Download
1 / 29
290 likes | 459 Views
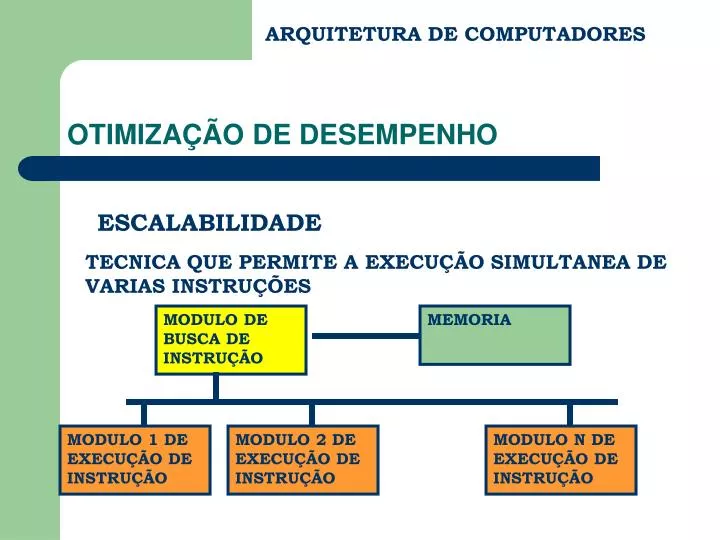
ARQUITETURA DE COMPUTADORES. OTIMIZAÇÃO DE DESEMPENHO. ESCALABILIDADE. TECNICA QUE PERMITE A EXECUÇÃO SIMULTANEA DE VARIAS INSTRUÇÕES. MODULO DE BUSCA DE INSTRUÇÃO. MEMORIA. MODULO 1 DE EXECUÇÃO DE INSTRUÇÃO. MODULO 2 DE EXECUÇÃO DE INSTRUÇÃO. MODULO N DE EXECUÇÃO DE INSTRUÇÃO.

E N D
ARQUITETURA DE COMPUTADORES OTIMIZAÇÃO DE DESEMPENHO ESCALABILIDADE TECNICA QUE PERMITE A EXECUÇÃO SIMULTANEA DE VARIAS INSTRUÇÕES MODULO DE BUSCA DE INSTRUÇÃO MEMORIA MODULO 1 DE EXECUÇÃO DE INSTRUÇÃO MODULO 2 DE EXECUÇÃO DE INSTRUÇÃO MODULO N DE EXECUÇÃO DE INSTRUÇÃO
ARQUITETURA DE COMPUTADORES ESCALABILIDADE CPU ( NÃO ESCALAR) REG A REG B REG C REG D REG T1 REG T2 ALU MEM PROGRAMA ADD A,B ADD C,D MEM CONTROLE T1 <- A T2 <- B A <- SALU , SOMA T1 <- C T2 <- D C <- SALU , SOMA MEM PROGRAMA ADD A,B ADD C,A MEM CONTROLE T1 <- A T2 <- B A <- SALU , SOMA T1 <- C T2 <- A C <- SALU , SOMA
ARQUITETURA DE COMPUTADORES ESCALABILIDADE 2 MEM PROGRAMA ADD A,B ADD C,D CPU ( ESCALAR) REG T12 REG T22 ALU2 MEM CONTROLE C2<- C, D2<-D T12 <- C2 T22 <- D2 C2 <- SALU1 , SOMA C <- C2 MEM CONTROLE A1<- A, B1<-B T11 <- A1 T21 <- B1 A1 <- SALU1 , SOMA A <- A1 REG A2 REG B2 REG C2 REG D2 REG A REG B REG C REG D REG A1 REG B1 REG C1 REG D1 REG T11 REG T21 ALU1 20% MELHOR
ARQUITETURA DE COMPUTADORES ESCALABILIDADE 2 SOFTWARE NÃO OTIMIZADO RODANDO EM UMA CPU OTIMIZADA PODE TER UM DESEMPENHO PIOR!!! MEM PROGRAMA ADD A,B ADD C,A CPU ( ESCALAR) REG T12 REG T22 ALU2 REG A2 REG B2 REG C2 REG D2 MEM CONTROLE A1<- A,B1 <-B T11 <- A1 T21 <- B1 A1 <- SALU1 , SOMA A<- A1 C1<- C,D1 <´D T11 <- C1 T21 <- D1 C1 <- SALU1 , SOMA C<- C1 REG A REG B REG C REG D REG A1 REG B1 REG C1 REG D1 REG T11 REG T21 ALU1 NÃO PODEM SER EXECUTADAS SIMULTANEAMENTE
ARQUITETURA DE COMPUTADORES EXECUÇÃO FORA DE ORDEM EXISTINDO MAIS DE UM MODULO, NÃO SE DEVE DEIXAR NENHUM OCIOSO. EXEMPLO COM ESCALABILIDADE 2 PROGR. ADD A,B ADD C,A ADD D,D 1 MODULO 1 MODULO 1 3 MODULO 2 2 t EXECUÇÃO FOI FORA DE ORDEM, MAIS OS RESULTADOS DEVEM SER ORDENADOS
ARQUITETURA DE COMPUTADORES PARALELISMO NO PROCESSAMENTO DE DADOS MOTIVAÇÃO: PROCESSAMENTO DE IMAGENS 3 0 2 1 1 0 3 6 5 6 1 2 1 2 3 2 2 1 REGISTRADORES ESPECIAIS 3 = 3 x 1 + 0 x 3 3 0 3 0 X 6 = 3 x 2 + 0 x 2 1 3 2 2 INSTR. ESPECIAL: UMA UNICA INSTRUÇÃO TRABALHANDO COM VARIOS PARES DE OPERANDOS SIMULTANEAMENTE 3 0 6 0
ARQUITETURA DE COMPUTADORES PARALELISMO NO PROCESSAMENTO DE DADOS IMPLEMENTAÇÃO CRIAÇÃO DE UM NOVO CONJUNTO DE INSTRUÇÕES. INSTRUÇÕES QUE POSSAM TRABALHAR COM, POR EXEMPLO, ATÉ 4 PARES DE OPERANDOS AO MESMO TEMPO.INSTRUÇÕES QUE POSSAM TRABALHAR COM BYTES, WORDS E D-WORDS, COM ARITMETICA DE SATURAÇÃO E TRUNCAMENTO. CRIAÇÃO DE UM NOVO CONJUNTO DE REGISTRADORES. CRIAÇÃO DE UM NOVO CONJUNTO DE OPERADORES.
ARQUITETURA DE COMPUTADORES PARALELISMO NO PROCESSAMENTO DE DADOS 32 BITS INSTRUÇÕES DO TIPO SIMD OPERANDO COM 4 PARES DE BYTES OPERANDO COM 2 PARES DE WORDS OPERANDO COM 1 PAR DE D-WORDS REG1 REG2 REG3 REGN
ARQUITETURA DE COMPUTADORES PARALELISMO NO PROCESSAMENTO DE DADOS REGISTRADOR REGISTRADOR ALU3 ALU2 ALU1 ALU0 DECOD. INSTRUÇÃO NOVOS OPERADORES
ARQUITETURA DE COMPUTADORES PARALELISMO NO PROCESSAMENTO DE DADOS ARITMETICA DE SATURAÇÃO E TRUNCAMENTO TRUNCAMENTO COR CODIGO TRUNCAMENTO 11111111 11111110 + 2 SATURAÇÃO 10101111 00000000
ARQUITETURA DE COMPUTADORES MICROROTINAS UMA MICROROTINA É UM MICROPROGRAMA QUE PODE SER REUTILIZADO MAIS DE UMA VEZ POR OUTRO MICROPROGRAMA OU QUE PODE SER UTILIZADO POR VARIOS OUTROS MICROPROGRAMAS. VANTAGEM: ECONOMIZA ESPAÇO NA MEM. DA UNID. DE CONTROLE DESVANTAGEM: PIORA O DESEMPENHO
ARQUITETURA DE COMPUTADORES MICROROTINAS EXEMPLO: UMA MICROROTINA QUE IMPLEMENTA RASC <- AX – BX É UTILIZADA COMO PARTE DO MICROPROGRAMA QUE REALIZA RASC <- MAX(AX,BX) E DO MICROPROGRAMA QUE REALIZA AX<- AX –BX NA CPU DO TIPO 8088 MICROPROGRAMA AX <- AX - BX MICROROTINA RASC <- MAX(AX,BX) CHAMADA DA uROTINA AL <- RASCL AH <- RASCH MICROROTINA RASC <- AX - BX CHAMADA uROTINA RASCL <-AL RASCH <- AH, FS=0? RASCL <- BL FS =0 ? RASCH <- BH T1 < - AL T2 <- BL RASCL <- SALU, FC <- BORROW, SUB T1 < - AH T2 <- BH RASCH <- SALU, FC <- BORROW, SUBB RET
ARQUITETURA DE COMPUTADORES MICROROTINAS EXERCICIO FAÇA AS ALTERAÇÕES NA MEMORIA E NO SEQUENCIADOR DA UNIDADE DE CONTROLE DE MODO QUE UM MICROPROGRAMA POSSA UTILIZAR UMA UNICA MICROROTINA DISPONIBILIZADA
ARQUITETURA DE COMPUTADORES MICROROTINAS ANINHADAS EXEMPLO UM MICROPROGRAMAQUE REALIZA AX <- MAX(AX,BX) CHAMA UMA MICROROTINA QUE IMPLEMENTA RASC <- MAX(AX,BX) QUE POR SUA VEZ CHAMA UMA MICROROTINA QUE IMPLEMENTA RASC <- AX -BX MICROPROGRAMA AX <- MAX(AX,BX) MICROROTINA RASC <- MAX(AX,BX) MICROROTINA RASC <- AX - BX 2 1 CHAMADA DA uROTINA AL <- RASCL AH <- RASCH CHAMADA uROTINA RASCL <-AL RASCH <- AH, FS=0? RASCL <- BL FS =0 ? RASCH <- BH RET T1 < - AL T2 <- BL RASCL <- SALU, FC <- BORROW, SUB T1 < - AH T2 <- BH RASCH <- SALU, FC <- BORROW, SUBB RET 4 3 EXERCICIO: FAÇA ALTERAÇÕES MA MEM. E NO SEQUENCIADOR DA UNID. DE CONTROLE DE MODO QUE SEJAM PERMITIDAS 3 MICROROTINAS E QUE ELAS POSSAM SER ANINHADAS.
ARQUITETURA DE COMPUTADORES SINAIS ADICIONAIS NO BARRAMENTO DE CONTROLE BREQ (BUS REQUEST) ALGUMAS CPU´s SÃO PROJETADAS PARA TRABALHAR EM UM AMBIENTE COM MULTIPROCESSAMENTO E MEMORIA COMPARTILHADA CPU1 CPU2 CPU3 CPUN BUS DE END., DADO E CONTROLE BUS DE END., DADO E CONTROLE MEMORIA PROBLEMA: “BRIGA PARA ACESSAR A MEMORIA”
ARQUITETURA DE COMPUTADORES SINAIS ADICIONAIS NO BARRAMENTO DE CONTROLE PARA ACABAR COM O CONFLITO É NECESSARIO UM ARBITRADOR DE USO DO BARRAMENTO BREQ1 ARBITRADOR BREQN BREQ2 BREQ3 CPU1 CPU2 CPU3 CPUN MEMORIA O ARBITRADOR RECEBE PEDIDOS DE BUS (SIMULTANEOS OU NÃO) E CONECTA A MEM. COM A CPU DE MAIOR PRIORIDADE QUE FEZ PEDIDO DE USO DE BUS. AS OUTRAS CPU`s, QUE TAMBEM FIZERAM UM PEDIDO, FICAM AGUARDANDO A SUA VEZ DE USAR O BUS
ARQUITETURA DE COMPUTADORES SINAIS ADICIONAIS NO BARRAMENTO DE CONTROLE LOCK LOCKN ARBITRADOR LOCK1 LOCK2 LOCK3 BREQ1 BREQN BREQ2 BREQ3 CPU1 CPU2 CPU3 CPUN MEMORIA SEMAFORO REGISTRO COMPARTILHAMENTO DE DADOS
ARQUITETURA DE COMPUTADORES SINAIS ADICIONAIS NO BARRAMENTO DE CONTROLE LOCK PARA ACESSAR A AREA DE MEMORIA CHAMADA DE REGISTRO, ASSOCIADA AO SEMAFORO, UMA CPU DEVE LER O SEMAFORO, VERIFICAR SE ELE ESTA LIVRE E COLOCA-LO COMO OCUPADO , PARA ENTÃO ACESSAR A AREA DE REGISTRO SEM CONCORRENCIA. OUTRA CPU SE QUISER ACESSAR A AREA COMUM DE REGISTRO DEVE, ANTES, LER O SEMAFORO,QUE, NO CASO,ESTARÁ NO ESTADO OCUPADO. ISTO FARÁ COM QUE ESTA OUTRA CPU AGUARDE SUA VEZ. A OPERAÇÃO, POR PARTE DA CPU, DE LER O ESTADO DO SEMAFORO, ALTERAR O ESTADO E ESCREVER O ESTADO ALTERADO NA MEMORIA DEVE SER ATOMICA (INDIVISIVEL), PARA EVITAR QUE ENQUANTO ELA ESTIVER ALTERANDO INTERNAMENTE O ESTADO DO SEMAFORO, POR CONSEGUINTE O BUS ESTARÁ LIVRE, OUTRA CPU TENTE LER O SEMAFORO PARA, ENTÃO, TAMBEM ALTERA-LO, E ACESSAR , TAMBEM, A AREA DE REGISTRO “SIMULTANEAMENTE”.
ARQUITETURA DE COMPUTADORES SINAIS ADICIONAIS NO BARRAMENTO DE CONTROLE LOCK ACESSO ATOMICO CPU1 LÊ SEMAFORO (USA O BUS) CPU1 ALTERA SEMAFORO (NÃO USA O BUS) CPU1 ESCR. NO SEMAFORO ( USA O BUS) t ACESSO NÃO ATOMICO CPU1 LÊ SEMAFORO (USA O BUS) CPU1 ALTERA SEMAFORO (NÃO USA O BUS) CPU1 ESCR. NO SEMAFORO ( USA O BUS) CPU2 LÊ SEMAFORO ( USA O BUS) CPU2 ALTERA SEMAFORO (NÃO USA O BUS) CPU2 ESCR. NO SEMAF. ( USA O BUS) PARA “ATOMIZAR” O ACESSO A MEM. FOI CRIADO O SINAL LOCK (CADEADO). ENQUANTO O LOCK DA CPU QUE GANHOU O BUS PERMANECER ATIVO, O ARBITRADOR NÃO CEDE O BUS PARA OUTRA CPU, MESMO QUE A QUE OBTEVE O BUS NÃO O ESTEJA UTILIZANDO NO MOMENTOO.
ARQUITETURA DE COMPUTADORES SINAIS DA CPU VISTOS ATÉ AGORA CPU BUS END. BUS DADOS MEMRD MEMWR BREQ LOCK HOLD RESET HLDA CLK WAIT
ARQUITETURA DE COMPUTADORES CPU CISC x CPU RISC CISC: COMPUTADOR COM CONJUNTO DE INSTRUÇÕES COMPLEXAS CPU SUBSIST. CONTR. SUBSIST. DADOS SEQUENCIADOR MEMORIA CONTR. IR
ARQUITETURA DE COMPUTADORES CPU CISC x CPU RISC RISC: COMPUTADOR COM CONJUNTO DE INSTRUÇÕES SIMPLES CPU SUBSIST. CONTR. SUBSIST. DADOS MAQ. DE ESTADOS CONVENCIONAL DECODIFICADOR IR
ARQUITETURA DE COMPUTADORES CPU CISC x CPU RISC CISC INSTRUÇÕES COMPLEXAS PROGRAMAS MENORES RISC INSTRUÇÕES SIMPLES MAIOR PARALELISMO NA EXECUÇÃO DE INSTRUÇÕES MELHOR DESEMPENHO
ARQUITETURA DE COMPUTADORES TRABALHO:PROJETO DE UM MICROCONTROLDOR PIC VDD PB0 VSS PB1 CLKIN PB2 CLKOUT PB3 PA0 PB4 PA1 PB5 PA2 PB6 PA3 PB7 PA4 RESET
ARQUITETURA DE COMPUTADORES TRABALHO: PROJETO DE MICROCONTROLADOR PIC ESPECIFICAÇÃO: CPU: RISC MEMORIAS: NÃO VOLATIL PARA PROGRAMA VOLATIL PARA DADOS NÃO VOLATIL PARA DADOS NUMERO DE INSTUÇÕES: 35 PC: PC = PC +1 ; PC= END. DE ROTINA OU END. DE PROGRAMA; PC = END. DE RETORNO NUMERO DE BITS DA INSTUÇÃO : 16 INSTR. ARITM. E LOGICAS: ARQ(1) = ARQ(1) OP ARQ(I) OU ARQ(I) = ARQ(1) OP ARQ(I) I: 0,1...63 INSTRUÇÃO DE DADO IMEDIATO: ARQ(1) = DADO IMEDIATO FLAGS: C,Z,D(DECIMAL), E( MEM NÃO VOLATIL DE DADOS OCUPADA COM ESCRITA) BARRAMENTO DE DADOS : 8 BITS
ARQUITETURA DE COMPUTADORES TRABALHO: PROJETO DE MICROCONTROLADOR PIC • COMPONENTES: • MEMORIA DE PROGRAMA: 1K x 16 NÃO VOLATIL FLASH • MEMORIA DECODIFICADORA DE INSTRUÇÃO: 64 X 4O BITS • REGISTRADOR PARA PC: 10 BITS • MUX 4x 1: 10 BITS • PILHA LIFO: 8 X 12 BITS , RDPILHA, WRPILHA • MEMORIA DE DADOS VOLATIL( ARQUIVO DE REGISTRADORES 1 ENTRADA E 2 SAIDAS): 64 X 8, WARQ, 1 SAIDA SEMPRE FIXA • 7. ALU: 8 BITS , 16 OPERAÇÕES • 8. MEMORIA NÃO VOLATIL : 64 X 8. RD, WR(ESCRITA LENTA FLAG E), EEPROM • 9. REG END. MEM. NÃO VOLATIL: 8 BITS ARQ(62) • REG DADOS MEM. NÃO VOLATIL : 8 BITS ARQ(63) • PORTA A: 5 BITS ARQ(4) • PORTA B : 8 BITS ARQ(5)
ARQUITETURA DE COMPUTADORES TRABALHO: PROJETO DE MICROCONTROLADOR PIC • PEDE-SE: • O PROJETO DO SUBSISTEMA DE DADOS E DO SUBSISTEMA DE CONTROLE • O PROJETO DO ARQUIVO DE REGISTRADORES • O CAMPO DE CONEXÃO COMPLETAMENTE DECODIFICADO • OBS: COMEÇANDO DO BIT 39, EM ORDEM ALFABETICA E COM A SEGUINTE NOTAÇÃO NOME DO BIT(E OU S) • O CAMPO DE OPERAÇÃO • OBS: CONTINUANDO A NUMERAÇÃO • O CAMPO DE SINAIS DE CONTROLE • OBS:CONTINUANDO A NUMERAÇÃO • 6. A MICROINSTRUÇÃO DA INSTRUÇÃO ARQ(1) = ARQ(1) + ARQ(6). EM CASOS DE NÃO IMPORTA, PREENCHA OS BITS COM ZEROS • 7. A MICROINSTRUÇÃO DE DESVIO INCONDICIONAL PARA O ENDEREÇO 047H • 8. O ACRESCIMO DE UM CIRCUITO E SEU RESPECTIVO CONTROLE DE MODO QUE INSTRUÇÕES DE DESVIO CONDICIONAL RELATIVAS AOS FLAGS C E Z POSSAM SER IMPLEMENTADAS
ARQUITETURA DE COMPUTADORES TRABALHO: PROJETO DE MICROCONTROLADOR PIC • PEDE-SE: • 9. O TCLK, SABENDO QUE O TEMPO DE ACESSO DO ARQ. DE REG´s É DE 30NS PARA LEITURA OU ESCRITA, O TEMPO DE RESPOSTA DA ALU É DE 30NS E O TEMPO DE ACESSO DA MEM. DE PROGRAMA É DE 60NS. • IMPLEMENTE UM PIPELINE, DE MODO QUE ENQUANTO UMA INSTRUÇÃO ESTIVER SENDO EXECUTADA, UMA OUTRA DEVE ESSTAR SENDO LIDA DA MEMORIADE PROGRAMA.QUAL É O NOVO PERIODO DE CLK? • AO SER DADO O RESET, QUAIS REGISTRADORES DEVEM SER INICIALIZADOS E COM QUE TIPO DE INFORMAÇÃO? • COM PIPELINE QUAL A TECNICA QUE DEVE SER UTILIZADA EM CASOS DE DESVIO, DELAY OU ABORTO ? JUSTIFIQUE. • O CIRCUITO QUE POSSIBILITA A IMPLEMENTAÇÃO DA TECNICA DE ABORTO.
ARQUITETURA DE COMPUTADORES TRABALHO: PROJETO DE MICROCONTROLADOR PIC 13. O TEMPO GASTO PARA EXECUTAR O PROGRAMA ABAIXO, SEM PIPELINE E COM PIPELINE, SABENDO QUE A(08) = 33H: W 20H A(07) W W A(08) + W BTFSC C (PULA PROXIMA INSTRUÇÃO SE O FLAG DE CARRY ESTIVER ZERADO) W # W A(08) W






















