Download
1 / 15
150 likes | 222 Views
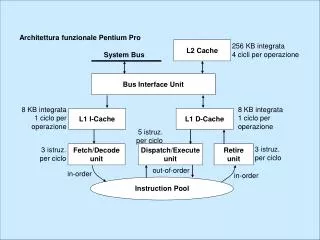
Architettura funzionale Pentium Pro. L2 Cache. 256 KB integrata 4 cicli per operazione. System Bus. Bus Interface Unit. L1 I-Cache. L1 D-Cache. 8 KB integrata 1 ciclo per operazione. 8 KB integrata 1 ciclo per operazione. 5 istruz. per ciclo. 3 istruz. per ciclo. 3 istruz.

E N D
Architettura funzionale Pentium Pro L2 Cache 256 KB integrata 4 cicli per operazione System Bus Bus Interface Unit L1 I-Cache L1 D-Cache 8 KB integrata 1 ciclo per operazione 8 KB integrata 1 ciclo per operazione 5 istruz. per ciclo 3 istruz. per ciclo 3 istruz. per ciclo Fetch/Decode unit Dispatch/Execute unit Retire unit out-of-order in-order in-order Instruction Pool
ARCHITETTURA CPU L2 ext. BUS MOB BIU DCU IFU RS MIU ID BTB AGU IEU MIS FEU ROB RRF RAT back end in-order core out-of-order front end in-order
Legenda schema Pentium pro RS Reservation Station FEU Floating point Execute Unit IEU Integer Execute Unit AGU Address Generation Unit MIU Memory Interface Unit DCU Data Cache Unit MOB Memory Order Buffer BIU Bus Interface Unit IFU Instruction Fetch Unit ID Instruction Decoder BTB Branch Target Buffer MIS Microcode Instruction Sequencer RAT Register Alias Table ROB ReOrder Buffer RRF Retirement Register File
1 3 2 4 6 5 31 33 32 34 7 9 8 10 11 35 36 pipeline Pentium Pro 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 0 Istruzioni completate = 0
1 1 31 2 6 32 4 34 7 9 10 36 pipeline Pentium Pro Il pipeline esegue il prefetch di tutte le istruzioni disponi-bili, e ne determina le di-pendenze. Nell’esempio: prima la #1 e poi la #3 prima la #4 e poi la #5 prima la #32 e poi la #33 prima la #34 e poi la #35 prima la #7 e poi la #8 prima la #9 e poi la #11 : istruzione eseguibile immediatamente : istruzione sospesa in attesa di dati 3 5 33 35 3 8 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 0 Istruzioni completate = 0
1 36 10 9 7 32 34 1 6 4 2 2 31 pipeline Pentium Pro Il Pentium Pro ha un pipeline superscalare a tre livelli con esecuzione out-of-order, preceduto da un modulo di prefetch e seguito da un modulo di writeback per aggiornare lo stato della CPU in-order. Manda quindi in esecuzione le prime tre istruzioni pronte, cioè #1, #2 e #4. La #3 viene accantonata perché non è pronta. Al termine le modifiche apportate dalle istruzioni #1 e #2 vengono registrate nello stato della CPU. aggiornamento in-order dello stato della CPU 3 istruzione da 2 cicli 4 5 33 35 8 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 1 Istruzioni completate = 2
1 32 2 4 6 31 34 31 9 10 36 6 1 2 7 pipeline Pentium Pro L’istruzione #4 si conclude, ma le sue modifiche non vengono ancora registrate perché l’istruzione che la precede non è ancora terminata (writeback in-order). L’istruzione #5 non è ancora pronta, quindi il pipeline carica altre tre istruzioni, la #3 (che nel frattempo è diventata pronta), la #6 e la #31. La ricerca delle dipendenze segue anche i salti. La #3 determina un miss in L1, e quindi durerà 4 cicli. Tuttavia il pipeline non si blocca. 3 3 L1 miss 4 5 33 35 8 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 2 Istruzioni completate = 2
1 34 2 4 6 31 32 7 32 10 5 31 36 6 2 1 9 pipeline Pentium Pro L’istruzione #3 resta sempre in attesa. Il termine interno della #4 permette l’esecuzione della #5. Le altre due nuove istruzioni eseguibili da immettere nel pipeline sono la #32 e la #34, anche se quest’ultima causa un miss su L1 della durata di 4 cicli. La gestione degli accessi esterni (L2) è composto da un altro pipeline a 4 livelli, cioè si possono accodare fino a 4 richieste di dati in parallelo. 3 3 L1 miss 4 5 33 34 L1 miss 35 8 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 3 Istruzioni completate = 2
1 32 5 1 2 4 6 2 31 32 7 7 9 36 10 33 6 36 31 34 pipeline Pentium Pro Le istruzioni #3 e #34 restano sempre in attesa. Le modifiche apportate dalle istruzioni #4, #5, #6, #31, #32 non vengono ancora registrate. 3 3 L1 miss 4 5 33 34 L1 miss 35 istruzione lunga due cicli 8 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 4 Istruzioni completate = 2
1 2 4 6 31 32 34 7 9 10 2 36 1 36 33 32 5 12 31 6 10 pipeline Pentium Pro Vengono immesse nel pipeline le istruzioni #9 e #10, e l’ipotetica istruzione #12. L’istruzione #3 finalmente termina e svincola anche le modifiche delle istruzioni #4 e #5 che aggiornano nella giusta sequenza lo stato della CPU. Il modulo di Writeback può aggiornare al massimo tre istruzioni per volta, e quindi le modifiche apportate dalle istruzioni #6, #31, #32, #33, #36, #7 e #10 non vengono ancora registrate. 3 3 L1 miss L2 hit 4 5 33 L1 miss 34 35 7 8 9 L1 miss 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 5 Istruzioni completate = 5
1 4 10 2 31 6 32 34 7 9 14 36 13 1 2 6 31 5 32 33 36 10 12 8 pipeline Pentium Pro Vengono immesse nel pipeline l’istruzione #8, finalmente pronta, e le ipotetiche istruzioni #13 e #14. Le istruzioni #34 ed #8 terminano ed escono dal pipeline, la #9 resta sempre in attesa. Le modifiche apportate dalle istruzioni #6, #31 e #32 vengono registrate in-order nel registro di stato della CPU. 3 3 4 5 33 34 L1 miss L2 hit 35 7 8 9 L1 miss 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 6 Istruzioni completate = 8
1 2 10 36 9 7 34 32 31 16 15 1 4 2 31 5 32 33 36 10 12 8 13 14 35 6 6 pipeline Pentium Pro Vengono immesse nel pipeline l’istruzione #35, finalmente pronta, e le ipotetiche istruzioni #15 e #16. L’istruzione #9 resta sempre in attesa. Le modifiche apportate dalle istruzioni #36, #7, #8 e #10 non vengono ancora registrate. 3 3 4 5 33 34 35 7 8 9 L1 miss 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 7 Istruzioni completate = 11
1 2 6 10 31 9 34 7 36 32 16 18 12 17 35 4 15 2 19 6 31 32 33 5 1 10 8 13 14 36 pipeline Pentium Pro Vengono immesse nel pipeline le ipotetiche istruzioni #17, #18 e #19. L’istruzione #9 termina ma le sue modifiche non vengono registrate. Le modifiche apportate dalle istruzioni #36, #7 e #8 vengono registrate in-order nel registro di stato della CPU. 3 3 4 5 33 34 35 7 8 L1 miss L2 hit 9 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 8 Istruzioni completate = 14
1 7 32 36 10 9 6 4 2 34 21 20 1 11 16 18 31 35 2 6 31 17 5 33 36 32 12 8 13 14 15 19 10 pipeline Pentium Pro Vengono immesse nel pipeline l’istruzione #11 finalmente pronta, e le ipotetiche istruzioni #20 e #21. Al fine del ciclo le modifiche apportate dalle istruzioni #9, #10 e #11 vengono registrate in-order nel registro di stato della CPU. Globalmente dopo 9 cicli di clock sono state eseguite in ordine 17 istruzioni, e sono state immesse nel pipeline e potenzialmente pronte per essere terminate altre 10 istruzioni. A regime si può arrivare a 3 istruzioni per ciclo. 3 3 4 5 33 34 35 7 8 9 11 1 2 3 4 5 6 7 8 9 10 11 12 Cicli di clock = 9 Istruzioni completate = 17
pipeline Pentium Pro • I principi dell’esecuzione dinamica sono: • Multiple branch predition • DataFlow analysis • Speculative execution • Acquisizione delle istruzioni e loro completamento secondo l’ordine voluto dal programmatore. • Esecuzioni interna out-of-order, per ottimizzare l’occupazione del pipeline interno, secondo modalità data-flow. • Quando si verificano interrupt, predizioni errate di salti, miss anche a livello L2 o eccezioni interne, il pipeline deve essere in grado di annullare il lavoro di esecuzione preventiva svolto in precedenza • . • Speculative execution (esecuzione preventiva o esecuzione anticipata?)





















