Download
1 / 19
190 likes | 219 Views
Learn about top-down and bottom-up cube generation techniques, parallel ROLAP cube construction, and tree partitioning for efficient OLAP processing in data warehousing for decision support.

E N D
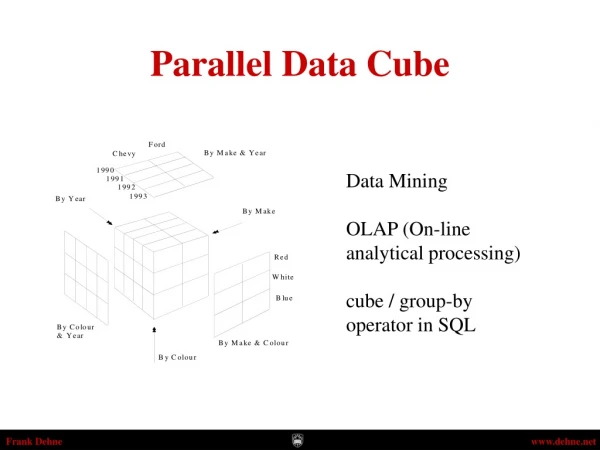
Parallel Data Cube Data Mining OLAP (On-line analytical processing) cube / group-by operator in SQL
Operational data collected into DW DW used to support multi-dimensional views Views form the basis of OLAP processing Our focus: the OLAP server Data Warehousing for Decision Support
Collection of feature attributes Aggregate along one or more measure attributes Reduce the granularity by collapsing dimensions Multi-dimensional views
Proposed by Gray et al (Microsoft) in 1995 Exploits the relationship between cuboids to compute all 2d cuboids In OLAP views are typically pre-computed to improve query response time Data Cube Generation
Top Down Cube Compute high dimension views first Exploit shared dimensions Pipesort PipeHash Bottom Up Cube Minimizes external memory sorting by partitioning first on single attributes ArrayCube Sequential Solutions
ROLAP relational data representation harde to build and query smaller storage no translation from/to relational model MOLAP array representation easy to build and query large storage needs translation from/to relational model Sequential Solutions
Construct the data cube lattice Estimate the edge costs Find a least cost spanning tree Compute the views by following the “pipes” Top Down Cube (Pipesort)
Optimizations • Share-sorts - sharing sorting cost across multiple group-bys. • Smallest parent - computing a cuboid from the smallest previously computed parent. • Cache results - reduce I/O by caching (in memory) parent views from which other cuboids are computed. • Amortize disk-scans - compute as many child views as possible when scanning each parent.
Partition large view into memory-sized units Perform sorting operations in memory May significantly reduce external memory processing Bottom Up Cube
Our Results • Parallel top-down ROLAP cube construction for shared disks (Distributed and Parallel Databases, 2002) • Parallel top-down ROLAP cube construction for distributed disks (IPDPS 2002) • Parallel bottom-up ROLAP cube construction for shared and distributed disks (Distributed and Parallel Databases, 2002) • Parallel ROLAP cube indexing for distributed disks (CCGrid 2003)
Our Results • Parallel top-down ROLAP cube construction for shared disks (Distributed and Parallel Databases, 2002) • Parallel top-down ROLAP cube construction for distributed disks (IPDPS 2002) • Parallel bottom-up ROLAP cube construction for shared and distributed disks (Distributed and Parallel Databases, 2002) • Parallel ROLAP cube indexing for distributed disks (CCGrid 2003)
Parallel top-down ROLAP cube Our approach: • Partition the load in advance and assign cuboids to individual processors • Local computation exploits existing optimized sequential algorithms (ROLAP) • Communication is reduced to a single phase in which work lists are distributed
Cut the process tree into p “equal weight” sub-trees Each processor independently generates cuboids from its own sub-tree Load balance/stripe the output Parallel top-down ROLAP cube
Tree Partitioning • Optimal tree partitioning is NP-complete • Min-max tree k-partitioning: Given a tree T with n vertices and a positive weight assigned to each vertex, delete k edges in the tree to obtain k connected components T1, T2, ... Tk+1 such that the largest total weight of a resulting sub-tree is minimized. • O(n) time, Frederickson 1990 • O(Rk(k + log d)+n) time - Becker, Perl and Schach ‘82
For more information ... http://cgm.dehne.net