Download

1 / 44
440 likes | 549 Views
Organizing the Last Line of Defense before hitting the Memory Wall for Chip-Multiprocessors (CMPs). C. Liu, A. Sivasubramaniam , M. Kandemir The Pennsylvania State University anand@cse.psu.edu. Outline. CMPs and L2 organization Shared Processor-based Split L2

E N D
Organizing the Last Line of Defense before hitting the Memory Wall for Chip-Multiprocessors (CMPs) C. Liu, A. Sivasubramaniam, M. Kandemir The Pennsylvania State University anand@cse.psu.edu
Outline • CMPs and L2 organization • Shared Processor-based Split L2 • Evaluation using SpecOMP/Specjbb • Summary of Results
Why CMPs? • Can exploit coarser granularity of parallelism • Better use of anticipated billion transistor designs • Multiple and simpler cores • Commercial and research prototypes • Sun MAJC • Piranha • IBM Power 4/5 • Stanford Hydra • ….
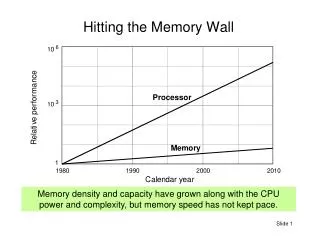
Higher pressure on memory system • Multiple active threads => larger working set • Solution? • Bigger Cache. • Faster interconnect. • What if we have to go off-chip? • The cores need to share the limited pins. • Impact of off-chip accesses may be much worse than incurring a few extra cycles on-chip • Needs a close scrutiny of on-chip caches.
On-chip Cache Hierarchy • Assume 2 levels • L1 (I/D) is private • What about L2? • L2 is the last line of defense before going off-chip, and is the focus of this paper.
L2 $ L2 $ L2 $ L2 $ L2 $ L2 $ I N T E R C O N N E C T Private (P) L2 I$ D$ I$ D$ L1 L1 Coherence Protocol Advantages: Less interconnect traffic Insulates L2 units Disadvantages: Duplication Load imbalance Offchip Memory
I N T E R C O N N E C T Shared-Interleaved (SI) L2 Coherence Protocol L1 I$ D$ I$ D$ L2 Disadvantages: Interconnect traffic Interference between cores Advantages: No duplication Balance the load
Desirables • Approach the behavior of private L2s, when the sharing is not significant • Approach the behavior of private L2 when load is balanced or when there is interference • Approach behavior of shared L2 when there is significant sharing • Approach behavior of shared L2 when demands are uneven.
I$ D$ I$ D$ I N T E R C O N N E C T $ $ $ $ $ $ $ $ $ $ $ $ Shared Processor-based Split L2 L1 Table and Split Select L2 Processors/cores are allocated L2 splits
Lookup • Look up all splits allocated to requesting core simultaneously. • If not found, then look at all other splits (extra latency). • If found, move block over to one of its splits (chosen randomly), and removing it from the other split. • Else, go off-chip and place block in one of its splits (chosen randomly).
Note … • Note, a core cannot place blocks that evict blocks useful to another (as in Private case) • A core can look at (shared) blocks of other cores – at a slightly higher cost without being as high as off-chip accesses (as in Shared case). • There is at most 1 copy of a block in L2.
I N T E R C O N N E C T Shared Split Uniform (SSU) I$ D$ I$ D$ L1 Table and Split Select $ $ $ $ $ $ $ $ $ $ $ $ L2
I N T E R C O N N E C T Shared Split Non-Uniform (SSN) I$ D$ I$ D$ L1 Table and Split Select $ $ $ $ $ $ $ $ $ $ $ $ L2
$ $ $ $ $ $ $ $ $ $ Split Table P0 P1 P2 P3
Evaluation • Using Simics complete system simulator • Benchmarks: SpecOMP2000 + Specjbb • Reference dataset used • Several billion instructions were simulated. • A bus interconnect was simulated with MESI.
SSN Terminology • With a total L2 of 2MB (16 splits of 128K each) to be allocated to 8 cores, SSN-152 refers to • 512K (4 splits) allocated to 1 CPU • 256K (2 splits) allocated to each of 5 CPUs • 128K (1 split) allocated to each of 2 CPUs • Determining how much to allocate to each CPU (and when) – postpone for future work. • Here, we use a profile based approach based on L2 demands.
Application behavior • Intra-application heterogeneity • Spatial: (among CPUs) allocate non-uniform splits to different CPUs. • Temporal: (for each CPU)change the number of splits allocated to a CPU at different points of time. • Inter-application heterogeneity • Different applications running at same time can have different L2 demands.
Definition • SHF (Spatial Heterogeneity Factor) • THF (Temporal Heterogeneity Factor)
Summary of Results • When P does better than S (e.g. apsi), SSU/SSN does as well (if not better) as P. • When S does better than P (e.g. swim, mgrid, specjbb), SSU/SSN does as well (if not better) as S. • In nearly all cases (except applu), some configuration of SSU/SSN does the best. • On the average we get over 11% improvement in IPC over the best S/P configuration(s).
Inter-application Heterogenity • Different applications have different L2 demands • These applications could even be running concurrently on different CPUs.
Inter-application results • ammp+apsi, low+high. • ammp+fma3d, both low • swim+apsi, both high, imbalanced + balanced. • swim+mgrid,both high, imbalanced + imbalanced
Inter-application: ammp+apsi • SSN-152 • 1.25MB dynamically allocated to apsi, 0.75MB to ammp. • Graph shows the rough 5:3 allocation. • Better overall IPC value. Low miss rate for apsi and not affecting the miss rate of ammp.
Concluding Remarks • Shared Processor-based Split L2 is a flexible way of approaching the behavior of shared or private L2 (based on what is preferable) • It accommodates spatial and temporal heterogeneity in L2 demands both within an application and across applications. • Becomes even more important with higher off-chip accesses.
Future Work • How to configure the split sizes – statically, dynamically and a combination of the two?
Meaning • Capture the heterogeneity between CPUs (spatial) or over the epochs (temporal) of the load imposed on the L2 structure. • Weighted by L1 accesses reflect the effect on the overall IPC. • If the overall access are low, there is not going to be a significant impact on the IPC even though the standard deviation is high.
In swim, mgrid, specjbb with high L1 miss rate means higher pressure on L2,which results significant IPC improvement(30.9% to 42.5%) Results Except applu, shared splitL2 perform the best.
Why private L2 does better in some? • L2 performance: • The degree of sharing • The imbalance of load imposed on L2 • For applu and swim+apsi, • Only 12% of the blocks are shared at any time, mainly shared between 2 CPUs. • Not much spatial/temporal heterogeneity.
Why we use IPC instead of the execution time? • We could not finish any of the benchmark, since we are using the “reference” dataset. • Another possible indicator is the number of iterations executed of certain loop (for example, the dominating loop) for unit amount of time. • We did this and find the direct correlation between the IPC value and the number of iterations.
Closer look: specjbb • SSU is over 31% better than the private L2. • Direct correlation between the L2 misses and the IPC values. • P never exceeds 2.5, while SSU sometimes push over 3.0
Sensitivity: Larger L2 • 2MB -> 4MB -> 8MB • Miss rates go down, difference arising from miss rate diminish. ‘swim’ still get considerable savings. • If application size keep growing up, the split shared L2 is still going to help. • More splits of L2 -> finer granularity -> could help SSN.
Sensitivity: Longer memory access 120 cycles -> 240 cyclesBenefits are amplified