Download

1 / 19
190 likes | 340 Views
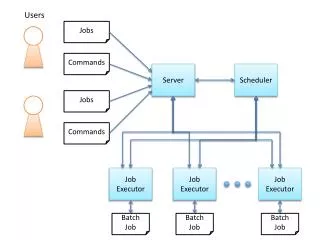
Grid Workflow Scheduler. 高橋 慧. Grid Scheduler とは. たくさんの逐次タスクを、グリッド上で効率よく簡単に実行するシステム タスク分配 ファイル転送 逐次のアプリケーションを書き換えることなく、手軽にグリッドの能力を発揮できる. 依存性のあるジョブへの対応. Workflow とは ( 特に Scientific Workflow) 複数のタスクの実行手順を記述したもの 依存性を持ち、主に DAG によって表される Workflow のスケジューリング 多くの考慮すべき条件 データの場所 (locality)

E N D
Grid Schedulerとは • たくさんの逐次タスクを、グリッド上で効率よく簡単に実行するシステム • タスク分配 • ファイル転送 • 逐次のアプリケーションを書き換えることなく、手軽にグリッドの能力を発揮できる
依存性のあるジョブへの対応 • Workflowとは (特にScientific Workflow) • 複数のタスクの実行手順を記述したもの • 依存性を持ち、主にDAGによって表される • Workflowのスケジューリング • 多くの考慮すべき条件 • データの場所 (locality) • 前のジョブの終了時間 • 賢い戦略が必要になる
実例1 : 自然言語処理 • 単語の用例別統計の抽出 • パーズ後、キーワードごとの用例を抽出 Corpus Parsed Corpus Phrases (by words) Concurrence analysis Corpus Parsed Corpus Phrases (by words) Concurrence analysis Corpus Parsed Corpus Phrases (by words) Concurrence analysis
実例2 : 量子化学 • FMO (Fragment Molecular Orbital) • 部分に分けて量子シミュレーションを行う • 部分計算後につなぎ合わせる「補正」を行う • 部分構造の結果を使い回せる • 例えばCH3やOHなど (但し扱うデータサイズは小さい)
スケジューリング戦略[1] • スケジュラーの構成 • 集中的 : 一つのスケジュラーが全プロセッサを担当 • 階層的 : クラスタ単位でのスケジューリングを行い、 細かいタスク割り当ては各クラスタで行う • 分散的 : 全体を統括するスケジュラーを持たない • リソースとタスクの割り当て (Planning Scheme) • 静的 : 実行前に決める • 実行時間予測が必要 • 動的 : 実行中に決める • Matchmaking (性能・data localityなどを考慮) • 完全に動的だと、賢い戦略は取りにくい [1] Srikumar Venugopal, et al., "A taxonomy of Data Grids for distributed data sharing, management, and processing” ACM Computing Surveys (CSUR) archive Vol.38, Issue 1 (2006)
既存システム • Workflowに対応したスケジュラー • Condor DAGMan • Pegasus (DAGManの改良) • Triana, JOpera • GrADS • スケジュラーではないけど… • Dmake • DistCC
DAGMan[2] : 動的に配分 • 最も有名なGrid Scheduler • 単一ジョブ : Condor-G • データ転送 : Stork • Workflow : DAGMan • DAGManは依存性を解析し、CondorとStorkに(ばらばらに)ジョブを投入 • Data Intensiveアプリでは、データ転送が • 静的解析により、データ転送時にレプリカを作成し、高速化を図る研究もある (松岡研) [2] http://www.cs.wisc.edu/condor/
Condorのスケジューリング • タスクをキューから一つずつ取り出し • Matchmakingによって実行ノードを決定 • ノードの利用権限 • 使用可能ディスクサイズ • ノードの混み具合 • 計算元データの場所
Pegasus[3] : Jobをグループ化 • ジョブをグループ化 (クラスタリング) • 必要とするファイルによって分類 • クラスタ(site)ごとにジョブを割り当て • 密に結合したジョブは近いマシンに • 実行時間予測はしない • 静的分析 [3] Luiz Meyeret al., "Planning Spatial Workflows to Optimize Grid Performance”SAC’06, April, 23-27, 2006, Dijon, France.
4手法を比較 ランダム クラスタリング キャッシュ データのある場所でジョブを実行 資源を10%に制限 タスクが多くなると改善が少ない Pegasusでの性能改善 Prescript : 同時にsubmitされるjob
GrADS[4] : 実行時間を予測 • 実行時間を予測 • 実行モデル + 小さなデータでの挙動 • CPU・メモリ・ネットワーク資源の情報 • 浮動小数点演算の割合 など • 各タスクを実行するのにかかる時間を予測 • スケジューリング • 三つのヒューリスティクスから最良を選ぶ • 静的に行う [4] Anirban Mandal et.al, "Scheduling Strategies for Mapping Application Workflows onto the Grid“, HPDC’05
実行時間の予測 • 静的に全マシンについて計算する 実行時間 = CPU時間 + データ転送時間 Rank(ci, rj) = w1 * eCost(ci, rj) + w2 * dCost(ci, rj) eCost = (演算 + キャッシャミス) / クロック dCost = sum(データサイズ * レイテンシ /バンド幅)
スケジューリング戦略 • 三つの戦略で別々に計算 • Min-min :各タスクの最短コスト中、最もコストが小さいものを採用 • Max-min : 各タスクの最短コスト中、最もコストが大きいものを採用 • Sufferage : 各タスクについて、最短コストと二番目に短いコストの差が最も大きいものを採用 • 最短の総実行時間のものを採用
スケジューリング例 Min-min Min-max Sufferage 2-1=1 Sufferage 5-2=3 Sufferage 11-10=1 Sufferage 5-4=1 Sufferage
実行結果 • 4手法を比較 • HA : 本手法 (正確な予測 + 賢いマッピング) • HC : ラフな予測 + 賢いマッピング • RN : ランダムスケジューリング • RA : 予測に基づいた重みを付けてランダム Mapped tasks Used nodes Makespan Exec. time
DistCC / DMake • 一ファイルずつスケジュールするっぽい all : main echo "done" main : main.o a.o b.o c.o d.o gcc -o main main.o a.o b.o c.o d.o a.o : a.c gcc -c a.c b.o : b.c gcc -c b.c … rr56428@sx103> dmake dmake: defaulting to parallel mode. sx103.ecc.u-tokyo.ac.jp --> 1 job cc -c main.c sx103.ecc.u-tokyo.ac.jp --> 2 jobs gcc -c a.c sx103.ecc.u-tokyo.ac.jp --> 2 jobs gcc -c b.c sx103.ecc.u-tokyo.ac.jp --> 2 jobs gcc -c c.c sx103.ecc.u-tokyo.ac.jp --> 2 jobs gcc -c d.c sx103.ecc.u-tokyo.ac.jp --> 1 job gcc -o main main.o a.o b.o c.o d.o sx103.ecc.u-tokyo.ac.jp --> 1 job echo "done" sx103.ecc.u-tokyo.ac.jp --> Job output echo "done" done newcamel ermine logosgw
まとめ? • 実行時間の解析がポイント • 動的に再計画するといい? • 対象を絞らないと有り難みが無い • 依存性が少ない • Data Intensiveでない • Dmakeの記述性は良いかも