Download

1 / 30
300 likes | 825 Views
Hashing 함수의 종류 및 특징 . 99135036 컴퓨터 과학과 심형광. I N D E X. 1. Hashing 함수 2. Hashing 함수의 종류 3. 참조 자료. 1. Hashing 함수. Hashing 함수 (1). Hashing 함수의 정의 - 레코드 키 값을 bucket 의 주소에 대응 시키는 방법 Hashing 함수의 조건 - 주소 계산이 빨라야 함 - 가급적 결과 값이 중복되어서는 안됨 Hashing 함수의 고려사항

E N D
Hashing 함수의 종류 및 특징 99135036 컴퓨터 과학과 심형광
I N D E X 1. Hashing 함수 2. Hashing 함수의 종류 3. 참조 자료
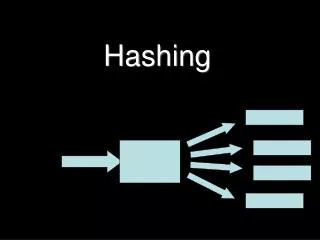
Hashing 함수 (1) • Hashing 함수의 정의 - 레코드 키 값을 bucket의 주소에 대응 시키는 방법 • Hashing 함수의 조건 - 주소 계산이 빨라야 함 - 가급적 결과 값이 중복되어서는 안됨 • Hashing 함수의 고려사항 - bucket, hash table, 적재 밀도 등을 고려해야함
Hashing 함수 (2) • Bucket • 레코드 키를 저장할 수 있도록 마련된 기억 장소 • 한 개 또는 여러 레코드 값을 저장할 수 있는 슬롯으로 구성됨 • bucket에 레코드들이 가득차면 overflow가 발생함
Hashing 함수 (3) • Hash Table • 레코드의 저장을 위한 자료구조 • 결과 값을 저장하기 위해서 bucket들로 구성된 기억 공간 • 레코드의 빠른 검색을 위한 수단을 제공 • 삽입과 삭제가 용이해야함
Hashing 함수 (4) • Loading density (적재 밀도) • 저장된 레코드 수 / 공간의 총 용량 • 레코드 수 / 버킷 수 * 버킷 용량 < 1 • 높으면 접근 횟수가 증가하고 낮으면 효율이 떨어짐 • 효율적인 적재밀도는 약 70% 정도임
Hashing 함수 (5) • 일반적인 hashing 의 조건 • 함수의 계산시간이 빨라야 함 • 모든 주소에 균일한 분포를 가지도록 설정해야 함
Hashing 함수의 종류 • Division (제산법) • Mid – Square (제곱법) • Digit Analysis (숫자 분석법) • Shifting (이동법) • Radix Conversion (기수 변환법) • Folding (중첩법) • Pseudo Random (난수 생성법) • Algebraic Coding (대수적 코딩) • 자리수 재배열
2.1 Division (1) • 나머지 연산자(%)를 사용하여 주소를 계산 • 어떤 양의 정수 (대개는 해시 테이블 크기)로 나눈 나머지를 주소 값으로 이용 • 특징 • 가장 간단한 방법 • 양의 정수 값을 잘못 선택하면 상당한 충돌을 유발 • 보통 나누는 값으로 소수를 선택함
2.1 Division (2) • Example • 레코드 개수 : 4000, 적재 밀도 : 80% • 주소 공간 : 5000, Divisor : 5,003 • 이 때 주소 값 중에서 0472 의 값이 중복되어 충돌이 발생함 ㅡ> 해결이 필요
2.2 Mid – Square (1) • 키 값을 제곱한 후에 중간의 몇 자리를 선택하고 그 중간 값을 주소로 이용 • 심벌 테이블 응용에 주로 사용됨 • 키를 구성하는 몇 개의 문자가 동일해도 결과값은 상이할 수 있음 • 주소의 범위를 조정할 필요가 있음
2.2 Mid – Square (2) • Example • 레코드 키 값 k : 35270 • 해시 테이블 크기: 10000 (중간 4비트 선택) • 결과 • 레코드 값 k 의 제곱한 값 k’ : 1243972900 • 그 결과값에서 중간 4자리인 9729 가 주소 값이 됨
2.3 Digit Analysis (1) • 각 숫자의 분포를 이용해서 균등한 분포의 숫자를 선택해서 사용 • 키 값이 알려진 정적 파일에 용이 • 비교적 간단하지만 삽입과 삭제가 빈번한 경우는 비효율적임
2.3 Digit Analysis (2) • Example • 테이블 크기 : 1000 • 홈 주소 : 0~999(3자리) • 결과 : 4, 8, 10열을 선택 • 왼쪽 3자리 숫자는 거의 동일함 ㅡ> 제거 • 5,6,7,9 열 역시 비슷한 숫자가 많음ㅡ>무시 • 비교적 고른 분포인 4,8,10열 선택ㅡ>사용
2.4 Shifting (1) • 키 값을 중앙을 중심으로 양분 • 주소길이 만큼 숫자를 이동시켜 해쉬 값을 구한 후 주소 범위에 맞도록 조정함
2.4 Shifting (2) • Example • 레코드 키 값 k : 12345678 • 주소 공간 : 5000 • 결과 • 주소 값으로 6912 를 사용 • 실제 주소 : 6,912 * 0.5 = 3,456
2.5 Radix Conversion (1) • 주어진 키의 값을 다른 진법으로 변환하여 얻은 결과 값을 주소로 사용 • 초과하는 높은 자리수는 절단함
2.5 Radix Conversion (2) • Example (10진수 ㅡ> 11진수) • 키 값 : 172148 • 주소 공간 : 7000 • 결과 • h(172148) = 266373 • 여기서 하위 4자리 6373을 주소로 사용 • 실제 주소 : 6373 * 0.7 = 4461
2.6 Folding • 마지막 부분을 제외한 모든 부분이 동일하도록 분할 • 이들 부분을 모두 더하거나 XOR 을 해서 결과 값을 주소로 이용 • Shifting Folding 방법과 Boundary Folding 방법이 있음
2.6.1 Boundary Folding • 키 값을 나눈 후 그 값들의 경계를 중심으로 접어 역으로 정렬한 후 그 값들을 더한 값을 주소로 사용함 • 3자리씩 나누면 • P1 : 301 , P2 : 230, P3 : 12 가 됨 • 주소 : P1+P2(역)+P3 = 301+032+12 = 345 • 이 값을 주소로 사용함
2.6.2 Shifting Folding • 마지막을 제외한 모든 부분을 이동시켜 하위 비트부터 일치 시켜서 계산을 하고 그 결과 값을 주소로 사용함 • 3자리씩 나누면 • P1 : 301 , P2 : 230, P3 : 12 가 됨 • 주소 : P1+P2+P3 = 301+230+12 = 543 • 이 값을 주소로 사용함
2.7 Pseudo Random (1) • 난수 발생 프로그램을 이용해서 난수를 발생 시켜 그 값을 주소 값으로 이용 • 보통 난수는 1보다 작은 값을 사용하고 테이블 크기 n과 곱을 하여 0~(n-1) 의 크기로 변환하여 사용 • 만일 충돌이 발생하면 다음 난수의 결과 값을 레코드의 주소로 사용
2.7 Pseudo Random (2) • x는 키의 값을 나타내며 p는 일반적으로 2의 n제곱을 나타냄 • y = (ax +c) mod p • Example • key : 3386 , a = 5, c = 1, n = 10 • 결과 • y = ( 5 * 3386 +1) mod 1024 = 547 • 547을 주소로 사용함
2.8 Algebraic Coding (1) • 키를 이루고 있는 각각의 비트를 다항식의 계수로 하여 이 다항식을 크기로 정한 다항 식으로 나눌 때 얻은 나머지 다항식의 계수 를 주소로 사용함
2.8 Algebraic Coding (2) • Example • key : 12345 • 다항식 : x⁴ + 2x³ + 3x² + 4x + 5 • 크기 : 100 • 제수 : x² + 2x + 3 • 결과 x² x² + 2x + 3 x⁴ + 2x³ + 3x² + 4x + 5 x⁴ + 2x³ + 3x² 4x + 5 • 나머지 4x + 5 의 계수인 45를 주소로 함
2.9 자리수 재배열(1) • 단순하게 원래의 키 값의 일부분의 자리수 의 값을 추출하여 그 순서를 역으로 한 다 음 그 값을 결과 값으로 사용
2.9 자리수 재배열(2) • Example • 키 값 : 123456789 • 주소 공간 : 4자리 • 결과 • 중간의 4567 을 추출하여 역의 값인 7654 를 주소로 사용함
Reference to • http://internet512.chonbuk.ac.kr/datastructure/hash/hash1.html • http://cs.kangwon.ac.kr/~ysmoon/courses • http://www.comedu.pe.kr/edu/ds-14.htm • http://ghryu.comimadang.com/ppt/ja3.ppt • http://www.terms.co.kr/hashing.htm