Download
1 / 5
50 likes | 189 Views
This text explores key concepts in statistical model selection, emphasizing the trade-off between goodness of fit and model bias. It introduces the Akaike Information Criterion (AIC) as a method to evaluate models by considering the number of parameters and their performance. The importance of assessing model parameters, the impact of sample size on fitting, and how outliers can influence model selection are also discussed. The text highlights the difference between AIC and traditional hypothesis testing, advocating for careful consideration in choosing the best model descriptor.

E N D
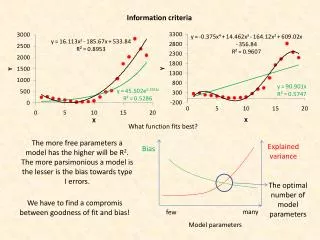
Informationcriteria Whatfunctionfitsbest? Themorefreeparameters a model hasthehigher will be R2. Themoreparsimonious a model isthelesseristhebiastowardstype I errors. Explainedvariance Bias Theoptimalnumber of model parameters We have to find a compromisbetweengoodness of fit and bias! many few Model parameters
The Akaike criterion of model choice k: number of model parameters +1 L: maximum likelihood estimate of the model The preferred model is the one with the lowest AIC. If the parameter errors are normal and independent we get n: number data points RSS: residual sums of squares If we fit using R2: If we fit using c2: At small sample size we should use the following correction
We getthesurprisingresultthattheseeminglyworstfitting model appears to be thepreferred one. A single outliermakesthedifference. The single high residualmakestheexponentialfittingworse
Significantdifferencein model fit ApproximatelyDAIC isstatisticalysignificantinfavor of the model withthesmaller AIC atthe 5% errorbenchmarkif |DAIC| > 2. The last model is not significantly (5% level) different from the second model. AIC model selectionserves to find the bestdescriptor of observedstructure. It is a hypothesisgeneratingmethod. It does not test for significance Model selectionusingsignificancelevelsis a hypothesistestingmethod. Significancelevels and AIC must not be usedtogether.