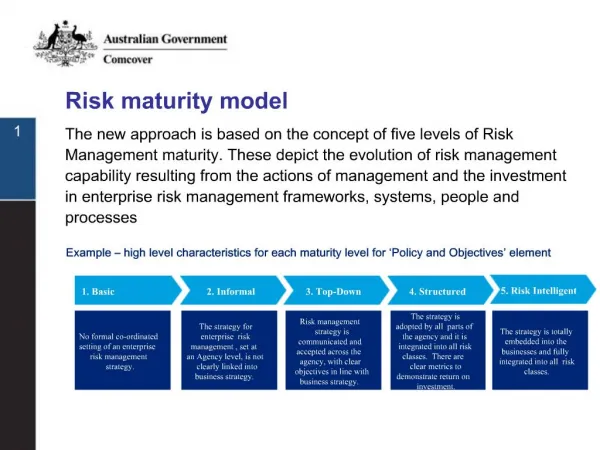
Download

1 / 44
440 likes | 634 Views
Model Risk of Correlation Products. PRESENTED TO: Risk Magazine's Training Course: Advanced Correlation Modelling & Analysis BY: Martin Goldberg, Director martin.goldberg@citigroup.com Head of Model Validation Risk Architecture Citigroup

E N D
Model Risk of Correlation Products PRESENTED TO: Risk Magazine's Training Course: Advanced Correlation Modelling & Analysis BY: Martin Goldberg, Director martin.goldberg@citigroup.com Head of Model Validation Risk Architecture Citigroup New York, New York DATE: May 11, 2006 PLACE: New York City
Outline • How does your model perform • Testing copula density and marginals separately • Estimating correlations and volatility - implied vs. historical • Stress Events, Extreme Value Theory, conditional dependencies, and VaR • Summary
Outline • How does your model perform • Testing copula density and marginals separately • Estimating correlations and volatility - implied vs. historical • Stress Events, Extreme Value Theory, conditional dependencies, and VaR • Summary
Performance metrics • Most models can calibrate to the price of some standard instrument at inception. What distinguishes good from bad is the performance over time or over changing markets • Backtesting • Ex Ante Profit Attribution Analysis • Paper Trading • Hypothetical Paper Trades • Stress Tests Past Present Future
Sources of Error • There are many possible sources of model risk. Some that I will discuss today are: • Calibration error - the model does not fit the market, either because • It is not flexible enough • It is too flexible and you are calibrating to noise • Input error - the data you are fitting your model with are wrong or come from a different market • Regime shift - the model used to work well, but the market has changed and the model can’t handle the changes. • Wild West error - there are not enough data to distinguish a good model from a bad one
Not Flexible Enough - Simplistic models • No correlation skew as an analogy to B_S models without vol skew • CAPM one-factor models with no correlation between alphas • Multiplying VaR by and neglecting GARCH-type effects • Confusing correlation with contagion, or assuming constant correlation
Too Flexible - Careful Fit to Noise • In a variance-covariance Value-at-Risk calculation, or in a portfolio optimization, a key component is a correlation matrix. • A matrix calculated from a year of daily returns has rank at most 252, no matter how many timeseries you put in. • Random Matrix Theory [3], [4] describes the principal components you would get if the timeseries were pure noise. How does it compare to the eigenvalues of, say, the S&P 500 correlation matrix? • About 94% of the spectrum is random, leaving the meaningful signal a rank of about 30. • Moral: Whenever possible, use a control group of synthetic data of known properties to separate out real effects from artefacts of the modeling process.
Calibrating to wrong data • First example • Hedge fund managers and private equity funds are required to post monthly estimates of their portfolio value. • The estimates are noisy due to illiquidity • The managers, either unconsciously or deliberately, “smooth” the earnings by shading their estimates. • Correlations due to similar smoothing, or from market moves? • Next example • Historical correlations for trading in liquid markets should probably use daily timeseries • For buy-and-hold, probably less frequent, like monthly or quarterly. • Related issues in estimation of default correlation from equity data. • Spectral analysis, for example [5].
Regime Shifts • Abrupt jumps should be handled differently than gradual non-stationarity. • Key questions for jumps: • Is this really a jump and not just a fat tailed diffusion? • Is the jump a one-time regime shift invalidating all prior history, or is it a feature of a jumpy market? • Is there a news story explaining the jump? • Was there a knock-on effect (possibly contagion?) in other markets?
Illiquid and New Markets and Cowboys • Here you need to use heuristics and trader intuition, since there isn’t anything else. • A wide enough bid-ask spread covers all sins. • This is not exactly model risk since there is no model as such. • Anything worth doing is worth doing badly at first.
Outline • How does your model perform • Testing copula density and marginals separately • Estimating correlations and volatility - implied vs. historical • Stress Events, Extreme Value Theory, conditional dependencies, and VaR • Summary
Quick Introduction to Copula Theory • Copula theory is a generalization of the concept of correlation. • A copula is expressed as a quantile of the distribution in N dimensions. • A copula in one dimension is a tautology - x% of the data are at or below the x% quantile. • The one-dimensional copula density, also called a marginal, is a uniform distribution from 0 to 1, with the copula density of each point being its quantile in the data series. • The copula is related to the copula density by
Example • In two dimensions, the copula density of changes in USD Libor and JPY Libor looks like • Note that it is not actually continuous, since some days are unchanged.
Copulas again • The Copula for this data is at each point (x,y) the fraction of the data where X<x and Y<y. • For a good introduction to copulas see [9].
Marginal Probability Distributions • The first step in constructing a copula is to transform all the marginals to uniform densities. • Not everything is Gaussian. • Alternative distributions, which can be fitted to data and give better results usually than a Gaussian or lognormal, are Student-t, CEV, Madan’s VG, and my favorite for exploratory data analysis, the Tukey gXh distribution [15],[16] • Where g controls skew and h controls smile. This nests Gaussian, lognormal, Student-t, and even Cauchy distributions, and is more tractable than CEV or VG. • Later I will show what can go wrong if the marginals are mis-specified. • Art form to trade-off between accuracy/flexibility and tractability/speed.
3500 3000 2500 2000 1500 1000 500 0 -5 -4 -3 -2 -1 0 1 2 3 4 5 Fitting the Tukey gXh distribution to single-B bond spreads Normal Rescaled gXh Absolute change in yield (%) Comparison of normal, rescaled normal and (gXh) distribution fits to 10 day changes in idiosyncratic spread for single-B bonds using EJV data. Rescaled Cumulative Normal fits at 99th percentile.
Families of Copulas • There are many “families” of copulas described in the literature [7]. • Note that most of the literature stops at 2 dimensions; more than that is much harder to work out the math, and there are constraints. • Some popular families of copulas are:
Properties of Copulas • Any multivariate density can be expressed as a copula connecting marginal densities. • The copula and the marginals are completely separate - any marginal pdf’s can be connected by any valid copula. • For distributions with continuous marginals the copula is unique. • The average of two copulas may not be a copula, but the average of two copula densities is a copula density. • A Gaussian copula connecting two Gaussian marginals is a Pearson (ordinary) correlation. • Pearson Correlation is not a good measure if the copula is not Gaussian or any marginal is not Gaussian. • The rank correlation is a non-parametric copula equivalent, for any distributions, of Pearson correlations for multivariate normals. Spearman rho is easier than Kendall Tau. • Spearman rank correlation in 2-D is the Pearson correlation between ranks of the entries of the 2 data series. • Easy to compute in Excel using the RANK() function.
Tail Dependence • The Upper Tail Dependence is defined for any copula density c(U1,U2) as • By flipping the < to > and replacing the u with 1-u, we can get a Lower Tail Dependence • More generally, in N dimensions, the hypercube has 2N corners, so we can define 2N Tail Dependences • Tail Dependence is my preferred definition of contagion. • A Gaussian Copula has zero tail dependence - a very extreme move in one dimension is never simultaneous with a similarly big move in any other dimension.
Fiendish Copula Density • Upper and lower tail dependence of 1; middle “local dependence” -1 • The rank correlation is constructed to be exactly zero. • It is more pathological than what you will ever actually find, but it is a good stress test. • You can find funnel-shaped and galaxy-shaped copula densities in real data, but in a less exaggerated form than below. Extreme Funnel Extreme Galaxy Gaussian Copula Density
Fiendish Copula • It is not immediately obvious why this is so fiendish. • Although all the theory is done using the cumulative distributions, the copula densities are more informative and make prettier pictures. • Caveat: Copula theory is not nearly as well developed for more than 2 dimensions. The standard cheat scheme used in Credit Derivatives is to assume every underlying looks like all the others, which means all 2-dimensional slices look alike.
Distinguishing Correlation from ContagionNon-Linear Correlation Contagion can be defined as a significant difference in the association between large moves (tail events) relative to the association between smaller moves (ordinary days). This is Tail Dependence. As an example study, here is a test of contagious increases in Pearson correlation between Brent oil and kerosene, using 215 pairs of weekly historical spot data. Since you always should use a control, I have also used 215 pairs of random numbers with the same correlation of 63%.
Tonsured density Null hypothesis is an elliptical distribution, so eliminate center of distribution where
Tail Dependence for Brent and Kerosene Upper tail dependence, but not lower, is found in the US Treasury curve[14]. Barry Schachter’s gloriamundi.org website has many other such tail dependence papers.
Another Parametric Correlation Curve • Bjerve and Doksum[1] have a correlation curve, which does not generalize well to n>2 data series. • Regress Y against X, then the local variance • The local regression slope • And the global standard deviation of the X variable • And use these to get a local correlation • Note this is not symmetric in X and Y
Causes of Non-constant Correlation • Use of a standard Pearson correlation assumes multivariate normal distributions. • The changes in correlation could be due to contagion, or just to skewed or fat-tailed underlyings. • Kurtosis alone still has elliptical distribution and does not have much effect on correlation. • Copula theory - not well developed for n>2. For example, a Student-t copula has the same degrees of freedom for every pair of variables. • If two Gaussian marginals are associated by a Gaussian copula, the rank-correlation is constant, and equal to the Pearson correlation. • Copulas can be made flexible enough to represent arbitrarily screwy associations. • Mathematical theories use the copula, which is the cumulative function; easier to visualize copula density.
Problems with Pearson Correlation High leverage data points
Picking the right copula • Fitting the data exactly with a copula density of delta functions at each data point is valid, but not very useful. Trade-off between smooth function and accuracy [2]. • Hurd et al[10] use an expansion in Bernstein copulas for the copula between EUR/GBP and USD/GBP implied by the volly smile surfaces of traded options. FX is special because triangular arbitrage gives an implied correlation. On some days, the copula is bimodal and they need 11 terms to get the extra hump qualitatively right. Is this noise or a feature? • Malvergne and Sornette[11] find that most of the time, a Gaussian copula works for most currency pairs and most pairs of stocks, but not for pairs of commodities. • However, if your portfolio is actively traded or has optionality, this may not be the case. Boyson et al[12] find contagion between hedge fund styles, so a fund-of-funds is not well-modeled by a Gaussian copula. • Some other caveats are found in [13], where they show how hard it is to find the best parametric copula to fit to real data.
Is stock market contagion an urban legend? • On the previous slide I mentioned[11] that a Gaussian copula works well for equities. • Does this contradict the received wisdom that correlations between stocks goes to one in a crash? • One example of the studies of correlation in a crash is [17]. Note that they always use ordinary Pearson correlations. • In contrast, [18] notes that a constant association with a fat-tailed distribution leads to the appearance of changing correlation. • This is an example of invoking higher-order effects to explain illusory phenomena caused by not fully capturing the lower order effects. In quantum chemistry, this is called lack of basis set saturation. • A similar example is the simpler versions of jump-diffusion models, where they pretend the diffusion part is lognormal or Gaussian, pretend that the drift term is linear, and then invoke jumps to explain the rest. Jumps in financial time series are real, but they are always accompanied by headlines in the Wall Street Journal or Financial Times. If your model has more jumps than headlines, fix the diffusion part.
Outline • How does your model perform • Testing copula density and marginals separately • Estimating correlations and volatility - implied vs. historical • Stress Events, Extreme Value Theory, conditional dependencies, and VaR • Summary
Nonstationary time series • Historical estimate is always a convolution with a filter. • Square wave - equally weighted data more recent than - • RiskMetrics exponential decay • Whatever other filter you like, or better, one suggested by the data • Greg Sullivan[6] describes an optimal estimator for the length of the square wave filter, which could be easily modified to find, for example, the optimal exponent for the RiskMetrics method. • For a stationary time series, the error in the correlation estimate is • In the absence of any obvious regime shift, the non-stationarity can be modeled as a linear drift
Nonstationary time series 2 • Then the optimum observation period, dictated by the data itself, is • This represents the trade-off between longer periods reducing statistical noise, and shorter periods being closer to stationary. The paper[6] has detailed instructions for finding this optimum point. • Of course there are data series where there is a genuine regime shift, like the start of a new equity listing due to IPO, and there the cutoff is obvious.
Changing the Skew with Added Jumps – fake data with correlation .5
Rank Correlations • In the absence of jumps, any amount of skewness or kurtosis leaves the rank correlation between time series unchanged. • This is one of the best reasons to use copula theory. • Rank correlations are very little extra effort compared to Pearson correlations, and do not assume Gaussian marginals. • Enhancing your model of the univariate marginals does not require redoing the copula / rank correlation matrix. • Non-Gaussian copulas can capture tail dependence and not confuse it with the tail shapes.
Outline • How does your model perform • Testing copula density and marginals separately • Estimating correlations and volatility - implied vs. historical • Stress Events, Extreme Value Theory, conditional dependencies, and VaR • Summary
Extreme Value Theory • EVT says that, for quantiles outside the observation data set, the marginal pdf can take only 3 different shapes: • Gaussian decay • Abrupt cutoff (Gumbel) • Power-law decay (Frechet) • Most financial time series have Frechet tails. Estimate the exponent, and fit it with the bulk of the distribution, and you are done. You can use this to predict the 99%ile (VaR), the 99.9%ile (Basel 2), or the 99.97%ile (economic capital for a AA firm.) The result will differ from scaling up using the assumption of a multivariate normal density. • What copula to use? A quick series of tests include tail dependences, stability over the sample period, and the X test.
X test for copula skew • By construction, half the copula density is on the left half (0-.5), and half is on the lower half (0-.5). • You can test for quadrant dependence by seeing how far off the density is from ¼ in each quadrant, but that may not be very informative – this is just a crude measure of rank correlation. • Far more informative a test is (in a 2D copula density) drawing an X from upper left to lower right and upper right to lower left. If the density is elliptical, all 4 triangles will be mirrored images of each other. • Test comparing each of the 4 to the average of all 4. • Extend to quartets of diamond-shaped sub-regions? • This X-test is not in the literature, as far as I know, but it is referred to in [10]. • The extension of the X test to N dimensions involves 2N diagonals.
Summary • Not everything is multivariate (log-)Gaussian. • Rank correlations are a better and more flexible measure than correlations. • Copula theory is useful. • Tradeoffs between accuracy and speed, complexity vs ease of use. • Liquidity of market important in selecting model. • Get the simpler features right before invoking higher-order effects. • Keep up with the literature – there are lots of good ideas out there. • Disclaimer: This talk represents my personal views and is not intended to be in agreement with anything Citigroup says or does.
References • Bjerve, S. and Doksum, K.A. (1993). Correlation curves: measures of association as functions of covariates. Ann. of Statist., 21, 890-902. • http://xxx.lanl.gov/abs/physics?papernum=0406023 Maximum Entropy Multivariate Density Estimation: An exact goodness-of-fit approach • http://arxiv.org/abs/cond-mat?papernum=0111503 Noisy Covariance Matrices • http://arxiv.org/abs/cond-mat?papernum=0205119 Noisy Covariance Matrices II • http://www.ofce.sciences-po.fr/pdf/dtravail/wp2003-07.pdf and http://ideas.repec.org/p/fce/doctra/0307.html, Iacobucci, Spectral Analysis for Economic Time Series • Greg Sullivan, Risk 8(8), August 1995, page 36, Correlation Counts • H. Joe, “Multivariate Models and Dependence Concepts” Chapman&Hall, 1997 • http://greywww.kub.nl:2080/greyfiles/center/2003/doc/122.pdf Multivariate Option Pricing Using Dynamic Copula Models by R.W.J. van den Goorbergh, C. Genest, B.J.M. Werker
References • http://gro.creditlyonnais.fr/content/wp/copula-survey.pdf Copulas for Finance - A Reading Guide and Some Applications by Bouyé, Durrleman, Nikeghbali, Riboulet, Roncalli • http://www2.warwick.ac.uk/fac/soc/wbs/research/wfri/rsrchcentres/ferc/wrkingpaprseries/wp05-20.pdf Using Copulas to Construct Bivariate Foreign Exchange Distributions with an Application to the Sterling Exchange Rate Index by Matthew Hurd, Mark Salmon, Christoph Schleicher • http://arxiv.org/abs/cond-mat?papernum=0111310 Testing the Gaussian Copula Hypothesis for Financial Assets Dependences Authors: Y. Malevergne , D. Sornette • http://www.nber.org/papers/w12090 Is There Hedge fund contagion? Authors: N. Boyson, C. Stahel, R. Stulz • http://www.crest.fr/pageperso/fermanian/pitfalls_copula.pdf Some Statistical pitfalls in Copula Modeling for Financial Applications Authors J Fermanian, O Scaillet • http://gloriamundi.org/picsresources/mjasnw.pdf Nonlinear Term Structure Dependence by M Junker, A Szimayer, N Wagner
References • http://fic.wharton.upenn.edu/fic/papers/02/0225.pdf • http://fic.wharton.upenn.edu/fic/papers/02/0226.pdf • http://arxiv.org/abs/cond-mat?papernum=0302546 Dynamics of market correlations: Taxonomy and portfolio analysis Authors: J.-P. Onnela, A. Chakraborti, K. Kaski, J. Kertesz, A. Kanto • http://ideas.repec.org/p/cam/camdae/0319.html. "Changing Correlation and Portfolio Diversification Failure in the Presence of Large Market Losses by Sancetta, Satchell