
Uploaded by
tyme
1 SLIDES
107 VIEWS
10LIKES
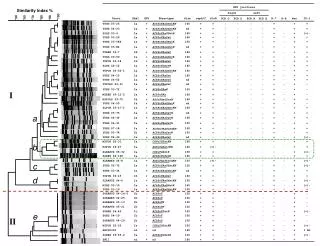
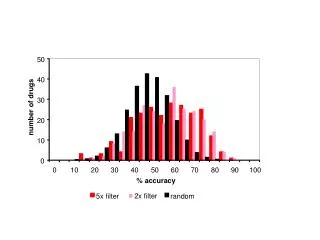
Efficient Similarity Indexing for Multilingual Texts
DESCRIPTION
This research explores novel techniques for efficient similarity indexing in multilingual texts, facilitating improved information retrieval and language processing. The study delves into various similarity metrics and indexing approaches relevant across languages, addressing challenges in cross-lingual data analysis. Insights from this work can enhance the performance of multilingual information systems by enabling quick and accurate retrieval of linguistically diverse content. Additionally, the findings contribute to advancing cross-language processing methodologies and boosting the overall effectiveness of multilingual text analysis tools.
Download
1 / 1
Download Presentation 
Efficient Similarity Indexing for Multilingual Texts
An Image/Link below is provided (as is) to download presentation
Download Policy: Content on the Website is provided to you AS IS for your information and personal use and may not be sold / licensed / shared on other websites without getting consent from its author.
Content is provided to you AS IS for your information and personal use only.
Download presentation by click this link.
While downloading, if for some reason you are not able to download a presentation, the publisher may have deleted the file from their server.
During download, if you can't get a presentation, the file might be deleted by the publisher.
E N D













More Related
Audio
Live Player