, for instance, the speedup is 4, with the upper bound being 10 for an extremely short drawer access time. Note: Some would place everything on their desktop, thinking that this yields even greater speedup. This strategy is not recommended!
Compulsory, Capacity, and Conflict Misses Compulsory misses:With on-demand fetching, first access to any item is a miss. Some “compulsory” misses can be avoided by prefetching. Capacity misses: We have to oust some items to make room for others. This leads to misses that are not incurred with an infinitely large cache. Conflict misses: Occasionally, there is free room, or space occupied by useless data, but the mapping/placement scheme forces us to displace useful items to bring in other items. This may lead to misses in future. Given a fixed-size cache, dictated, e.g., by cost factors or availability of space on the processor chip, compulsory and capacity misses are pretty much fixed. Conflict misses, on the other hand, are influenced by the data mapping scheme which is under our control. We study two popular mapping schemes: direct and set-associative.
Direct-Mapped Cache Direct-mapped cache holding 32 words within eight 4-word lines. Each line is associated with a tag and a valid bit.
Accessing a Direct-Mapped Cache Example 1 Show cache addressing for a byte-addressable memory with 32-bit addresses. Cache line W = 16 B. Cache size L = 4096 lines (64 KB). Solution Byte offset in line is log216 = 4 b. Cache line index is log24096 = 12 b. This leaves 32 – 12 – 4 = 16 b for the tag. Components of the 32-bit address in an example direct-mapped cache with byte addressing.
Example 2 1 KB Direct Mapped Cache, 32B blocks • For a 2N byte cache: • The uppermost (32 - N) bits are always the Cache Tag • The lowest M bits are the Byte Select (Block Size = 2M) 31 9 4 0 Cache Tag Example: 0x50 Cache Index Byte Select Ex: 0x01 Ex: 0x00 Stored as part of the cache “state” Valid Bit Cache Tag Cache Data : Byte 31 Byte 1 Byte 0 0 : 0x50 Byte 63 Byte 33 Byte 32 1 2 3 : : : : Byte 1023 Byte 992 31
Set-Associative Cache Two-way set-associative cache holding 32 words of data within 4-word lines and 2-line sets.
Accessing a Set-Associative Cache Example 1 Show cache addressing scheme for a byte-addressable memory with 32-bit addresses. Cache line width 2W = 16 B. Set size 2S = 2 lines. Cache size 2L = 4096 lines (64 KB). Solution Byte offset in line is log216=4b. Cache set index is (log24096/2)=11b. This leaves 32 – 11 – 4 = 17 b for the tag. Components of the 32-bit address in an example two-way set-associative cache.
Cache Data Cache Tag Valid Cache Block 0 : : : Compare Example 2 Two-way Set Associative Cache • N-way set associative: N entries for each Cache Index • N direct mapped caches operates in parallel (N typically 2 to 4) • Example: Two-way set associative cache • Cache Index selects a “set” from the cache • The two tags in the set are compared in parallel • Data is selected based on the tag result Cache Index Valid Cache Tag Cache Data Cache Block 0 : : : Adr Tag Compare 1 0 Mux Sel1 Sel0 OR Cache Block Hit
Disadvantage of Set Associative Cache • N-way Set Associative Cache v. Direct Mapped Cache: • N comparators vs. 1 • Extra MUX delay for the data • Data comes AFTER Hit/Miss • In a direct mapped cache, Cache Block is available BEFORE Hit/Miss: • Possible to assume a hit and continue. Recover later if miss. Advantage of Set Associative Cache • Improves cache performance by reducing conflict misses • In practice, degree of associativity is often kept at 4 or 8
Effect of Associativity on Cache Performance Performance improvement of caches with increased associativity.
Cache Processor DRAM Write Buffer Cache Write Strategies Write Though: Data is written to both the cache block and to a block of main memory. • The lower level always has the most updated data; an important feature for I/O and multiprocessing. • Easier to implement than write back. • A write buffer is often used to reduce CPU write stall while data is written to memory.
Cache Write Strategies cont. Write back: Data is written or updated only to the cache block. The modified or dirty cache block is written to main memory when it’s being replaced from cache. • Writes occur at the speed of cache • A status bit called a dirty bit, is used to indicate whether the block was modified while in cache; if not the block is not written to main memory. • Uses less memory bandwidth than write through.
Cache and Main Memory Split cache: separate instruction and data caches (L1) Unified cache: holds instructions and data (L1, L2, L3) Harvard architecture: separate instruction and data memories von Neumann architecture: one memory for instructions and data
Cache and Main Memory cont. (16KB instruction cache + 16KB data cache) vs. 32KB unified cache Hit cycle: 1, Miss cycle: 50, 75% instruction access 16KB I&D: instruction miss rate=0.64%, data miss rate=6.47% 32KB: miss rate = 1.99% Average memory access time = % instructions × (read hit time + read miss rate × miss penalty) + % data × (write hit time + write miss rate × miss penalty) Split= 75% × (1 + 0.64% × 50) + 25% × (1 + 6.47% × 50) = 2.05 Unified= 75% × (1 + 1.99 × 50) + 25% × (1 + 1* + 1.99% × 50) = 2.24 *: 1 extra clock cycle since there is only one cache port to satisfy two simultaneous requests
Improving Cache Performance For a given cache size, the following design issues and tradeoffs exist: Line width (2W). Too small a value for W causes a lot of maim memory accesses; too large a value increases the miss penalty and may tie up cache space with low-utility items that are replaced before being used. Set size or associativity(2S). Direct mapping (S = 0) is simple and fast; greater associativity leads to more complexity, and thus slower access, but tends to reduce conflict misses. Line replacement policy. Usually LRU (least recently used) algorithm or some approximation thereof; not an issue for direct-mapped caches. Somewhat surprisingly, random selection works quite well in practice. Write policy. Write through, write back
2:1 cache rule of thumb A direct-mapped cache of size N has about the same miss rate as a 2-way set-associative cache of size N/2. E.g. Ref. p. 424 fig. 5.14: miss rate 8 KB direct-mapped (0.068%) = 4 KB 2-way set associative (0.076%) 16 KB (0.049%) = 8 KB (0.049%) 32 KB (0.042%) = 16 KB (0.041%) 64 KB (0.037%) = 32 KB (0.038%) Caches larger than 128 KB do not prove the rule.
90/10 locality rule A program executes about 90% its instructions in 10% of its code
Four classic memory hierarchy questions • Where can a block be placed in the upper level? (block placement): direct mapped, set-associative.. • How is a block found if it is in the upper level? (block identification): tag, index, offset • Which block should be replaced on a miss? (block replacement): Random, LRU, FIFO.. • What happens on a write? (write strategy): write through, write back
Reducing cache miss penaltyliterature review 1 • Multilevel caches • Critical word first and early restart • Giving priority to read misses over writes • Merging write buffer • Victim caches • ..
Reducing cache miss rateliterature review 2 • Larger block size • Larger caches • Higher associativity • Way prediction and pseudoassociative caches • Compiler optimizations • ..
Reducing cache miss penalty or miss rate via parallelismliterature review 3 • Nonblocking caches • H/W prefetching of instructions and data • Compiler controlled prefetching • ..
Reducing hit timeliterature review 4 • Small and simple caches • Avoiding address translation during indexing of the cache • Pipelined cache access • Trace caches • ..



















