Download
1 / 19
190 likes | 275 Views
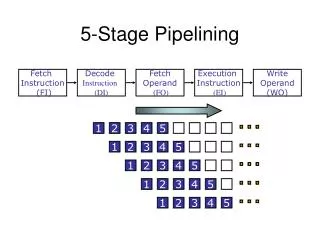
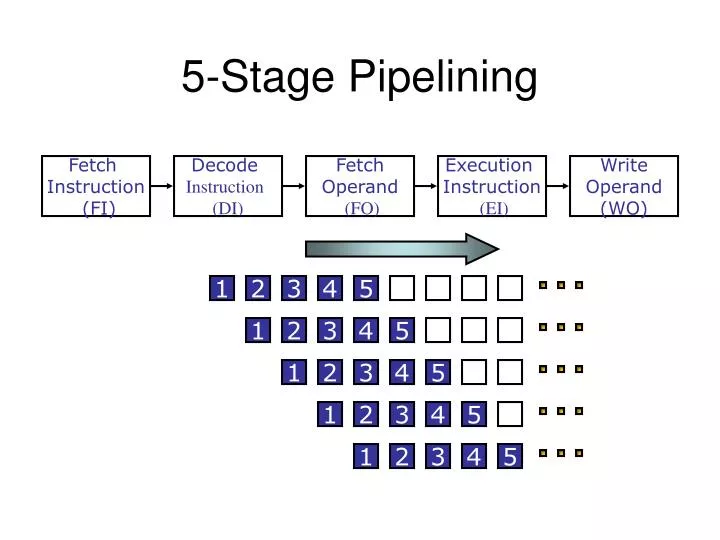
5-Stage Pipelining. S 1. 1. 2. 3. 4. 5. 6. 7. 8. 9. S 2. 1. 2. 3. 4. 5. 6. 7. 8. S 3. 1. 2. 3. 4. 5. 6. 7. S 4. 1. 2. 3. 4. 5. 6. S 5. 1. 2. 3. 4. 5. S 1. S 2. S 3. S 4. S 5. Fetch Instruction (FI). Decode Instruction (DI). Fetch Operand

E N D
5-Stage Pipelining S1 1 2 3 4 5 6 7 8 9 S2 1 2 3 4 5 6 7 8 S3 1 2 3 4 5 6 7 S4 1 2 3 4 5 6 S5 1 2 3 4 5 S1 S2 S3 S4 S5 Fetch Instruction (FI) Decode Instruction (DI) Fetch Operand (FO) Execution Instruction (EI) Write Operand (WO) Time
Five Stage Instruction Pipeline Fetch instruction Decode instruction Fetch operands Execute instructions Write result
Two major difficulties • Data Dependency • Branch Difficulties Solutions: • Prefetch target instruction • Delayed Branch • Branch target buffer (BTB) • Branch Prediction
Data Dependency • Use Delay Load to solve: Example: load R1 R1M[Addr1] load R2 R2M[Addr2] ADD R3R1+R2 Store M[addr3]R3
Example • Five instructions need to be carried out: Load from memory to R1 Increment R2 Add R3 to R4 Subtract R5 from R6 Branch to address X
Delayed Branch • In this procedure, the compiler detects the branch instruction and rearrange the machine language code sequence by inserting useful instructions that keep the pipeline operating without interrupts
Prefetch target instruction • Prefetch the target instruction in addition to the instruction following the branch • If the branch condition is successful, the pipeline continues from the branch target instruction
Branch target buffer (BTB) • BTB is an associative memory • Each entry in the BTB consists of the address of a previously executed branch instruction and the target instruction for the branch
Loop Buffer Very fast memory Maintained by fetch stage of pipeline Check buffer before fetching from memory Very good for small loops or jumps The loop buffer is similar (in principle) to a cache dedicated to instructions. The differences are that the loop buffer only retains instructions in sequence, and is much smaller in size (and lower in cost).
Branch Prediction • A pipeline with branch prediction uses some additional logic to guess the outcome of a conditional branch instruction before it is executed
Branch Prediction • Various techniques can be used to predict whether a branch will be taken or not: • Prediction never taken • Prediction always taken • Prediction by opcode • Branch history table • The first three approaches are static: they do not depend on the execution history up to the time of the conditional branch instruction. The last approach is dynamic: they depend on the execution history.
Floating Point Arithmetic Pipeline • Pipeline arithmetic units are usually found in very high speed computers • They are used to implement floating-point operations, multiplication of fixed-point numbers, and similar computations encountered in scientific problems
Floating Point Arithmetic Pipeline • Example for floating-point addition and subtraction • Inputs are two normalized floating-point binary numbers • X = A x 2^a • Y = B x 2^b • A and B are two fractions that represent the mantissas • a and b are the exponents • Try to design segments are used to perform the “add” operation
Floating Point Arithmetic Pipeline • Compare the exponents • Align the mantissas • Add or subtract the mantissas • Normalize the result
Floating Point Arithmetic Pipeline • X = 0.9504 x 103 and Y = 0.8200 x 102 • The two exponents are subtracted in the first segment to obtain 3-2=1 • The larger exponent 3 is chosen as the exponent of the result • Segment 2 shifts the mantissa of Y to the right to obtain Y = 0.0820 x 103 • The mantissas are now aligned • Segment 3 produces the sum Z = 1.0324 x 103 • Segment 4 normalizes the result by shifting the mantissa once to the right and incrementing the exponent by one to obtain Z = 0.10324 x 104