Download
1 / 13
130 likes | 218 Views
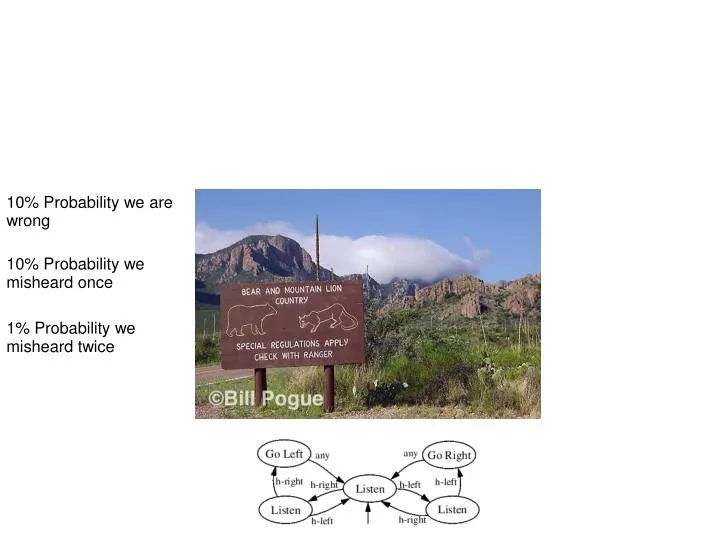
10% Probability we are wrong. 10% Probability we misheard once. 1% Probability we misheard twice. Douglas Aberdeen, National ICT Australia 2003 Anthony R. Cassandra, Leslie Kaelbling, and Michael Littman, NCAI 1995. Partially Observable Markov Decision Process (POMDP). by Sailesh Prabhu

E N D
10% Probability we are wrong 10% Probability we misheard once 1% Probability we misheard twice
Douglas Aberdeen, National ICT Australia 2003 Anthony R. Cassandra, Leslie Kaelbling, and Michael Littman, NCAI 1995 Partially Observable Markov Decision Process (POMDP) by Sailesh Prabhu Department of Computer Science Rice University
Applications • Teaching • Medicine • Industrial Engineering
Overview • Describe a Partially Observable Markov Decision Procedure (POMDP) • Consider the agent • Solve the POMDP like we solved MDPs
Reward Partial Observability Control/Action Describing an MDP using a POMPDP: How
Probability The Agent Internal State θ Observation Control I have a load I don't have a load Parametrized policy: Observation Parameter Control Internal State
Probability The Agent Current State Φ Observation Future State I have a load I don't have a load Parametrized policy: Parametrized I-State Transition: Observation Internal State Internal State
Recap The agent 1) updates internal states and 2) acts.
Solve POMDP • Globally or locally optimize θ and Φ • Maximize long-term average reward: • Alternatively, maximize discounted sum of rewards: • Suitably mixing:
Learning with a Model • The agent knows the model , , • Observation/action history: • Belief state 1/3 1/3 1/3 Goal 1/2 1/2 1
Learning with a Model • Update beliefs: • Long-term value of a belief state • Define:
Finite Horizon POMDP • The value function is piecewise linear and convex • Represent it as
Complexity • Exponential number of state variables: • Exponential number of belief states: • PSPACE-Hard • NP-Hard




















