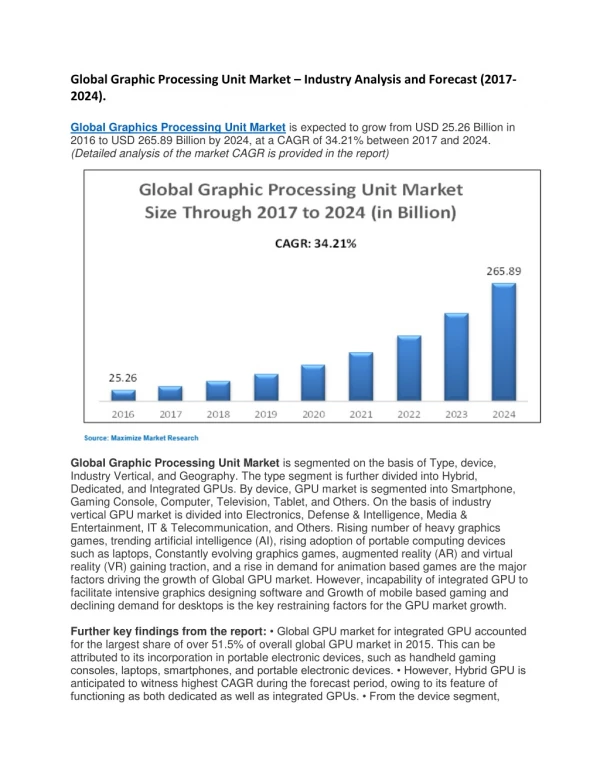
Graphics Processing Unit
Graphics Processing Unit. Joshua Reynolds Ted Gardner. GPUs - Background. Graphics are one of the most obvious examples of embarrasingly parallel computations Graphics cards use their own computational unit – the GPU GPUs have evolved to process graphics in a highly parallel way. Shaders.


Graphics Processing Unit
E N D
Presentation Transcript
Graphics Processing Unit Joshua Reynolds Ted Gardner
GPUs - Background Graphics are one of the most obvious examples of embarrasingly parallel computations Graphics cards use their own computational unit – the GPU GPUs have evolved to process graphics in a highly parallel way
Shaders • Shader types • Pixel/Fragment, Vertex, and Geometry • Unified shader model allows for a single shader to be used for any of the three types of shader • Functions • Read/write data from buffer • Perform arithmetic operations • Run entirely in parallel and can be very numerous • Example - Radeon HD 8xxx generation • Radeon HD 8350 has 80 unified shaders • Radeon HD 8970 has 2048 unified shaders
Example: NVIDIA Tesla • Up to 128 scalar processors • 12,000+ concurrent threads in flight • 470+ GFLOPS sustained performance • 100x or better speedups on GPUs
General Purpose Computing on GPU • GPUs were originally designed for manipulation of graphics • Shaders are programmable, and can be used for non-graphical data • Each shader can apply a kernel to a set of data (or to create a set of data) • Individual shaders are generally slower and more limited than CPU cores, but their parallel nature can give a dramatic speedup
Computational Uses • Conway's Game of Life • Video encoding/decoding • Fluid Simulation • N-Body Simulation • Fourier Transform • Computation of Voronoi Diagrams • Crack UNIX password encryption(PixelFlow SIMD graphics computer) • Computation of artificial neural networks • Bitcoin mining (SHA-256)
Programming Languages • CUDA (C, C++ and Fortran) • Third party wrappers for: Python, Perl, Java, Ruby, LUA, Haskell, MATLAB, IDL, Mathematica • OpenCL(C99) • Wrappers for: C++, C, Java, C#, Python, Ruby, Perl, Lisp, Haskell, Mathematica, R, MATLAB, Pascal
Vendors • Cuda • NVIDIA • OpenCL • NVIDIA • AMD • Apple • Intel • IBM • Portable OpenCL
Performance Tuning - Optimization • Populating all of the multiprocessors. • Being able to keep the cores busy with multithreading. • Optimizing device memory accesses for contiguous data, essentially optimizing for stride-1 memory accesses • Utilizing the software data cache to store intermediate results or to reorganize data that would otherwise require non-stride-1 device memory accesses. • Take advantage of asynchronous kernel launches by overlapping CPU computations with kernel execution
__kernelvoid composite(int currentPrime, __globalchar* output){ size_t i = currentPrime*currentPrime+currentPrime*get_global_id(0); output[i]='c'; } Example Kernel - Prime Number Sieve (OpenCL) • CPU sets up data as array of "P" characters • 'P' denotes prime • 'c' denotes composite • For each prime, the CPU instructs the GPU to apply the composite kernel on the array • Kernel applies marking on the array • get_global_id(0) - "Rank" of the process, transformed so that the GPU only needs to run the kernel on the factors of the prime
Test - O(n2) Description • List of n integers, numbered 0 to n • For each value in list, add up and store all the values in the list • Obviously not the best algorithm for summing values in parallel, but we're just trying to simulate O(n2) • CPU has 4 cores • GPU has 480 unified shaders • OpenCL applies same kernel to GPU and CPU
Test - O(n2) OpenCL kernel __kernelvoid sum(__globalint* input, __globalint* output){ size_t i = get_global_id(0); int out = 0; for(int j = 0; j < get_global_size(0); j++){ out += input[j]; } output[i] = out; }
Test - O(n2) Result
Cuda VS OpenCL • Cuda • More Popular • Large and mature libraries • Slightly faster • NVIDIA only • OpenCL • More Flexible Synchronization • Can enqueue regular CPU function pointers in its command queues • Run-time code generation built-in
Sources http://techreport.com/review/17670/nvidia-fermi-gpu-architecture-revealed/2 http://people.maths.ox.ac.uk/~gilesm/hpc/NVIDIA/NVIDIA_CUDA_Tutorial_No_NDA_Apr08.pdf Guodong Rong; Yang Liu; Wenping Wang; Xiaotian Yin; Gu, X.D.; Guo, Xiaohu, "GPU-Assisted Computation of Centroidal Voronoi Tessellation," Visualization and Computer Graphics, IEEE Transactions on , vol.17, no.3, pp.345,356, March 2011 http://www.computer.org/csdl/trans/tg/2011/03/ttg2011030345-abs.html http://www.math.psu.edu/qdu/Res/Pic/gallery3.html