Download

1 / 55
550 likes | 562 Views
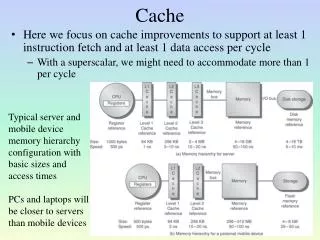
Cache. Based in part on Chapter 9 in Computer Architecture (Nicholas Carter). Pentium 4 Blurb (L1). Some cache terms to understand: Data cache Execution Trace Cache. Pentium 4 Blurb (L2). Some cache terms to understand: Non-Blocking 8-way set associativity on-die.

E N D
Cache Based in part on Chapter 9 in Computer Architecture (Nicholas Carter)
Pentium 4 Blurb (L1) • Some cache terms to understand: • Data cache • Execution Trace Cache
Pentium 4 Blurb (L2) • Some cache terms to understand: • Non-Blocking • 8-way set associativity • on-die
Caching Analogy: Why grading late homework is a pain • To grade a student’s homework problem, a professor must • Solve the problem • Compare the answer with the student’s • When grading the homework of a class of students’ homework, the professor can • Solve the problem • Compare the answer with Student 1’s answer • Compare the answer with Student 2’s answer • …
Caching Analogy (Cont.) • In other words, the professor “caches” the solution so that all students after the first can be graded much more quickly than the first. • Even if the professor “stores” the solution (that is, files it away), it is not handy when it comes time to grade the late student’s homework.
Caching Analogy (Cont.) • You might think the benefits of caching are too contrived in the previous example since the professor instructed all of the students to solve the same problem and submit it at the same time. • Suppose students (on their own volition) looked at the problems at the end of the chapter being discussed. • It’s hard to imagine, I know.
Caching Analogy (Cont.) • Then a student might come to the professor’s office for help on a difficult problem. • The professor should keep the solution handy because a problem that was difficult for one student is likely to be difficult for other students who are likely to turn up soon. • This is the notion of “locality of reference” • What was needed/used recently is likely to be needed/used again soon.
Locality Of Reference • The memory assigned to an executing program will have both data and instructions. At a given time, the probability that the processor will need to access a given memory location is not equally distributed among all of the memory locations. • The program may be more likely to need a location that it has accessed in the recent past – this is known as temporal locality. • The program may be more likely to need a location that is near the one just accessed – this is known as spatial locality.
Loops and Arrays • Consider that the tasks best suited for automation (to be done by machine including a computer) are repetitive. • Any program with loops and arrays is a good candidate to display locality of reference. • Also waiting for some user event is also very repetitive. This repetition may be hidden from the programmer working with a high-level language.
Locality of reference • Locality of reference is the principle behind caching. • Locality of reference is what allows 256-512 KB of cache to stand in for 256-512 MB of memory. • The cache is a factor of 1000 times smaller, yet the processor finds what it needs in cache ninety-some percent of the time.
Caching • The term cache can be used in different ways. • Sometimes “cache” is used to refer generally to placing something where it can be retrieved more quickly. In this sense of the term, there is an entire hierarchy of caching, SRAM is faster than DRAM is faster than the hard drive is faster than the Internet. • Sometimes “cache” is used to refer specifically to the top layer of the above hierarchy (the SRAM). • For the rest of the presentation, we will be using the latter meaning.
What are we caching? • We have to look one level down in the memory/storage hierarchy to realize what it is we are caching. • One level down is main memory. • Recall how one interacts with memory (DRAM) – one supplies an address to obtain the value located at that address.
What are we caching? • We must cache the address and the value. • Recall our analogy – if the professor writes down the (final) answer but does not recall what problem it is the answer to, it is useless. • Ultimately we want the value, but it is the (memory) address we will be given and that is what we will search for in our cache. • The student does not ask if 43 is the answer (the answer to what?); the student asks what is the answer to problem 5-15.
Some terminology • Think of cache as parallel arrays (address and values). • The array of addresses is called the tag array. • The array of values is called the data array. • Don’t confuse the terms “data array” and “data cache.” • A memory address is supplied: • If it is found in the tag array, one is said to have a cache hit and the corresponding value from the data array is sent out. • If it is not found, one has a cache miss, and the processor must go to memory to obtain the desired value. • The percentage of cache hits is known as the hit rate (usually looking for 90% or better).
Cache Controller • In addition to the tag and data arrays is the cache controller which runs the show. • When L2 cache was separate from the processor, the cache controller was part of the system chipset. • When L2 cache moved onto the microprocessor so too did the controller. • Now it is the L3 cache controller which is part of the system chipset. • Now even L3 is moving onto the microprocessor.
Data Array versus Data Cache • The term data array refers to the set of values that are placed in cache. • The term data cache refers the caching of data as opposed to the instruction cache where instructions are cached. • In a modern adaptation of the Harvard architecture, called the Harvard cache, data and instructions are sent to separate caches. • Unlike data, an instruction is unlikely to be updated – overwritten yes, updated no. Therefore data cache and instruction cache can have different write policies.
Capacity • The usual specification (spec) one is given for cache is called the capacity. • E.g. Norwood-core Pentium 4s have a 512 KB L2 cache. • The capacity refers only to the amount of information in the data array (values). • The spec does not include the tag array (addresses), the dirty bits, and so on – though they must of course be there.
Lines and Line Lengths • The basic unit of memory is a byte, the basic unit of cache is a line. • Be careful not to use the word “block” in place of “line.” In cache, blocking means that upon a cache miss, one must write the new values to cache before proceeding. • A line consists of many bytes (typically a power of 2, such as 32, 64 or 128). The number of bytes in a line is called the line length.
Memory Cache 0 1 2 3 ….
Example • Assume a capacity of 512 KB. • Don’t think of an array with 524,288 (512 K) elements with each element a byte long as you would if it were main memory. • Instead think of an array with 16,384 (16 K) elements with each element 32 bytes long.
Line Length Benefits • The concept of cache lines has a few benefits • It directly builds in the notion of spatial locality – cache is physically designed to hold the contents of several consecutive memory locations. • Eventually we must perform a search on the tags to see if the particular memory address has been cached. The line length shortens the tag, i.e. the item one must search for. • In the example on the earlier slide one would search for FFA instead of FFA3. That is the tag is four bits smaller than the address.
Line Length Benefits • The cached value must have been read from memory. Recall that one can significantly improve the efficiency of reading memory locations if they are consecutive locations (especially if they are all in the same row). • So the paging/bursting improvements of reading memory are particularly important because of the way cache is structured.
Hardware Searching • The cache is handed a memory address, it strips off the least significant bits to form the corresponding search tag, it then must search the tag array for that value. • The most efficient search algorithm you know is useless at this level, we need to perform the search in a couple clock cycles. We need to search using hardware.
Variations • The hardware search can be executed in a number of ways and this is where the terms direct-mapped, fully associative and set-associative come in. • The Pentium 4’s Advanced Transfer cache has 8-way set associativity. • The variations determine how many comparators (circuitry that determines whether we have a hit or miss) are necessary.
Direct Mapping • Direct Mapping simplifies tag-array searching (i.e. minimizes the number of comparators) by saying that a given memory location can be cached in one and only one line of cache. • The mapping is not one-to-one. Since memory is about a thousand times bigger than cache, many memory locations share a cache line, and only one section of memory can be in there at a time.
Direct Mapping Cache A given memory location is mapped to one and only one line of cache. But each line of cache corresponds to several (sets of) memory locations. Only one of these can be cached at a given time. Memory
A Direct Mapping Scenario Memory Address The part of the address actually stored in the tag array Determines the cache address that will be used Determines position within the line of cache
A Direct Mapping Scenario (Cont.) • A memory address is handed to cache. • The middle portion is used to select the cache address. • The tag stored at that cache address and the upper portion of the original memory address are sent to a comparator. • Note there’s one comparator! • If they are equal (a cache hit), then the lower portion of the original memory address is used to select out the byte from within the line.
A Potential Problem with Direct Mapping • Recall that locality of reference (the notion behind caching) is particularly effective during repetitive tasks. • Imagine that a loop involves two memory locations that share the same cache address (perhaps it processes a large array). Then each time the processor wanted one of the locations, the other would be in the cache. Thus, there would be two cache misses for each iteration of the loop. But loops are when caching is supposed to be at its most effective. • TOO MANY CACHE MISSES!
Fully Associative Cache: The Other Extreme • In Direct Mapping, a given memory location is mapped onto one and only one cache location. • In Fully Associative Caches, a given memory location can be mapped to any cache location. • This will solve the previous problem. There’s no conflict – one caches whatever is needed for the loop. • But with fully-associative cache searching becomes more difficult, one has to examine the entire tag array whereas before with direct mapping there was only one place to look.
Associativity = Many Comparators • Looping through the tag array would be prohibitively slow. We must compare the memory address (or the appropriate portion thereof) to all of the values in the tag array simultaneously.
Array of Comparators Address Hit? Yes or no Address of hit For each element of the tag array, there is a comparator. Each comparator checks the tag element against the search tag.
Associative memory • In regular memory, one provides an address, and then the value at that address is supplied. • In associative memory (content addressable memory), one provides the value or some part thereof, and then the address and/or the remainder of the value is supplied.
The Problem with Fully Associative Cache • All of those comparators are made of transistors. They take up room on the die. And any space lost to comparators has to be taken away from the data array. • After all we’re talking about thousands of comparators. • ASSOCIATIVITY LOWERS CAPACITY!
Set-Associative Caches: The Compromise • For example, instead of having the 1000-to-1 mapping we had with direct mapping, we could elect to have an 8000-to-8 mapping. • That is, a given memory location can be cached into any of 8 cache locations, but the set of memory locations sharing those cache locations has also gone up by a factor of 8. • This would be called an 8-way set associative cache.
A Happy Medium • 4- or 8-way set associative provides enough flexibility to allow one (under most circumstances) to cache the necessary memory locations to get the desired effects of caching for an iterative procedure. • I.e. it minimizes cache misses. • But it only requires 4 or 8 comparators instead of the thousands required for fully associative caches.
Bad Direct Mapping Scenario Recalled • With direct mapping cache, the loop involves memory locations that share the same cache address. With set associative cache, the loop involves memory locations that share the same set of cache addresses. • It is thus possible with set associative cache that each of these memory locations is cache to a different member of the set. The iterations can proceed without repeated cache misses.
Set-Associative Cache • Again the memory address is broken into three parts. • One part determines the position in the line. • One part determines this time a set of cache addresses. • The last part is compared to what is stored in the tags of the set of cache locations. • Etc.
PCGuide.com comparison table To which we add that full associativity has an adverse effect on capacity.
Cache Misses • When a cache miss occurs, several factors have to be considered. For example, • We want the new memory location written into the cache, but where? • Can we continue attempting other cache interactions or should we wait? • What if the cached data has been modified? • Should we do anything with the data we are taking out of the cache?
Replacement Policy • Upon a cache miss, the memory that was not found in cache will be written to cache, but where? • In Direct Mapping, there is no choice it can only be written to the cache address it is mapped to. • In Associative and Set-Associative there is a choice in what to replace.
Replacement Policy (Cont.) • Least Recently Used (LRU) • One approach is to track the use of what is in cache and to replace the line that is being used the least. • This is best in keeping with the locality of reference notion behind cache, but it requires a fair amount of overhead. • Not-Most-Recently Used • Another approach is to choose a line at random except that one protects the line (from the set) that has been used most recently • Less overhead
Blocking or Non-Blocking Cache • Replacement requires interacting with a slower type of memory (a lower level of cache or main memory). Do we allow the processor to continue to access cache during this procedure or not? • This is the distinction between blocking and non-blocking cache. • In blocking, all cache transactions must wait until the cache has been updated. • In non-blocking, other cache transactions are possible.
Cache Write Policy • The data cache may not only be read but may also be written to. But cache is just standing in as a handy representative for main memory. That’s really where one wants to write. This is relatively slow just as reading from main memory is relatively slow. • Rules about when one does this writing to memory is called one’s write policy. • One reason for separating data cache and instruction cache is that the instruction cache does not require a write policy. • Recall the separation is known as the Harvard cache.
Write-Back Cache • Because writing to memory is slow, in Write-Back Cache, a.k.a. "copy back” cache, one waits to until the line of cache is being replaced to write any values back to memory. • Main memory and cache are inconsistent but the cache value will always be used. • In such a case the memory is said to be “stale.”
Dirty Bit • Since writing back to main memory is slow, one only wants to do it if necessary, that is, if some part of line has been updated. • Each line of cache has a “dirty bit” which tells the cache controller whether or not the line has been updated since it was last replaced. • Only if the dirty bit is flipped does one need to write back.