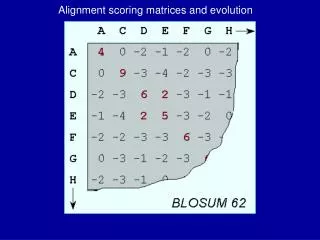
Download
1 / 22
220 likes | 235 Views
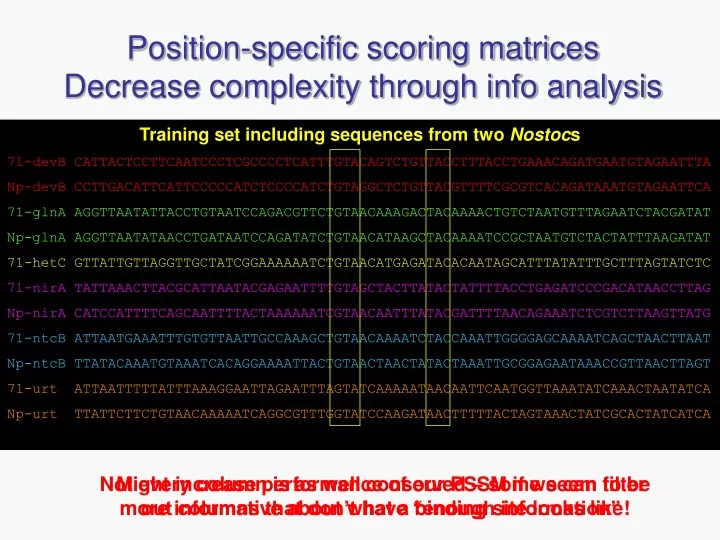
Position-specific scoring matrices Decrease complexity through info analysis. Training set including sequences from two Nostoc s 71-devB CATTACTCCTTCAATCCCTCGCCCCTCATTTGTACAGTCTGTTACCTTTACCTGAAACAGATGAATGTAGAATTTA

E N D
Position-specific scoring matricesDecrease complexity through info analysis Training set including sequences from two Nostocs 71-devB CATTACTCCTTCAATCCCTCGCCCCTCATTTGTACAGTCTGTTACCTTTACCTGAAACAGATGAATGTAGAATTTA Np-devB CCTTGACATTCATTCCCCCATCTCCCCATCTGTAGGCTCTGTTACGTTTTCGCGTCACAGATAAATGTAGAATTCA 71-glnA AGGTTAATATTACCTGTAATCCAGACGTTCTGTAACAAAGACTACAAAACTGTCTAATGTTTAGAATCTACGATAT Np-glnA AGGTTAATATAACCTGATAATCCAGATATCTGTAACATAAGCTACAAAATCCGCTAATGTCTACTATTTAAGATAT 71-hetC GTTATTGTTAGGTTGCTATCGGAAAAAATCTGTAACATGAGATACACAATAGCATTTATATTTGCTTTAGTATCTC 71-nirA TATTAAACTTACGCATTAATACGAGAATTTTGTAGCTACTTATACTATTTTACCTGAGATCCCGACATAACCTTAG Np-nirA CATCCATTTTCAGCAATTTTACTAAAAAATCGTAACAATTTATACGATTTTAACAGAAATCTCGTCTTAAGTTATG 71-ntcB ATTAATGAAATTTGTGTTAATTGCCAAAGCTGTAACAAAATCTACCAAATTGGGGAGCAAAATCAGCTAACTTAAT Np-ntcB TTATACAAATGTAAATCACAGGAAAATTACTGTAACTAACTATACTAAATTGCGGAGAATAAACCGTTAACTTAGT 71-urt ATTAATTTTTATTTAAAGGAATTAGAATTTAGTATCAAAAATAACAATTCAATGGTTAAATATCAAACTAATATCA Np-urt TTATTCTTCTGTAACAAAAATCAGGCGTTTGGTATCCAAGATAACTTTTTACTAGTAAACTATCGCACTATCATCA Not every column is as well conserved – some seem to be more informative about what a binding site looks like! Might increase performance of our PSSM ifwe can filter out columns that don’t have “enough information”
Position-specific scoring matricesDecrease complexity through info analysis Uncertainty (Hc) = -S[piclog2(pic)] Confusing!!!
Digression on information theory Uncertaintywhen all outcomes are equally probable Pretend we have a machine that spits out an infinitely long string of nucleotides But that each one is EQUALLY LIKELY to occur: Pretend we have a machine that spits out an infinitely long string of nucleotides: A G A T G A C T C … How uncertain are we about the outcome BEFORE we see each new character produced by the machine? Intuitively, this uncertainty will depend on how many possibilities exist
Digression on information theory Quantifying uncertainty when outcomes are equally probable One way to quantify uncertainty is to ask: “What is the minimum number of questions required to remove all ambiguity about the outcome?” If the possibilities are: A or G or C or T How many yes/no questions do we need to ask?
AGCT M = 4(Alphabet size) AG CT Number of decisions depends on the height of the decision tree A G C T Digression on information theory Quantifying uncertainty when outcomes are equally probable H = log2(M) With M = 4 we are uncertain by log2(4) = 2 bits before each new symbol is made by our machine
Digression on information theory Uncertaintywhen all outcomes are equally probable After we have received a new symbol from our machine we are less uncertain Intuitively, when we become less uncertain, it means we have gained information Information = Hbefore - Hafter Information = uncertaintybefore - uncertaintyafter Note that only in the special case where no uncertainty remains after (Hafter = 0) does information = Hbefore In the real world this never happens because of noise in the system!!
Fine, but where did we get H = SPi log2Pi ? M i =1 Digression on information theory Necessary when outcomes are not equally probable!
Digression on information theory Uncertaintywith unequal probabilities Now our machine produces a string of symbols, but some are more likely to occur than others: PA = 0.6 PG = 0.1 PC = 0.1 PT = 0.2
Digression on information theory Uncertaintywith unequal probabilities Now our machine produces a string of symbols, but we know that some are more likely to occur than others: A A A A A … T T G C Now how uncertain are we about the outcome BEFORE we see each new character? Are we more or less surprised when we see an “A” or a “C”?
A A A A A T T G C Digression on information theory Uncertaintywith unequal probabilities Now our machine produces a string of symbols, but we know that some are more likely to occur than others: … Do you agree that we are less surprised to see an “A” than we are to see a “G”? Do you think that the output of our new machine is more or less uncertain?
Digression on information theory What about when outcomes are not equally probable? log2M = -log2M-1 = - log2(1/M) = - log2(P) P = 1/M = probability of a symbol appearing
M SPi = 1 M = 4 i =1 Remember that the probabilities of all possible symbols must sum to 1! Digression on information theory What about when outcomes are not equally probable? PA = 0.6 PG = 0.1 PC = 0.1 PT = 0.2
} Digression on information theory How surprised are we to see a given symbol? ui = - log2(Pi) (where Pi = probability of ith symbol) UA = -log2(0.6) = 0.7 UG = -log2(0.1) = 3.3 UC = -log2(0.1) = 3.3 UT = -log2(0.2) = 2.3 Ui is therefore called the surprisal for symbol i
Digression on information theory What does the surprisal for a symbol have to do with uncertainty? ui = - log2(Pi) the “surprisal” Uncertainty is the average surprisal for the infinite string of symbols produced by our machine
M N = SNi Niis equal to the number of times each symbol occurred in a string of length N i =1 For example, for the string “AAGTAACGA” NA = 5 NG = 2 NC = 1 NT = 1 N = 9 Digression on information theory Let’s first imagine that our machine only produces a finite string of N symbols
M M SNiui SNiui M Ni S i =1 i =1 ui M N SNi N i =1 i =1 Digression on information theory For every Ni, there is a corresponding surprisal ui therefore the average surprisal for N symbols will be:
Ni N M S Pi ui i =1 Digression on information theory For every Ni, there is a corresponding surprisal ui therefore the average surprisal for N symbols will be: M S ui i =1 Remember that Pi is simply the probability of generating the ith symbol! But wait! We also already defined Ui !!
M M S S Pi Pi ui log2(Pi) i =1 i =1 Digression on information theory ui = - log2(Pi) Therefore: H - Congratulations! This is Claude Shannon’s famous formula defining uncertainty when the probability of each symbol is unequal!
M S - (1/M log21/M) 1 i =1 - (1/M M log21/M) M log2 Digression on information theory How does it reduce assuming equiprobable symbols? Heq M S - (1/M) log2(1/M) i =1 Uncertainty is largest when all symbols are equally probable!
M H S - Pi log2(Pi) i =1 Digression on information theory Uncertainty when M = 2 Uncertainty is largest when all symbols are equally probable!
M - S Pi log2(Pi) log2 M i =1 Digression on information theory OK, but how much information is present in each column? Information (R) = Hbefore - Hafter Now before and after refers to before and after we examined the contents of a column
Digression on information theory Sequence logos graphically display how Much information is present in each column http://weblogo.berkeley.edu/