Download
1 / 4
660 likes | 2.28k Views
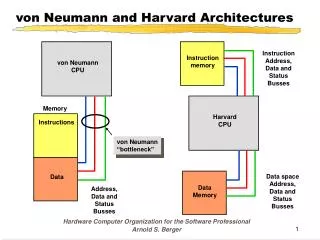
von Neumann and Harvard Architectures. Instruction Address, Data and Status Busses. Instruction memory. von Neumann CPU. Memory. Harvard CPU. Instructions. von Neumann “bottleneck”. Data space Address, Data and Status Busses. Data. Data Memory. Address, Data and Status

E N D
von Neumann and Harvard Architectures Instruction Address, Data and Status Busses Instruction memory von Neumann CPU Memory Harvard CPU Instructions von Neumann “bottleneck” Data space Address, Data and Status Busses Data Data Memory Address, Data and Status Busses Hardware Computer Organization for the Software Professional Arnold S. Berger
Executing a single memory-resident instruction • The 68000 requires time to execute a MOVE xxx.L,yyy.L instruction TIME Time required to generate the instruction address Time required to fetch the instruction from memory Time required to decode the Op Code Time required to generate the operand address Time required to fetch the operand from memory Time required to execute the instruction Time required to put away the result DECODE ADDRESS WAIT EXECUTE ADDRESS WAIT WAIT INSTRUCTION EXECUTION TIME Hardware Computer Organization for the Software Professional Arnold S. Berger
Task Decomposition Stage #3 Stage #1 Stage #2 Stage #3 Stage #1 Stage #2 Stage #3 Stage #1 Stage #2 Total pipeline processing time = TP + 2xTg • A pipelined execution of the same sequence of three processes: • We can create a pipeline because the hardware in Stage #1 becomes idle after executing its task • Start another task in Stage #1 before the entire process is completed • The time for the first result to exit the pipe is called the flowthrough time • The time for the pipe to produce subsequent results is called the clock cycle time Hardware Computer Organization for the Software Professional Arnold S. Berger
Another view of dynamic scheduling Stage 1 Stage 2 Stage 3 Stage 4 Stage N Pipeline 1 Stage 1 Stage 2 Stage 3 Stage 4 Stage N Pipeline 2 Stage 1 Stage 2 Stage 3 Stage 4 Stage N Pipeline 3 Pipeline control, dispatch unit, branch unit, completion unit Integer arithmetic and logical resources Floating point arithmetic resources Floating point register resources Integer register resources Load/Store Unit Bus interface unit Hardware Computer Organization for the Software Professional Arnold S. Berger














