Download

1 / 59
590 likes | 679 Views
Discover the foundation of learning with linear neurons, adapted from Geoffrey Hinton's lectures and updated by N. Intrator in May 2007. Explore the application of logical operations and neural networks, such as the Perceptron model by Frank Rosenblatt, to categorize input vectors. Learn about weight adjustments and the iterative learning process to minimize discrepancies between desired and actual outputs. Follow a motivating example of solving linear constraints using neural networks and understand the principles of batch and online learning in linear neurons.

E N D
Learning with linear neurons Adapted from Lectures by Geoffrey Hinton and Others Updated by N. Intrator, May 2007
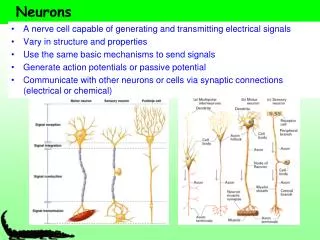
Truth Table for Logical AND x y x & y 0 0 0 1 1 0 1 1 output inputs Prehistory W.S. McCulloch & W. Pitts (1943). “A logical calculus of the ideas immanent in nervous activity”, Bulletin of Mathematical Biophysics, 5, 115-137. • This seminal paper pointed out that simple artificial “neurons” could be made to perform basic logical operations such as AND, OR and NOT. x * +1 y * +1 if sum<0 : 0 else : 1 x+y-2 0 1 * -2 0 0 1 sum output inputs weights
Truth Table for Logical OR x y x | y 0 0 0 1 1 0 1 1 output inputs Nervous Systems as Logical Circuits Groups of these “neuronal” logic gates could carry out any computation, even though each neuron was very limited. • Could computers built from these simple units reproduce the computational power of biological brains? • Were biological neurons performing logical operations? x * +1 y * +1 if sum<0 : 0 else : 1 x+y-1 0 1 * -1 1 1 1 sum output inputs weights
Σxi wi sum weights inputs * output The Perceptron Frank Rosenblatt (1962). Principles of Neurodynamics, Spartan, New York, NY. Subsequent progress was inspired by the invention of learning rules inspired by ideas from neuroscience… Rosenblatt’s Perceptron could automatically learn to categorise or classify input vectors into types. It obeyed the following rule: If the sum of the weighted inputs exceeds a threshold, output 1, else output -1. 1 if Σ inputi * weighti > threshold -1 if Σ inputi * weighti < threshold
The neuron has a real-valued output which is a weighted sum of its inputs The aim of learning is to minimize the discrepancy between the desired output and the actual output How de we measure the discrepancies? Do we update the weights after every training case? Why don’t we solve it analytically? Linear neurons weight vector input vector Neuron’s estimate of the desired output
A motivating example • Each day you get lunch at the cafeteria. • Your diet consists of fish, chips, and beer. • You get several portions of each • The cashier only tells you the total price of the meal • After several days, you should be able to figure out the price of each portion. • Each meal price gives a linear constraint on the prices of the portions:
Two ways to solve the equations • The obvious approach is just to solve a set of simultaneous linear equations, one per meal. • But we want a method that could be implemented in a neural network. • The prices of the portions are like the weights in of a linear neuron. • We will start with guesses for the weights and then adjust the guesses to give a better fit to the prices given by the cashier.
The cashier’s brain Price of meal = 850 Linear neuron 150 50 100 2 5 3 portions of fish portions of chips portions of beer
A model of the cashier’s brainwith arbitrary initial weights Price of meal = 500 • Residual error = 350 • The learning rule is: • With a learning rate of 1/35, the weight changes are +20, +50, +30 • This gives new weights of 70, 100, 80 • Notice that the weight for chips got worse! 50 50 50 2 5 3 portions of fish portions of chips portions of beer
Behavior of the iterative learning procedure • Do the updates to the weights always make them get closer to their correct values?No! • Does the online version of the learning procedure eventually get the right answer?Yes, if the learning rate gradually decreases in the appropriate way. • How quickly do the weights converge to their correct values?It can be very slow if two input dimensions are highly correlated(e.g. ketchup and chips). • Can the iterative procedure be generalized to much more complicated, multi-layer, non-linear nets?YES!
Deriving the delta rule • Define the error as the squared residuals summed over all training cases: • Now differentiate to get error derivatives for weights • Thebatchdelta rule changes the weights in proportion to theirerror derivativessummed over all training cases
The error surface • The error surface lies in a space with a horizontal axis for each weight and one vertical axis for the error. • For a linear neuron, it is a quadratic bowl. • Vertical cross-sections are parabolas. • Horizontal cross-sections are ellipses. w1 E w2
Batch learning does steepest descent on the error surface Online learning zig-zags around the direction of steepest descent Online versus batch learning constraint from training case 1 w1 w1 constraint from training case 2 w2 w2
Adding biases • A linear neuron is a more flexible model if we include a bias. • We can avoid having to figure out a separate learning rule for the bias by using a trick: • A bias is exactly equivalent to a weight on an extra input line that always has an activity of 1.
Preprocessing the input vectors • Instead of trying to predict the answer directly from the raw inputs we could start by extracting a layer of “features”. • Sensible if we already know that certain combinations of input values would be useful • The features are equivalent to a layer of hand-coded non-linear neurons. • So far as the learning algorithm is concerned, the hand-coded features are the input.
Is preprocessing cheating? • It seems like cheating if the aim to show how powerful learning is. The really hard bit is done by the preprocessing. • Its not cheating if welearnthe non-linear preprocessing. • This makes learning much more difficult and much more interesting.. • Its not cheating if we use a very big set of non-linear features that is task-independent. • SupportVectorMachines make it possible to use a huge number of features without much computation or data.
Statistical and ANN Terminology • A perceptron model with a linear transfer function is equivalent to a possibly multiple or multivariate linear regression model [Weisberg 1985; Myers 1986]. • A perceptron model with a logistic transfer function is a logistic regression model [Hosmer and Lemeshow 1989]. • A perceptron model with a threshold transfer function is a linear discriminant function [Hand 1981; McLachlan 1992; Weiss and Kulikowski 1991]. An ADALINE is a linear two-group discriminant.
Transfer functions • Determines the output from a summation of the weighted inputs of a neuron. • Maps any real numbers into a domain normally bounded by 0 to 1 or -1 to 1, i.e. squashing functions. Most common functions are sigmoid functions:
Healthcare Applications of ANNs • Predicting/confirming myocardial infarction, heart attack, from EKG output waves • Physicians had a diagnostic sensitivity and specificity of 73.3% and 81.1% while ANNs performed 96.0% and 96.0% • Identifying dementia from EEG patterns, performed better than both Z statistics and discriminant analysis; better than LDA for (91.1% vs. 71.9%) in classifying with Alzheimer disease. • Papnet: A Pap Smear screening system by Neuromedical Systems in used by US FDA • Predict mortality risk of preterm infants, screening tool in urology, etc.
Classification Applications of ANNs • Credit Card Fraud Detection: AMEX, Mellon Bank, Eurocard Nederland • Optical Character Recognition (OCR): Fax Software • Cursive Handwriting Recognition: Lexicus • Petroleum Exploration: Arco & Texaco • Loan Assessment: Chase Manhattan for vetting commercial loans • Bomb detection by SAIC
Time Series Applications of ANNs • Trading systems: Citibank London (FX). • Portfolio selection and Management: LBS Capital Management (>US$1b), Deere & Co. pension fund (US$100m). • Forecasting weather patterns & earthquakes. • Speech technology: verification and generation. • Medical: Predicting heart attacks from EKGs and mental illness from EEGs.
Advantages of Using ANNs • Works well with large sets of noisy data, in domains where experts are unavailable or there are no known rules. • Simplicity of using it as a tool • Universal approximator. • Does not impose a structure on the data. • Possible to extract rules. • Ability to learn and adapt. • Does not require an expert or a knowledge engineer. • Well suited to non-linear type of problems. • Fault tolerant
Problem with the Perceptron • Can only learn linearly separable tasks. • Cannot solve any ‘interesting problems’-linearly nonseparable problems e.g. exclusive-or function (XOR)-simplest nonseparable function.
The Fall of the Perceptron Marvin Minsky & Seymour Papert (1969). Perceptrons, MIT Press, Cambridge, MA. • Before long researchers had begun to discover the Perceptron’s limitations. • Unless input categories were “linearly separable”, a perceptron could not learn to discriminate between them. • Unfortunately, it appeared that many important categories were not linearly separable. • E.g., those inputs to an XOR gate that give an output of 1 (namely 10 & 01) are not linearly separable from those that do not (00 & 11).
Successful Footballers Academics Few Hours in the Gym per Week Many Hours in the Gym per Week Unsuccessful The Fall of the Perceptron …despite the simplicity of their relationship: Academics = Successful XOR Gym In this example, a perceptron would not be able to discriminate between the footballers and the academics… This failure caused the majority of researchers to walk away.
The simple XOR example masks a deeper problem ... 1. 2. 3. 4. Consider a perceptron classifying shapes as connected or disconnected and taking inputs from the dashed circles in 1. In going from 1 to 2, change of right hand end only must be sufficient to change classification (raise/lower linear sum thru 0) Similarly, the change in left hand end only must be sufficient to change classification Therefore changing both ends must take the sum even further across threshold Problem is because of single layer of processing local knowledge cannot be combined into global knowledge. So add more layers ...
THE PERCEPTRON CONTROVERSY There is no doubt that Minsky and Papert's book was a block to the funding of research in neural networks for more than ten years. The book was widely interpreted as showing that neural networks are basically limited and fatally flawed. What IS controversial is whether Minsky and Papert shared and/or promoted this belief ? Following the rebirth of interest in artificial neural networks, Minsky and Papert claimed that they had not intended such a broad interpretation of the conclusions they reached in the book Perceptrons. However, Jianfeng was present at MIT in 1974, and reached a different conclusion on the basis of the internal reports circulating at MIT. What were Minsky and Papert actually saying to their colleagues in the period after the publication of their book?
Minsky and Papert describe a neural network with a hidden layer as follows: • GAMBA PERCEPTRON: A number of linear threshold systems have their outputs connected to the in- puts of a linear threshold system. Thus we have a linear threshold function of many linear threshold functions. • Minsky and Papert then state: • Virtually nothing is known about the computational capabilities of this latter kind of machine. We believe that it can do little more than can a low order perceptron. (This, in turn, would mean, roughly, that although they could recognize (sp) some relations between the points of a picture, they could not handle relations between such relations to any significant extent.) That we cannot understand mathematically the Gamba perceptron very well is, we feel, symptomatic of the early state of development of elementary computational theories.
The input is recoded using hand-picked features that do not adapt. Only the last layer of weights is learned. The output units are binary threshold neurons and are learned independently. The connectivity of a perceptron output units non-adaptive hand-coded features input units
Binary threshold neurons • McCulloch-Pitts (1943) • First compute a weighted sum of the inputs from other neurons • Then output a 1 if the weighted sum exceeds the threshold. 1 1 if y 0 0 otherwise z threshold
The perceptron convergence procedure • Add an extra component with value 1 to each input vector. The “bias” weight on this component is minus the threshold. Now we can forget the threshold. • Pick training cases using any policy that ensures that every training case will keep getting picked • If the output unit is correct, leave its weights alone. • If the output unit incorrectly outputs a zero, add the input vector to the weight vector. • If the output unit incorrectly outputs a 1, subtract the input vector from the weight vector. • This is guaranteed to find a suitable set of weightsif any such set exists.
Imagine a space in which each axis corresponds to a weight. A point in this space is a weight vector. Each training case defines a plane. On one side of the plane the output is wrong. To get all training cases right we need to find a point on the right side of all the planes. Weight space wrong right bad weights good weights right wrong an input vector o origin
Consider the squared distance between any satisfactory weight vector and the current weight vector. Every time the perceptron makes a mistake, the learning algorithm moves the current weight vector towards all satisfactory weight vectors (unless it crosses the constraint plane). So consider “generously satisfactory” weight vectors that lie within the feasible region by a margin at least as great as the largest update. Every time the perceptron makes a mistake, the squared distance to all of these weight vectors is always decreased by at least the squared length of the smallest update vector. Why the learning procedure works margin right wrong
What perceptrons cannot do Data Space • The binary threshold output units cannot even tell if two single bit numbers are the same! Same: (1,1) 1; (0,0) 1 Different: (1,0) 0; (0,1) 0 • The following set of inequalities is impossible: 0,1 1,1 weight plane output =1 output =0 1,0 0,0 The positive and negative cases cannot be separated by a plane
What can perceptrons do? • They can only solve tasks if the hand-coded features convert the original task into a linearly separable one. How difficult is this? • The N-bit parity task : • Requires N features of the form: Are at least m bits on? • Each feature must look atallthe components of the input. • The 2-D connectedness task • requires an exponential number of features!
There is a simple solution that requires N hidden units. Each hidden unit computes whether more than M of the inputs are on. This is a linearly separable problem. There are many variants of this solution. It can be learned. It generalizes well if: The N-bit even parity task +1 output -2 +2 -2 +2 >0 >1 >2 >3 1 0 1 0 input
Even for simple line drawings, there are exponentially many cases. Removing one segment can break connectedness But this depends on the precise arrangement of the other pieces. Unlike parity, there are no simple summaries of the other pieces that tell us what will happen. Connectedness is easy to compute with an iterative algorithm. Start anywhere in the ink Propagate a marker See if all the ink gets marked. Why connectedness is hard to compute
What kind of features are required to distinguish two different patterns of 5 pixels independent of position and orientation? Do we need to replicate T and C templates across all positions and orientations? Looking at pairs of pixels will not work Looking at triples will work if we assume that each input image only contains one object. Distinguishing T from C in any orientation and position Replicate the following two feature detectors in all positions - + - + + + If any of these equal their threshold of 2, it’s a C. If not, it’s a T.
Beyond perceptrons • Need tolearnthe features, not just how to weight them to make a decision. This is a much harder task. • We may need to abandon guarantees of finding optimal solutions. • Need to make use ofrecurrentconnections, especially formodeling sequences. • The network needs a memory (in the activities) for events that happened some time ago, and we cannot easily put an upper bound on this time. • Engineers call this an “Infinite Impulse Response” system. • Long-term temporal regularities are hard to learn. • Need to learn representationswithout a teacher. • This makes it much harder to define what the goal of learning is.
Beyond perceptrons • Need to learn complexhierarchicalrepresentations for structures like: “John was annoyed that Mary disliked Bill.” • We need to apply the same computational apparatus to the embedded sentence as to the whole sentence. • This is hard if we are using special purpose hardware in which activities of hardware units are the representations and connections between hardware units are the program. • We must somehow traverse deep hierarchies using fixed hardware and sharing knowledge between levels.
Sequential Perception • We need to attend to one part of the sensory input at a time. • We only have high resolution in a tiny region. • Vision is a very sequential process (but the scale varies) • We do not do high-level processing of most of the visual input (lack of motion tells us nothing has changed). • Segmentation and the sequential organization of sensory processing are often ignored by neural models. • Segmentation is a very difficult problem • Segmenting a figure from its background seems very easy because we are so good at it, but its actually very hard. • Contours sometimes have imperceptible contrast, but we still perceive them. • Segmentation often requires a lot of top-down knowledge.
Fisher Linear Discrimination • Lower the problem from multi-dimensional to single-dimensional • Let ‘v’ be a vector in our space • Project the data on the vector ‘v’ • Estimate the ‘scatterness’ of the data as projected on ‘v’ • Use this ‘v’ to create a classifier
Fisher Linear Discrimination • Suppose we are in a 2D space • Which of the three vectors is an optimal ‘v’?
Fisher Linear Discrimination • The optimal vector maximizes the ratio of between-group-sum-of-squares to within-group-sum-of-squares, denoted between within within
Fisher Linear Discrimination Suppose a case two classes • Mean of these classes samples: • Mean of the projected samples: • ‘Scatterness’ of the projected samples: • Criterion function:
Fisher Linear Discrimination • Criterion function should be maximized • Present J as a function of a vector ‘v’
Fisher Linear Discrimination • The matrix version of the criterion works the same for more than two classes • J(v) is maximized when
Fisher Linear Discrimination Classification of a new observation ‘x’: • Let the class of ‘x’ be the class whose mean vector is closest to ‘x’ in terms of the discriminant variables • In other words, the class whose mean vector’s projection on ‘v’ is the closest to the projection of ‘x’ on ‘v’
A Regularized Fisher LDA • Swcan be singular (inaccurate inversion) • Regularization:Swreg = Sw + λ*I • (Ridge-regression) • Adding to the standard deviation (diagonal) a compensation of the noise -λ • Choosingλas a percentile of the eigenvalues ofSw • “λ-FLDA”
Linear regression 40 26 24 Temperature 22 20 20 30 40 20 30 20 10 0 10 0 10 20 0 0 Given examples given a new point Predict