Download

1 / 84
870 likes | 1.13k Views
第八章 分類與預測 8.1 決策樹分類演算法 8.2 類神經網路 8.3 迴歸分析 8.4 結語 習題. 資料採掘透過分析資料來源中資料,可以獲取用於 進行預測的預測性知識。預測性採掘就是指預測性 知識的資料採掘,主要包括資料分類、數值預測 等。 分類是預測資料物件的所屬類別,即物件的分類別標號 分類在資料採掘中是一項非常重要的任務 資料分類首先透過分析由己知類別的資料物件組成的訓練資料集, 建構描述並區分資料物件類別的分類模型. 學習程序 (1) 分析訓練資料集建構分類模型 分類演算法可以根據下列標準進行比較和評估。

E N D
第八章 分類與預測8.1 決策樹分類演算法8.2 類神經網路8.3 迴歸分析8.4 結語習題
資料採掘透過分析資料來源中資料,可以獲取用於資料採掘透過分析資料來源中資料,可以獲取用於 進行預測的預測性知識。預測性採掘就是指預測性 知識的資料採掘,主要包括資料分類、數值預測 等。 • 分類是預測資料物件的所屬類別,即物件的分類別標號 • 分類在資料採掘中是一項非常重要的任務 • 資料分類首先透過分析由己知類別的資料物件組成的訓練資料集,建構描述並區分資料物件類別的分類模型
學習程序 (1) 分析訓練資料集建構分類模型 分類演算法可以根據下列標準進行比較和評估。 • 預測的準確率。涉及模型正確地預測新的或先前未見過的資料的類別標號的能力。 • 速度。涉及產生和使用模型的計算花費。 • 穩健性。涉及給定噪音資料或具有遺漏值的資料,模型正確預測的能力。
可伸縮性。涉及給定大量資料,有效地建構模型的能力。可伸縮性。涉及給定大量資料,有效地建構模型的能力。 • 可解讀性。涉及學習模型提供的了解和洞察力的階層。 (2) 評估模型的預測準確率 評估模型的預測準確率使用測試樣本集。測試樣本 集中每個樣本的類別標號是已知的,但並不提供給 分類模型
分類程序 • 分類程序就是用分類模型(分類規則、決策樹、數學公式等)對未知類別的新資料進行分類。 • 分類和聚類是兩個容易混淆的概念,但事實上它們有顯著區別。 • 資料分類是有指導的,而聚類分析是無指導的。
數值預測程序與分類程序相似。首先透過分析由預數值預測程序與分類程序相似。首先透過分析由預 測屬性取值已知的資料物件組成的訓練資料集,建 構描述資料物件特徵與預測屬性之間的相關關係的 預測模型,然後利用預測模型對預測屬性取值未知 的資料物件進行預測。
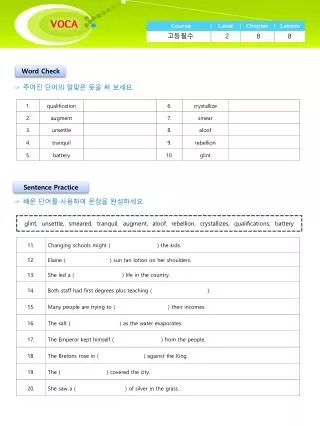
8.1 決策樹分類演算法 決策樹是一種有效的分類方法,對於多峰分佈之類 的問題,這種方法尤為方便。利用決策樹採用分級 的形式,可以把一個複雜得多類別分類問題轉化為 若干個簡單的分類問題來解決。
8.1.1 什麼是決策樹 設計一個決策樹,主要應解決下面幾個問題: • 選擇一個合適的樹結構,即合理安排樹的節點和分支。 • 確定在每個非葉節點上要使用的屬性。 • 在每個非葉節點上選擇合適的決策規則。
8.1.2 決策樹的建構 • 演算法及描述 • 決策樹分類演算法透過分析訓練資料集遞迴地建構決策樹,其基本思想是:首先,在整個訓練資料集S所有描述屬性A1,A2,…,Am上遞迴地建構決策樹。 • 當決策樹分類演算法遞迴地建構決策樹時,某節點對應的訓練資料(子)集由整個訓練資料集中滿足從根節點到該節點路徑上所有屬性測試的訓練樣本組成。
出現如下情況,也需要停止建構決策樹(子樹)的遞迴出現如下情況,也需要停止建構決策樹(子樹)的遞迴 程序。 • 某節點對應的訓練資料(子)集為空集合。此時,該節點作為葉節點並用父節點中佔多數的記錄類別標識。 • 某節點沒有對應的(剩餘)描述屬性。此時,該節點作為葉節點並用該節點中佔多數的記錄類別標示。
決策樹分類演算法描述如下: 演算法:決策樹分類演算Generate_decision_tree(S,A) • 輸入:訓練資料集S,描述屬性集合A • 輸出:決策樹 • 步驟: ① 創建對應S的節點N ② if S中的記錄屬於同一類別c then以。標示N並將N作為葉節點返回 ③ if A為空 then 以S中佔多數的記錄類別。標示N並將N作為葉節點返回
④ 從A中選擇對S而言資訊增益最大的描述屬性Ai作為N的測試屬性 ⑤ for Ai的每個可能取值 //設Ai的可能取值為a1,a2,…,av(5.1) 產生S的一個子集Sj;//Sj為S中Ai=aj的記錄集合(5.2) if Sj為空白,then創建對應Sj的節點Nj,、以S中佔多數的記錄類別c標識Nj,並將Nj作為葉節點形成N的一個分支(5.3) else 由Generate_decision_tree(Sj,A-Ai)創建子樹形成N的一個分支。
資訊增益 離散型隨機變數X的無條件entropy定義為 式中,P(xi)為X=xi的機率;u為X的可能取值個數。
離散型隨機變數X的條件entropy定義為 式中,為X= ,Y= 的聯合機率; 為已知Y= 時,X= 的條件機率;u、v分別為X、Y的可能取值個數。
假設訓練資料集是關係資料表r1,r2,…,rn,其中描述假設訓練資料集是關係資料表r1,r2,…,rn,其中描述 屬性為A1,A2,…,Am、類別標屬性為C.類別標屬性C 的無條件entropy定義為 式中,u為C的可能取值個數,即類別個數,類別記 為c1,c2,…,cu; 為屬於類別ci的記錄集合, 即為屬 於類別ci的記錄總數。
給定描述屬性 ,類別標屬性C的條件entropy 定義為 式中,V為 的可能取值個數,取值記a1,a2,…,av; 為 =aj的記錄集合, 即為 =aj的記錄數目; 為=aj且屬於類別ci的記錄集合, 即為 =aj且屬於 類別ci的記錄數目。
給定描述屬性 ,類別標屬性C的資訊增益 定義為 可以看出, 反映減少C不確定性的程度, 越大, 對減少C不確定性的貢獻越大。
例8.1假設蔬菜資料表如表8.1所示,“顏色”、“形狀”例8.1假設蔬菜資料表如表8.1所示,“顏色”、“形狀” 是描述屬性,“蔬菜”是類別標屬性,分別求給定“顏 色”、“形狀”屬性時,“蔬菜”屬性的資訊增益。
因為G(蔬菜,顏色) > G(蔬菜,形狀),所以選擇“顏 色”屬性作為根據點的測試屬性,得到的決策樹如圖 8.3所示。
由於決策樹是在分析訓練資料集的基礎上建構的,由於決策樹是在分析訓練資料集的基礎上建構的, 決策樹傾向於過分適合訓練資料集。如果訓練資料 集含有噪音,那麼可能決策樹的某些分支反映的是 噪音而不是總體,應該剪去這些不可靠的分支。 有兩種剪枝策略: (1) 先剪枝策略 (2) 後剪枝策略
8.1.3 由決策樹提取分類規則 決策樹建構好後,可以對從根到樹葉的每條路徑創 建一個形如IF-THEN的規則。創建方式為沿著給定 路徑上的每個屬性-值續對(內部節點-分支序對)形成 規則前件(“IF”部分)的一個合取項,葉節點形成規則 後件(“THEN“部分)。
例 8.4 沿著由根節點到樹葉節點的路徑,圖 8.4的決 策樹可以轉換成IF-THEN分類規則: • IF年齡 =“<=30”AND 學生 =“否”THEN購買電腦= “否” • IF年齡 =“<=30”AND 學生 =“是”THEN購買電腦= “是 • IF年齡 =“30…40” THEN購買電腦= “是 • IF年齡 =“>40”AND 學生 =“優”THEN購買電腦= “否” • IF年齡 =“>40”AND 學生 =“中等”THEN購買電腦= “是”
8.1.4 對新物件分類 假如現在增加了一位新顧客,他是一名教師,年齡 為45歲,收入較低但信譽很好。商場需要判斷該顧 客是否會購買電腦?即是將該顧客劃分到“購買電腦 類”呢?還是將他劃分到“不購買電腦”類?很顯然, 利用上面的分類規則,可以判定該顧客不會購買電 腦。
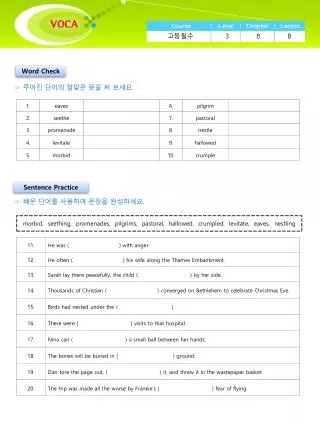
8. 2 類神經網路 • 類神經網路可以模仿人的頭腦,透過問一個訓練資料集學習和應用所學知識來生成分類和預測的模式。 • 類神經網路由許多基本單元(常常稱為類神經元或網路節點)構成。 • 基本單元之間的連接相當於人腦中類神經元的連接。
8.2.1 前饋類神經網路結構 前饋類神經網路是分層網路模型,具有一個輸入 層、一個輸出層,輸入層和輸出層之間有一個或多 個隱藏層。
在輸入層,各節點的輸出可以等於輸入,也可以按在輸入層,各節點的輸出可以等於輸入,也可以按 一定比例調節,便其值落在-1和+1之間。而在其他 層上,每個節點的輸入都是前一一層上各節點輸出 的加權和,輸出是輸入的某種函數。對中間層,節 點j的輸入為 :
節點j的輸出為: Oj = f ( netj ) 採用S型啟動函數,即 所以
同理,輸出層第k個節點的輸入、輸出為: 圖8.6表示了對於隱藏層、輸出層的任意單元力由它 的輸入計算它的輸出的過程。
8.2.2 類神經網路學習 • 確定好網路結構(網路層數,各層節點數目)之後,應該確定各節點的偏值及節點之間的連接權。學習程序就是調整這兩組值,使每個訓練樣本在輸出層的節點上獲得期望輸出。 • 學習使用誤差後向傳播演算法。 • 在輸出層,由於可以從誤差的定義中直接求出誤差對各個類神經元輸出的偏微分,從而求出誤差對所有連接權的偏微分。
對於某訓練樣本,實際輸出與期望輸出的誤差Error對於某訓練樣本,實際輸出與期望輸出的誤差Error 定義為: 其中,C為輸出層的單元數;Tk為輸出層單元A的期 望值輸出;Ok為輸出層單元k的實際輸出。
為使Error最小,採用使Error沿梯度方向下降的方為使Error最小,採用使Error沿梯度方向下降的方 式,即分別取Error關於wjk、的偏微分,並令它們與 wjk、成正比:
其中,l 為避免陷入局部最佳解的學習率,一般在區 間[0,1]上取值。求解上式可以得到加權、單元偏置 的修改量為: 其中,Qj為前一層單元j的預測輸出;Errk是誤差 Error對節點k的輸入netk的負偏微分,即。
類似地,隱藏層單元j與前一層單元i之間的加權Wij類似地,隱藏層單元j與前一層單元i之間的加權Wij 的修改量 、單元j的偏置 的修改量
加權、單元偏置的修改公式為: 加權值、單元偏置的更新有兩種策略: (1) 處理一個訓練樣本更新一次,稱為實例更新,一 般採用這種策略。 (2) 可以累積加權值、單元偏置,處理所有訓練樣本後再一次更新,稱為周期更新。
處理所有訓練樣本一次,稱為一個周期。一般,在處理所有訓練樣本一次,稱為一個周期。一般,在 訓練多層前饋類神經網路時,後向傳播分類演算法 經過若干周期以後可以使Error小於規定閥值,此時 認為網路收斂,結束迭代訓練程序。
定義如下結束條件: • 前一周期所有的加權變化都很小,小於某個設定的值。 • 前一周期預測的準確率很大,大於某個設定的 值。 • 周期數大於某個設定的值。
誤差後向傳播演算法描述如下: • 演算法:後向傳播分類演算法 (S,NT,1) • 輸入:訓練資料集S,多層前饋類神經網路NT,學習率I • 輸出:經過訓練的多層前饋類神經網路NT • 步驟: (1) 在區間[-1,1]上隨機起始化NT中每條有向加權邊的加權值、每個隱藏層與輸出層單元的偏置 (2) while結束條件不滿足 (2.1) for S中每個訓練樣本S (2.1.1) for隱藏層與輸出層中每個單元j //從第一個隱藏層開始向前傳播輸入
(2.1.1.1) (2.1.1.2) (2.1.2) for輸出層中每個單元j (2.1.2.1) Errj = Oj(1-Oj)(Tj-Oj) (2.1.3) for隱藏層中每個單元j //從最後一個隱藏層開 始向後傳播誤差 (2.1.3.1) (2.1.4) for NT中每條有向加權邊的加權值 (2.1.4.1) (2.1.5) for 隱藏層與輸出層中每個單元的偏置 (2.1.5.1)
誤差後向傳播演算法要求輸入端的輸入是連續值,誤差後向傳播演算法要求輸入端的輸入是連續值, 並對訓練樣本的連續屬性值規格化以便提高訓練效 率與品質。如果訓練樣本的描述屬性是離散屬性, 則需要對其編碼。編碼方法有兩種: • P值離散屬性: • 二值離散屬性
例8.6假設訓練樣本S的屬性值與實際類別分別為例8.6假設訓練樣本S的屬性值與實際類別分別為 與1,兩層前饋類神經網路NT如圖8.8所示,NT中每 條有向加權邊的加權值、每個隱藏層與輸出層單元 的偏置如表8.3所示,學習率為0.9。寫出輸入s訓練 NT的程序。
8.2.3 類神經網路分類 例如,例8.6中,由於只有一個輸出節點,表示只有 兩個類別(A類、B類)。網路訓練好後,表8.6中的各 權值和偏值都固定。對於一個未知類別的樣本X= (x1,x2,x3)送入輸入層後可以計算出O6,若O6≒1, 則表示樣本X應屬於A類;若O6≒0,則表示樣本A 應屬於B類;若,O6≒0.5,則拒絕分類。
8.3 迴歸分析 迴歸分析有一元迴歸與多元迴歸之分。依變數y在一 個自變數x上的迴歸稱為一元迴歸;依變數y在多個 自變數門x1,x2,…,xn上的迴歸稱為多元迴歸。