Download

1 / 66
940 likes | 2.66k Views
t 검정 (t-test) 분산분석 (ANOVA). t 검정 (t-test). 하나 또는 두 집단의 평균비교. 연속변수 : 구간척도 또는 비척도로 측정된 값 t 검정과 Wilcoxon 검정 측정값들이 정규분포를 하는지 여부에 따라 구분 t 분포 William Gosset(1876-1937), Student 라는 필명 ( 익명 ) 으로 논문을 발표 Student t 분포. t 분포는 0 을 중심으로 좌우대칭 표준정규분포 ( N (0, 1)) 보다 두터운 꼬리

E N D
t 검정(t-test) 하나 또는 두 집단의 평균비교
연속변수 : 구간척도 또는 비척도로 측정된 값 t검정과 Wilcoxon 검정 측정값들이 정규분포를 하는지 여부에 따라 구분 t분포 William Gosset(1876-1937), Student라는 필명(익명)으로 논문을 발표 Student t분포
t분포는 0을 중심으로 좌우대칭 • 표준정규분포(N(0, 1))보다 두터운 꼬리 • 분포의 모양은 자유도(d.f., degree of freedom)에 따라 달라지므로, 자유도가 t분포의 모수(parameter) • 표준정규분포와 자유도 5인 t분포 자유도가 커질수록 꼬리가 얇아지고 중심부분이 높아져, 자유도가 무한대(∞)가 되면, 표준정규분포와 동일한 모양
t검정 하나 또는 두 개 집단의 평균을 비교하는 모수적 검정법(parametric test) 평균을 비교: 측정값들이 정규분포를 하여, 평균이 그 집단의 대표값으로서의 역할을 하고 있다는 것을 의미 이상점(outlier)이 있는 비정규분포 자료는 t검정의 대상이 아니다.
한 집단의 평균비교 한 집단의 평균과 다른 기준값을 비교 다른 기준값 - 다른 연구결과에서 나온 값 또는 지금까지 알려져 온 값 귀무가설(모집단의 평균이 μ0이다)이 옳을 때, 자유도 n-1인 t 분포
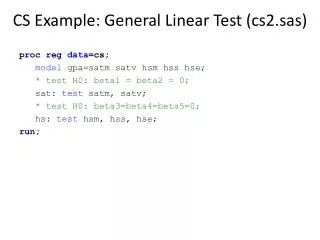
예) 어떤 질환이 혈장 potassium농도(정상인의 평균치=4.5mEg/l)에 미치는 영향을 알아보기 위해, 10명의 환자로부터 얻은 값이 다음과 같을 때 질환군의 혈장 potassium농도가 정상인과 다르다고 할 수 있는가? 3.40 2.98 3.83 3.94 4.10 3.65 3.43 3.72 3.52 2.60 SAS 프로그램 DATA onet; INPUT potas @@; diff= potas-4.5; CARDS; 3.40 2.98 3.83 3.94 4.10 3.65 3.43 3.72 3.52 2.60 ; PROC TTEST; VAR diff; RUN;
결과 환자군의 평균이 3.517(=4.5-0.983), 표준편차가 0.45, P<0.0001로 정상인에 비해 유의한 차이가 있다
두 집단의 평균비교 Two-sample t-test vs. Paired t-test
질문 : 왜 평균을 비교할까? 대표값 질문 : 평균은 항상 자료들을 대표하는 값일까? 정규분포일 때에만 예. 정규분포가 아닌 경우 70, 74, 94, 112, 500. 평균 850/5=170. 평균은 이상점의 영향을 받기 때문에 적절한 대표값이 될 수 없다. 중앙값
정규분포를 하는 자료 모수적 검정 정규분포를 하지 않는 자료 비모수적 검정 모수적 검정 비모수적 검정 Two-sample t-test Wilcoxon rank sum test (Mann-Whitney U test) Paired t-test Wilcoxon signed rank test
비모수적 검정(Wilcoxon rank sum test), 변수변환 Smith-Satterthwaite test, 비모수적 검정, 변수변환 Two-sample t-test 독립인 두 집단의 평균 비교 가정 : 정규분포, 두 집단의 분산 동일
예) 부갑상선 기능항진증 환자 5명, 정상인 12명의 혈청 중 칼슘량. 환자 12.8, 13.2, 11.7, 14.0, 12.8 건강인 10.7, 10.1, 9.8, 9.5, 10.3, 9.7, 9.8, 9.6, 10.3, 9.3, 9.5, 10.2 SAS 프로그램 DATA twot; INPUT gr$ ca @@; CARDS; P 12.8 P 13.2 P 11.7 P 14.0 P 12.8 N 10.7 N 10.1 N 9.8 N 9.5 N 10.3 N 9.7 N 9.8 N 9.6 N 10.3 N 9.3 N 9.5 N 10.2 ; PROC TTEST; CLASS gr; VAR ca; RUN;
Paired t-test 짝지워진 값들간의 차이를 구한 후, 차이값들의 평균이 0인지 검정 검정방법 : 한 집단의 평균 비교와 동일 예 1) 10쌍의 쌍둥이를 대상으로 A 약과 B 약의 효과를 비교 첫 번째 쌍 (A, B) 두 번째 쌍 (A, B) ⋮
예 2) 동일한 사람을 대상으로 특정 약의 효과 발견 약 투여 전 ↓ 후 ---------------------- ● ● ● ● ⋮ ⋮ 예 3) 동일한 사람의 신체 두 부위 비교 좌 우 ---------------------- ● ● ● ● ⋮ ⋮
예) 신경증 환자에서 정신안정제의 효과. Placebo와 정신안정제를 각 환자에게 1주일씩 투여. 불안점수 측정. 환자 1 2 3 4 5 6 7 8 9 10 ----------------------------------------------------------------- 안정제 19 11 14 17 23 11 15 19 11 8 가짜약 22 18 17 19 22 12 14 11 19 7 SAS 프로그램 DATA pairt; INPUT drug placebo @@; diff=drug-placebo; CARDS; 19 22 11 18 14 17 17 19 23 22 11 12 15 14 19 11 11 19 8 7 ; PROC MEANS; VAR drug placebo; RUN; PROC TTEST; VAR diff; RUN;
Paired t-test (관련된 집단)와 Two-sample t-test (독립인 집단)의 선택 실험방법의 선택 관련된 자료 - 제약 추가적인 정보 결측치(missing value) 연구자가 관심을 가진 요인 이외의, 결과를 왜곡시킬 수 있는 다른 요인들을 사전에 제어(control) 보다 정밀한 비교가 가능 대부분의 경우 독립집단보다 관련된 집단의 비교가 검정력이 더 높다.
문제점 : 정규성 검정에서의 검정력, “어지간히 정규분포에 가까운 자료라 하더라도 자료 수가 많기만 하다면 정규분포가 아니라는 검정결과를 얻는다” 중심극한정리, “원 자료의 분포가 정규분포가 아닐지라도 자료 수만 많아지면 표본평균은 정규분포를 한다” 표본 수가 30이상(대표본) 모수적 검정과 비모수적 검정의 선택 측정값이 정규분포를 하느냐에 따라 정규분포의 파악방법 : 그림, 정규성 검정
정규성 검정을 하는 이유 - 검정방법(모수 또는 비모수 방법)의 선택. 자료 자체의 분포가 아닌 검정에 사용된 통계량의 분포에 의해 결정되어야. 모수적 검정과 비모수적 검정을 선택할 때 정규성 검정의 이용 가. 비교하고자하는 각 집단의 자료수가 충분히 크다면(30개 이상) 정규성 검정의 결과에 관계없이 모수적 방법을 선택해도 별 문제가 없다. 나. 만약 자료수가 작은데도 불구하고 정규성 검정이 기각된다면 비모수적 방법을 선택한다.
문제 : 독립인 두 집단자료에 대한 정규성 검정은 두 집단 전체자료로 해야 할까, 아니면 각 집단별로 해야 할까? 잘못된 분석방법 1. t검정과 Wilcoxon 검정을 모두 실시한 후 P값이 더 작게 나온 방법을 선택 : 만약 해당 검정법이 요구하는 가정이 만족되지 않는다면, 잘못된 P값을 사용한 셈 2. 비모수 검정은 표본의 수가 작을 때 사용 - 자료의 수가 작으면 모집단이 어떤 분포를 하는지 알 수 없다? t분포는 소표본(small sample)에 대한 이론. - 해당 측정값들의 (모집단)분포 - 기존의 연구. - 정규분포에 비모수 검정, 검정력 ↓
Kruskal-Wallis test Friedman test 분산분석(ANOVA) 세 평균 이상 비교 One-way ANOVA vs. Repeated measures ANOVA Two-sample t-test vs. Paired t-test Randomized block design Generalization
사후검정 세 집단의 평균을 비교 - 분산분석 결과 P>0.05라면 “처리간의 차이가 없다”고 결론, 분석 끝. P<0.05일 때에는? → “세 집단의 평균이 모두 다 같지는 않다” “세 집단 중 다른 집단이 적어도 하나는 있다” → “구체적으로 어떤 집단들간에 차이가 있는 지”? 세 집단 중 서로 다른 집단들을 찾는 방법 : 두 집단씩 세 번의 t검정? 분산분석과정을 거칠 필요없이, 처음부터 t검정
세 번의 검정을 하지 않고 분산분석을 하는 이유 “한 가지 실험에서 얻은 자료들은 한 가지 가설을 위해 존재한다” “한 집단의 자료들은 한 번의 검정에만 사용되어야 한다” 동일한 자료가 여러 번의 검정에 반복적으로 사용되면 그 검정들은 서로 독립이 되지 않는다. 검정들이 서로 독립이 아닐 때의 문제점 유의수준이 처음 정했던 값(α)보다 커진다
상호독립이 아닌 k 번의 t검정이 반복 → 각 검정의 실제 유의수준은 α´ = 1-(1- α )k 예. 유의수준 0.05로 세 번의 t검정이 반복 → 실제 유의수준이 약 0.14(=1-(1-0.05)3) → 가설을 잘못 기각하게 될 가능성이 훨씬 높아진다 → 세 번의 t검정에서의 얻은 P 값을, 약 3배(≒0.14/0.05)해준 값이 정확한 P 값 실제 유의수준 α´ 를 사용하여 구체적인 각 집단간의 차이를 검정하는 방법: 다중비교 (multiple comparison)
사후검정의 종류 • Duncan • Tukey • Scheffe • Dunnett • Bonferroni ... 각 검정방법의 차이는?
분산분석 “반응값들이 서로 다른 정도”를 나타내는 “분산”을, 그 원인에 따라 “나누는”, 즉 “분석하는” 통계적 방법 실제로는 “분산”이 아닌 “제곱합”을 분할 제곱합 분산공식의 분자에 있는 값
A집단 B집단 1, 2, 3, 4, 5 6, 7, 8, 9, 10 평균 = 8 평균 = 3 두 치료법, A 와 B 를 각 5명의 대상에게 적용하여 얻은 반응값
Variation Total Within GR Between GR
5.5 평균 Variation 제곱합(Sum of squares)으로 표현 제곱합 평균과의 차이를 제곱한 값들의 합 Total SS
B A 8 3 5.5 3 8 Within GR SS 20 Between GR SS
제곱합의 분할 Total SS = Between GR SS + Within GR SS (82.5) = (62.5) + (20) 총변이 = 집단간 차이에 의한 변이 + 오차변이 Between GR SS >>> Within GR SS 집단간의 차이가 있다(결론)
예) 24명의 환자를 대상으로 네 가지 종류의 물리치료기구의 성능을 비교한 자료
프로그램(SAS-PROC ANOVA, GLM) DATA crd; INPUT type $ n; DO i=1 TO n; INPUT effect @@; OUTPUT; END; CARDS; A1 6 64 88 72 80 79 71 A2 6 76 70 90 80 75 82 A3 6 58 74 66 60 82 75 A4 6 95 90 80 87 88 85 ; DATA crd1; SET crd; DROP n i; RUN; PROC MEANS; CLASS type; RUN; PROC ANOVA; CLASS type; MODEL effect=type; MEANS type/TUKEY; RUN;
각 블록에 속한 동물들에게 세가지 호르몬제 수준 중 하나를 랜덤하게 투여한 후, 체중증가율을 측정 예. 성장호르몬제의 효과를 알아보기 위해 15마리 동물을 대상으로 체중(30-48g)에 따라 3마리씩 5개 블록을 구성
프로그램(SAS-PROC ANOVA, GLM) DATA rbd; DO block='B1','B2','B3','B4','B5'; DO hormon='A1','A2','A3'; INPUT effect @@; OUTPUT; END; END; CARDS; 9.48 9.24 8.66 9.52 9.95 8.50 9.32 9.20 8.76 9.98 9.68 9.11 10.00 9.94 9.75 ; PROC MEANS; CLASS hormon; VAR effect; RUN; PROC MEANS; CLASS block; VAR effect; RUN; PROC ANOVA; CLASS hormon block; MODEL effect=hormon block; MEANS hormon/TUKEY; RUN;
? ?