Download

1 / 25
250 likes | 513 Views
Sub- Nyquist Sampling of Sparse Wideband Analog Signals. High Speed Digital Systems Laboratory-EE Faculty, Technion DSP & Support Change Detector Part Characterization Presentation Supervisors: Moshe Mishali & Ina Rivkin Students: Omer Kiselov & Daniel Primor.

E N D
Sub-Nyquist Sampling ofSparse Wideband Analog Signals High Speed Digital Systems Laboratory-EE Faculty, Technion DSP & Support Change Detector Part Characterization Presentation Supervisors: Moshe Mishali & Ina Rivkin Students: Omer Kiselov & Daniel Primor
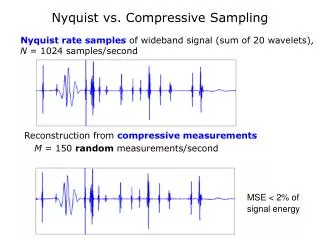
General Background-Theory • It is required to reconstruct wideband frequency limited signals by sampling at a lower rate than Nyquist rate. • The signal enters m different channels, is multiplied by periodic signal changing functions, low pass filtered and sampled. • The relation between the DTFT of the sampled signals and the CFT of the original signal is:
General Background-Theory • X-Fourier transform of the original signal • Y-Vector of DTFT of sampled signals in every channel. • fp-frequency of the mixing functions. • In order to reconstruct the signal, we have to find Z. This is done by using the pseudo-inverse. • Since for every frequency, Z is not zero only for some entries, we can calculate the support of Z and use only some of the columns of A while calculating the pseudo-inverse.
The Main Procedures • Memory access • Pseudo inverse • Renaming and replacing (for isolating y~ and for transpose actions) • Matrix multiplication • Summation (reduced time with heap) • Exporting DATA • Getting matrix A from memory • Getting support • Getting samples vector y • Extracting y~ from A and support • Performing manipulations on the matrix and vectors • Producing output of support change and digital samples Approved states that such an algorithm exists as standard in VHDL
Pseudo Inverse The Moore-Penrose pseudo-inverse is a way to solve a system of linear equations The solution to these equations is: The pseudo-inverse holds the hermitan terms defined normally by:
Matrix Decomposition • Matrix inversion is a difficult application to implement- hence we decided to break up and decompose the matrix into a few simpler matrixes , easier to invert. • There are several kinds of decomposition including the SVD (singular value decomposition) and the QR decomposition. • In order to maintain a simple implementation we chose the QR decomposition as a standard for our project.
The QR Decomposition For square matrixes And inverse using the QR decomposition:
First Algorithm • Normal way of implementing a pseudo-inverse via inversions of an ordinary matrix. We use the fact that is a square invertible matrix.
Second Algorithm-More Rows Than Columns • Suppose we have a matrix with more rows than columns. • R is of the same size as our matrix A-more rows than columns. • According to the definition of upper triangular matrixes, R has a square block and m-n rows of zeroes beneath it. • If this block is invertible, all we have to do is invert it and add m-n columns of zeroes to the right of this block in order to get the pseudo-inverse of R.
Complex Enhancement • The way we use to perform complex operations is to convert every complex number to a 2X2 matrix =>
Matlab Floating Point Simulation • Both algorithms produce zero error with Matlab’s own function pinv • Both algorithms use QR decomposition on a random matrix • All pseudo inverse matrixes are hermitian
Fixed Point Simulation Conclusions • The second algorithm is accurate and produces very small errors. For example, 16 bit representation leads to errors of 1E-4. • Therefore, we chose 16 bit representation, with 12 fraction bits. • Meanwhile, the first algorithm creates large errors even for a greater number of bits, like 32 bits, and is therefore less useful. This is derived from the matrix multiplication to get a square matrix. There is a shift in the dimensions which makes the error rise.
Functions To Be Implemented • Matrix multiplication • Divide • Square Root ? • Vector multiplication • Combinations • Transpose (via renaming)
There will probably be A controller too… DataPath
Amount Of Computation Units • There is a huge amount of multipliers in use since we perform matrix multiplication several times over. • To create a single serial datapath with parallel multipliers will take about 6600 multiplication units plus about 5 divide units. Its not possible since our hardware is limited to 880 units- hence we will create one 24X24 matrix multiplier (576 multiplications), 1 vector multiplier (for parallel implementation (unrolling) –24 mult units), one inverse unit which includes two divide unites and 50 multipliers. This is the best way we thought of to implement in parallel with every thing unrolled. • (the final score is 650 multipliers for parallel reasons and 2 divide units for norm calculations) • There is a real need for reservation stations in the HW.
The timing is not up to us since we don’t sample the signal. In clock cycles we need about a 1000. of course we can utilize the PLL to narrow is down.
OVERHEAD • The calculation is completely dependent on the size of the matrix and the scale of the units. • There is a trade off between timing and HW complexity. • There are HW limitations we must endure- they could be solved with more resources. • The PLL is dynamic and can shift the cycles throughout. Since the systems clock is not up to us we can virtually assume all kinds of time parameters… we cant give a accurate scheme regarding calculation.
Parallel Implementation Method • Loop Unrolling • Duff's Device • Software Pipelining- particularly the use of Out Of Order Execution is vital due to the amount of ALU actions.
Functional Hardware • Systolic arrays? • DRAM? • Pipeline (no other choice) • Super Scalar ?
Future Aspirations (possible timetable) • To Create a VHDL Simulation • To produce a possible parallel implementation in Hardware. • Build the DSP • Assume possible changes to increase parallelism. • Implement the memory.