Download

1 / 22
220 likes | 297 Views
Investigating predictive resource performance and availability in distributed computing environments. Comparison of exponential, Pareto, and Weibull distributions. Evaluation through statistical tests and real-world scenarios.

E N D
Pick up the Pieces Average White Band
Modeling Resource Availability in Federated, Globally Distributed Computing Environments Rich Wolski Dan Nurmi UniversityofCalifornia,SantaBarbara John Brevik Wheaton College
Virtualization • Characterize resource performance in terms of predicted • Performance level (CPU fraction, BW, latency, available memory) • Availability duration • Classify resources in terms of • Equivalence • Statistical independence • From these, we can build “virtual machines” with provable performance and availability characteristics • Compute machines • Storage machines
Sample Based Techniques • Each measurement is modeled as a “sample” from a random variable • Time invariant • IID (independent, identically distributed) • Stationary (IID forever) • Well studied in the literature • Exponential distributions • Compose well • Memoryless • Popular in database and fault-tolerance communities • Pareto distributions • Potentially related to self-similarity • “heavy-tailed” implying non-predictability • Popular in networking, Internet, and Dist. System communities
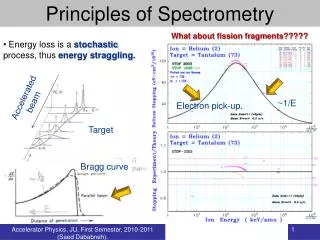
Why not Weibull? • Proposed originally by Waloddi Weibull in 1939 • PDF: f(x) = (a/b) * ( ((x - c)/b)^(a-1) ) * e^-(((x-c)/b)^a) • a is scale parameter > 0 • b is shape parameter > 0 • c is location parameter, (-inf,inf) • Used extensively in reliability engineering • Modeling lifetime distributions • Modeling extreme values in bounded cases • Not memoryless • F(x)x+k | k <> F(x) • Maximum Likelihood Estimation (MLE) of parameters is “hard” • Requires solution to non-linear system of equations or optimization problem • Sensitive to numerical stability of numerical algorithms
Our Initial Investigation • Measure availability as “lifetime” in a variety of settings • Student lab at UCSB, Condor pool • New NWS availability sensors • Data used in fault-tolerance communityfor checkpointing research • Predicting optimal checkpoint • Develop robust software for MLE parameter estimation • Automatically Fit Exponential, Pareto, and Weibull distributions • Compare the fits • Visually • Goodness of fit tests • Goal is to provide an automated mechanism for the NWS • Let the best distribution win
UCSB Student Computing Labs • Approximately 85 machines running Red Hat Linux located in three separate buildings • Open to all Computer Science graduate and undergraduates • Only graduates have building keys • Power-switch is not protected • Anyone with physical access to the machine can reboot it by power cycling it • Students routinely “clean off” competing users or intrusive processes to gain better performance response • NWS deployed and monitoring duration between restarts • Can we model the time-to-reboot?
Goodness of Fit • Kolmogorov-Smirnov (K-S) Goodness-of-Fit Test • P-values averaged over 1000 subsamples, each size 100 • Weibull: 0.36 • Exponential: 2 x 10^-5 • Pareto: 5 x 10^-4 • Anderson-Darling (A-D) Goodness-of-Fit Test • P-values averaged over 1000 subsamples, each size 100 • Weibull: 0.07 • Exponential: 0 • Pareto: 0 • At .95 significance level, reject null hypothesis for both Exponential and Pareto.
Condor • Cycle harvesting system (M. Livny, U. Wisconsin) • Workstations in a “pool” run the (trusted) Condor daemons • Each machine agrees to contribute a machine by installing and running Condor • Condor users submit job-control scripts to a batch queue • When a machine becomes “idle,” Condor schedules a waiting job • Machine owners specify what “idle” and “busy” mean • When a machine running a Condor job becomes “busy” • Job is checkpointed and requeued (standard universe) • Job is terminated (vanilla universe) • NWS sensor uses vanilla universe and records process lifetime • Unknown and constantly changing number of workstations in UWisc Condor Pool (> 1500) • 210 machines used by Condor for NWS sensor
Long, Muir, Golding Internet Survey (1995) • 1170 Hosts “across” the Internet in 1995 • Use response to rpc.statd (NFS daemon) as heartbeat • Long, Muir, Golding (UCSC, HP-labs) investigated exponentials as models for • Availability time • Downtime • Plank and Elwasif (UTK,1998) and Plank and Thomason (UTK, 2000) use data and exponentials as basis for checkpoint interval determination • All researchers conclude that data is not-well modeled by exponentials • No plausible distribution determined
If the Weibull Fits, Wear It • Three different availability surveys under three different sets of circumstances • UCSB Student Labs • Adversarial chaos • U. Wisc Condor Pool • Background cycle harvesting • Internet host survey • Convolution of host and network availability circa 1995 • In all three cases an MLE-fit Weibull is, by far, the best model • Visual and GOF evidence • Uncharacteristically, the assumptions for the model seem to hold • Stationarity and Independence
What Does This Mean for VGrADS? • If a continuous, closed form distribution is needed to model machine availability in federated distributed systems, a Weibull is probably the best choice • Empirical evidence from different scenarios makes bias unlikely • Weibulls were invented to model lifetimes • Why Should we Care? • Grid simulators • Probably useful to uGrid • Optimal Checkpoint scheduling • Paper in progress • Replication systems • Independence allows us to set the joint failure probability • It does not mean, that Weibulls are best for predicting availability • We can beat the distributional approach using a non-parametric method
Optimal Checkpoint Interval • Goal: minimize the expected execution time given checkpoint overhead cost C for each checkpoint • Old formula (Vaidya’s approximation) • eL(T+ C) (1 - LT) • L is failure rate (exponential) and T is optimal checkpoint interval • Our new formula based on Weibulls • (b + C + (b + C/b)a * a * b) / ((b + C/b)a * a • Two parameter Weibull with shape a and scale b • Conservative value • Optimal unconditional value • Conditional value may be possible • Requires application to recalculate interval at each checkpoint • Pie in the sky for now
Where we are and What’s Next • We have automatic fitting software prototyped for availability • Uses mathematica and/or matlab for solver quality • New NWS sensors going up on VGrADS testbed • We have non--parametric failure prediction software prototyped for individual machines • We need to • Integrate with NWS infrastructure • Develop VGrADS presentation layer • Develop classification software (independence and equivalence) • Translate results to time-series realm • Study time-to-availability problem • Develop optimal checkpoint interval determination service • Dan Nurmi, John Brevik
Thanks • Miron Livny and the Condor group at the University of Wisconsin • Darrell Long (UCSC) and James Plank (UTK) • UCSB Facilities Staff • NSF and DOE • nurmi@cs.ucsb.edu, jbrevik@wheatonma.edu, rich@cs.ucsb.edu