Download
1 / 1
10 likes | 159 Views
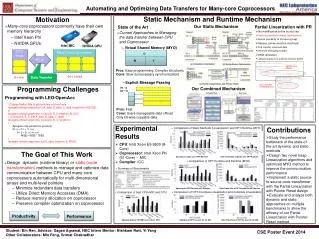
int * a. O. Static Mechanism and Runtime Mechanism. Motivation. int ** b. M. Y. Many-core coprocessors commonly have their own memory hierarchy – Intel Xeon Phi – NVIDIA GPUs. Our Static Mechanism. Partial Linearization with PR. State of the Art.

E N D
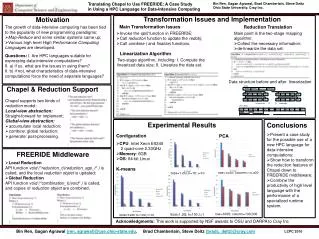
int * a O Static Mechanism and Runtime Mechanism Motivation int ** b M Y • Many-core coprocessors commonly have their own memory hierarchy • – Intel Xeon Phi • – NVIDIA GPUs Our Static Mechanism Partial Linearization with PR State of the Art • No modification to the access-site • Preserve potential compiler optimizations • Reduce possibility of introducing bugs • Reduce communication overhead • Only transfer linearized data • Minimize offloading number • DMA utilization • Linearized data is in a dense memory buffer Intel MIC NVIDIA GPU • – Virtual Shared Memory (MYO) CPU Host Many Core Coprocessor PCIe • Current Approaches to Managing the data transfer between CPU and Coprocessor High Dim Array Addition Pros: Easy programming, Complex structures Cons: Slow (unnecessary synchronization) Data Transfer 60+ cores 8-core – Explicit Message Passing Struct and Non-unit Stride Access Programming Challenges Our Combined Mechanism Programming with LEO/OpenAcc … //Change Malloc-Site to split pointers and real data #pragma offload target(mic) in(A_data, B_data, C_data: length(m*n) REUSE) {} #pragma offload target(mic) nocopy(A, B, C:length(n) ALLOC) { //Connect A, B, C with A_data, B_data, C_data} #pragma offload target(mic) nocopy(A, B, C: length(n)) { #pragma omp parallel for private(i) for (i = 0; i < n; i++) for (j = 0; j < m; j++) A[i][j] = B[i][j] * C[i][j]; } #pragma offload target(mic) out(A_data: length(m*n) FREE) … Pros: Fast Cons: Users manageable data offload Only bit-wise copyable data Experimental Results Contributions • Comparison of Static Methods (Linearization) and OPT-Runtime (MYO) • Study the performance bottleneck of the state-of-the-art dynamic and static methods • Design two novel heap Linearization algorithms and optimized MYO method to improve the communication performance • Implement a static source-to-source code transformer with the Partial Linearization with Pointer Reset design • Evaluate and analyze both dynamic and static approaches on multiple benchmarks to show the efficacy of our Partial Linearization with Pointer-Reset method • CPU: Intel Xeon E5-2609 (8-Core) • Coprocessor: Intel Xeon Phi (61-Core) -- MIC • Compiler: ICC The Goal of This Work Speedup of Static over OPT-Runtime Data Trans Size of Static over OPT-Runtime • Comparison of OPT-Runtime and Runtime (MYO) • Design dynamic (runtime library) or static (code transformation)methods to manage and optimize data communication between CPU and many-core coprocessors automatically for multi-dimensional arrays and multi-level pointers • – Minimize redundant data transfers • – Utilize Direct Memory Accesses (DMA) • – Reduce memory allocation on coprocessor • – Preserve compiler optimization on coprocessor • Summary of Benchmarks Speedup of OPT-Runtime over Runtime Data Trans Size of OPT-Runtime over Runtime • Comparison of OPT-Complete Linearization and Complete Linearization • Comparison of best CPU+MIC and CPU Productivity Performance Speedup of best CPU-MIC over 8-Core CPU Data Trans Size of OPT-CL over CL for MG Speedup of OPT-CL over CL for MG