Download

1 / 42
450 likes | 841 Views
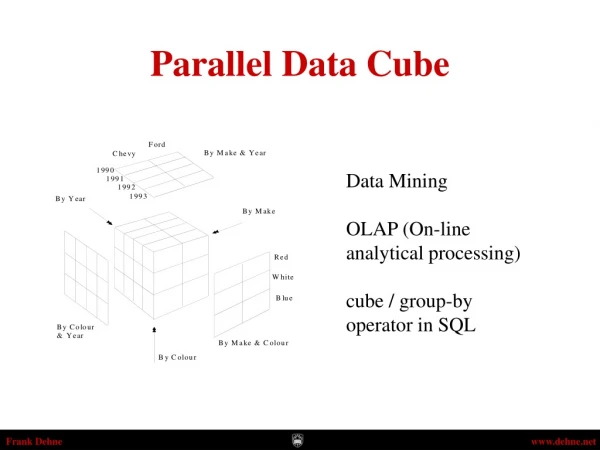
DATA CUBE. Index of Content. The “ALL†value and ALL() function The New Features added in CUBE Computing the CUBE and ROLLUP Maintaining the CUBE and ROLLUP. 3.3 The ALL Value . Each “ALL†value is actually represents a set.

E N D
DATA CUBE Advanced Databases 584
Index of Content • The “ALL” value and ALL() function • The New Features added in CUBE • Computing the CUBE and ROLLUP • Maintaining the CUBE and ROLLUP
3.3 The ALL Value • Each “ALL” value is actually represents a set. • The set over which the aggregation was computed. Ex. Model.ALL ={Toyota, Ford, Nissan} Ex2.
The ALL() Function • ALL() function generates the set. • ALL() applied to any other value returns NULL. Ex. Model.ALL = ALL(Model) = {Toyota, Ford, Nissan} Year.ALL = ALL(Year) = {2011, 2012, 1990} Color.ALL = ALL(Color) = {Red, Blue, Gray}
The Reasons to Avoid the ALL Value Introduction of ALL makes things complicated • ALL becomes a new keyword denoting the set value. • ALL is similar to NULL make many special cases. • What if SQL does not support Set-Value?
3.4 Avoiding the ALL Value Inspired by the ALL() function: A substitution of implementing the ALL value • Use GROUPING() (a booleanfunction) to discriminate between NULL and ALL • Use NULL value in the coulmn instead of ALL value Output: (NULL,NULL,NULL,524,True,True,True)
Example: QUERY: SELECT Model, Year, Color, SUM(sales), GROUPING(Model), GROUPING(Year), GROUPING(Color) FROM Sales GROUP BY CUBE Model, Year, Color; Output: (NULL,NULL,NULL,524,True,True,True) Compare to :(ALL,ALL,ALL,524) Note. True means it is the ALL value
4. Two New Features Added in CUBE Example1.
1. Reference to the sub-aggregate: Now we can reference to the sub-aggregate value.
2. Index of a Value How to select a data in 2-D CUBE?
2. Index of a Value How to select a data in 2-D CUBE?
2. Index of a Value How to select a data in 2-D CUBE? What if we want to select a V in N-Dimension?
2. Index of a Value When the dimension goes higher, itis even harder to describe a point in a CUBE. A query is too long to write.
cube.v(:i, :i, :k) With the index, it is easier to query the data in the CUBE. Especially with a higher dimension CUBE.
5. Computing the CUBE and ROLLUP • It is all about Aggregate Function F() Ex. SUM(), COUNT(), AVERAGE() Generalize: GROUP BY -> ROLLUP -> CUBE Basic Way to Compute: • ROLLUP: Sort the table on the aggregating attributes and then compute the aggregate functions. • CUBE: UNION of many ROLLUP, so the naïve way to compute is union.
The Aggregate Function Call the aggregate function for each new value and invokes the aggregate function to get the final value Init (&handle) Iter (&handle, value) Value = Final(&handle) Start() – Initialize and allocate a scratchpad Next() – When each value to be aggregated End() – Compute and return the aggregate value and then deallocate the scratchpad
GROUP BY review GROUP BY Query: Output:
ROLLUP review ROLLUP Query: Output: ROLLUP: Sort the table on the aggregating attributes and then compute the aggregate functions. For N-Dimension need N UNIONs
ROLLUP review ROLLUP Query: Output: For N-Dimension need N UNIONs
CUBE review Start with a N-dimension CUBE • Dimension N: N Attributes • Cardinality Ci: Number of the records for each dimension • With the ALL value size of a CUBE will be
CUBE review Start with a N-dimension CUBE • Dimension N: N Attributes • Cardinality Ci: Number of the records for each dimension • With the ALL value size of a CUBE will be
CUBE review Start with a N-dimension CUBE • Dimension N: N Attributes • Cardinality Ci: Number of the records for each dimension • With the ALL value size of a CUBE will be
CUBE review Start with a N-dimension CUBE • Dimension N: N Attributes • Cardinality Ci: Number of the records for each dimension • With the ALL value size of a CUBE will be
2N - Algorithm For a N-dimension single aggregate function F() If a tuple (x1,x2,…,xN, v) is added, -> The Iter(&handle, v) will be call 2N times. -> For each column, either “ALL” or “xi value.” If all the input tuples have been computed -> The final(&handle) function will be invoked for each nodes in the cube.
Distributive Function Def. Aggregate function F() is distributive, if there is a function G() such that Example: COUNT(), MIN(), MAX() and SUM() • Can be divided into many sub-aggregates • F() = G(), but COUNT() • For COUNT(), G() = SUM() and F()=COUNT() • Both G(),F() return single value
Distributive Function: COUNT() COUNT1() COUNT2() COUNT3()
Distributive Function: COUNT() COUNT1() SUM() COUNT2() COUNT3()
Algebraic Function Def. Aggregate function F() is algebraic if there is an M-tuple valued function G() and a function H() that Example: Average(), Center-of-Mass(), MaxN() • Can be divided into many sub-aggregates • Sub-aggregate returns Set-Value • G() returns M-tuple and H() returns single value • For F() = AVERAGE(): G()={value,count} , H()= SUM(value)/SUM(count)
Algebraic Function: Average() G1()={SUM1(), COUNT1} G2()={SUM2(), COUNT2()} G3()={SUM3(), COUNT3()}
Algebraic Function: Average() G1()={SUM1(), COUNT1} H() = SUM()/COUNT() G2()={SUM2(), COUNT2()} G3()={SUM3(), COUNT3()}
Holistic Function Def. Aggregate function F() is holistic if there is no constant bound on the size of the storage needed. Example: Median(), MostFrequent() and Rank() • Must go through every data • Can not separate in to sub-aggregate The most efficient way: 2N-algorithm (the slowest)
Have to go through each data! Algebraic Function: Rank()
The Aggregate Function in CUBEs Call the aggregate function for each new value and invokes the aggregate function to get the final value Init (&handle) Iter (&handle, value) Value = Final(&handle)
The Aggregate Function in CUBEs Call the aggregate function for each new value and invokes the aggregate function to get the final value Init (&handle) Iter (&handle, value) Value = Final(&handle) Super-aggregates: Iter_super(&handle, &handle)
Distributive Function To Compute the Distributive Function Value: where Aggregate Function F(), Cardinality C, and Dimension N Color (Model, ALL, Time) Model (ALL, Color, Time) (ALL, ALL, Time) Time (Model, Color, Time) 3D CUBE (ALL, ALL, ALL)
Distributive Function Iter_super(&handle, &handle)
How about INSERT, DELETE and UPDATE? UPDATE = DELETE + INSERT Is it the same?
6. Maintaining Cubes and Roll-Ups F() = Max() Distribute for SELECT and INSERT Holistic for DELETE UPPDATE is DELETE plus INSERT