Matrix multiplication implemented in data flow technology
170 likes | 327 Views
This paper presents an innovative approach to matrix multiplication leveraging data flow technology. Adopting a paradigm shift from control flow to data flow, the proposed method constructs a graph of computations where nodes act as deep pipelines. By optimizing chip utilization and parallelizing processes, we achieve significant acceleration in matrix multiplication, demonstrating execution times orders of magnitude faster than traditional methods on Intel Xeon processors. This approach finds applications in areas with large data sets, including bioinformatics and complex numerical simulations.

Matrix multiplication implemented in data flow technology
E N D
Presentation Transcript
Matrix multiplication implemented in data flow technology AleksandarMilinković Belgrade University, School of Electrical Engineering amilinko@gmail.com
Introduction • Problem with big data • Need to change computing paradigm • Data flow instead of control flow • Achieved by construction of graph • Graph nodes (vertices) perform computations • Each node is one deep pipeline
Dataflow computation • Dependencies are resolved at compile time • No new dependencies are made • The whole mechanism is in deep pipeline • Pipeline levels perform parallel computations • Data flow produces one result per cycle
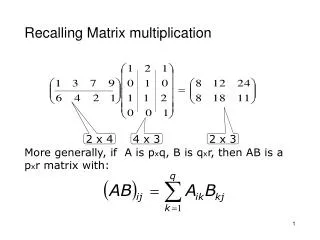
Matrix multiplication • Data flow doesn’t suit all situations • However, it is applicable in lot of cases: • Partial differential equations • 3D finite differences • Finite elements method • Problems in bioinformatics, etc. • Most of them contain matrix multiplications • Goal: realization on FPGA, using data flow
Project realizations • Two solutions: • Maximal utilization of on-chip matrix part • Matrices with small dimensions • Matrices with large dimensions • Multiplication using parallel pipelines
Good chip utilization A • Set of columns on the chip until they are fully used • Every pipe calculates 48 sums at the time • Equivalent to 2 processors with 48 cores • Additional parallelizationpossible
Good chip utilization A • Chip utilization and acceleration • LUTs: 195345/297600 (65,64%) • FFs: 290689/595200 (48.83%) • BRAMs: 778/1064 (73.12%) • DSPs: 996/2016 (49,40%) • Matrix: 2304 x 2304 • Intel: 42.5 s • MAX3: 2.38 s • Acceleration at kernel clock 75 MHz: ≈18 x
Good chip utilization B • Part of matrix Y is on chip during computation • Each pipe calculates 48 sums at the time • Equivalent to 2 processors with 48 cores
Good chip utilization B • Chip utilization and acceleration • LUTs: 201237/297600 (67,62%) • FFs: 302742/595200 (50.86%) • BRAMs: 782/1064 (73.50%) • DSPs: 1021/2016 (50,64%) • Matrix: 2304 x 2304 • Intel: 42.5 s • MAX3: 2.38 s • Acceleration at kernel clock 75 MHz: ≈ 18x • Matrix: 4608 x 4608 • Intel: 1034 s • MAX3: 58.41 s
Multiple parallel pipelines • Matrices are exclusively in a big memory • Each pipe calculates one sum at the time • Equivalent to 48 processors with one core
Multiple parallel pipelines • Chip utilization and acceleration • LUTs: 166328/297600 (55,89%) • FFs: 248047/595200 (41.67%) • BRAMs: 430/1064 (40.41%) • DSPs: 489/2016 (24,26%) • Matrix: 2304 x 2304 • Intel: 42.5 s • MAX3: 4,08 s • Acceleration at kernel clock 150 MHz: > 10x • Matrix: 4608 x 4608 • Intel: 1034 s • MAX3: 98,48 s
Comparison of solutions • First solution: • Good chip utilization • Shorter execution time • Drawback: matrices up to 8GB • Second solution: matricesup to 12GB • Drawback: longer execution time
Conclusions • Matrix multiplication is operation with complexity O(n3) • Part of complexity moved from time to space • That produces acceleration (shorter execution time) • Achieved by application of data flow technology • Developed using tool chain from Maxeler Technologies • Calculations order of magnitude faster than Intel Xeon
Matrix multiplication implemented in data flow technology AleksandarMilinković Belgrade University, School of Electrical Engineering amilinko@gmail.com