Download

1 / 30
300 likes | 415 Views
Sub- Nyquist Sampling Continuous to Finite Module Matching Pursuit Block. Performed by: Yoni Smolin Supervisors: Inna Rivkin & Moshe Mishali Winter 2009 – Spring 2010 . Midterm Presentation – Part A. Agenda. CTF – introduction Choice of Matching Pursuit OMP - algorithm OMP – entity

E N D
Sub-Nyquist SamplingContinuous to Finite ModuleMatching Pursuit Block Performed by: Yoni Smolin Supervisors: Inna Rivkin & Moshe Mishali Winter 2009 – Spring 2010 Midterm Presentation – Part A
Agenda • CTF – introduction • Choice of Matching Pursuit • OMP - algorithm • OMP – entity • OMP – architecture suggestion
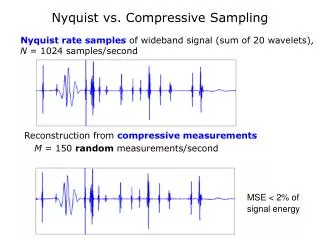
Life span of the signal System’s parameters: CTF block
Continuous to finite flow • The frame matrix: CTF • Sampling relation:
Continuous to finite flow CTF • The multiplemeasurement vectors problem: Support
MMV - approaches to solution • The following Matching Pursuit algorithms have been implemented in floating point, Matlab environment: • BMP – Basic MP. 60.7% • OMP – Orthogonal MP. 62.0% • ORMP – Order Recursive MP. 63.5% Mean Recovery Rate 1 2 • ROMP – Regularized OMP. 61.7% • CoSaMP – Compressive Sampling MP. 46.0% • MY_MP : 1,2,3 34.7%,56.5%,67.7%
Fixed point simulations • CTF Input’s resolution bounds obtained for BMP : • – 7 bits - 12 bits remark: was normalized prior to quantization. • An 18 bit Word format was chosen for hardware: • Explanation: • Long word length helps avoid saturation. • Expand produces in an 18 bit format for DSP. • Altera DSP complex multipliers support only an exactly 18 bit (real,imaginary) input.
Choosing MP – the challenge • Theoretically - BMP iterations suffice to obtain the support. • In practice – quantization slows down the convergence. • Two possible solutions were proposed: • Modify BMP. • Upgrade to OMP.
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 1 – project residual i'th iteration • problem definition
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 2 – calculate projection’s energy i'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 3 – choose best representative i'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 4 – update support i'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 5.1 – Gram-Schmidt initialization i'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 5.2 – Gram-Schmidt orthogonalizationi'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 5.3 – Gram-Schmidt normalization i'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 6 – residual update i'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 7 – calculate residual energy i'th iteration
OMP – the algorithm - 1 - 12 - 101 • OMP – Phase 8 – check for stopping condition i'th iteration
OMP – entity frame _ready support Frame OMP Merge frame _data 84 support_valid 432x12 wr_request rd_enable pause test_points clk_3 rst 64 start_load 4 432 A_rd_ req A_ addr ready A_data A - memory
Interface - protocols • Initialization: rst start_load ready • A, frame memories: T.B.D. • Support transmission: support_valid support asynch. synch. synch. synch. new value synch.
Architecture considerations • Guiding principles • Saving time at the expanse of hardware (parallelization). • Maximizing hardware reusability via multi-task blocks. • Pipelined Architecture to speed up clock rate.
Arithmetic unit: complexity bound • OMP’s Phase 1 is clearly the most expensive: • Implementation suggestions:
Arithmetic unit: multi-task design • Capable of handling phase 2 phase 5.2 phase 1 phase 5.2,5.3 phase 6 phase 7
Arithmetic unit ↔MaMu MaMu In_row_vec out_col_vec1 432 In_col_vec1 432 432 out_col_vec12 432 In_col_vec12 432 • Input: 5,616 lines – 13 complex vectors • Output: 5,184 lines – 12 complex vectors • Complex multipliers: 144 • Adders (36-43 bit) :300 • Registers (36-43 bit) :300
Memories • A – 12x101 complex matrix : 5.4KByte • Service provider: Architecture team. • Access: Reading, one column at a time. • Q (which becomes R) – 12x12 complex matrix : 0.6KByte • Service provider: Frame & Merge team. • Access: Read & write, whole matrix at once. • W – 12x12 complex matrix : 0.6 Kbyte. • Service provider: OMP (myself). • Access: Read – 2 columns at a time. Write – 1 column at a time. • Protocols – T.B.D.
A_col Datapath sketch sym best A_col best a KeepMax A sym W_col_rd MaMu w W Sub res sub_res R W_col_wr res a Norm sub_res Norm R_rd Stopping Cond. R_energy Stop sub_res R R dec R_wr best Support buffer support sym
Hardware requirements • Extra blocks: • 12x12 complex matrix subtractor: 28818-bit subtractors. • 18-bit , operations. • Extra operation : 12 complex multipliers & adders. • Total Hardware requirements approximation: • 18-bit complex multipliers: 156 (of 224) • 18-bit adders: ~350 • 18-bit subtractors: ~300 • Total runtime approximation: • Clock cycles: • Seconds (assuming 150MHz clock):
References • M. Mishali and Y. C. Eldar, “From theory to practice: Sub-Nyquist sampling of sparse wideband analog signals” arXiv.org 0902.4291; to appear IEEE J. Sel. Topics Signal Process. • AviSeptimus, “Hardware Implementation of Reconstruction Algorithm for Compressive Sampling”, VLSI Lab. annual project, 2008-2009.