Artificial Neural Networks
670 likes | 854 Views
國立中興大學行銷研究所. Artificial Neural Networks. 人工類神經網路. 類神經網路概述. 前言. 主宰人類思考及行為的大腦,是人類經過數百萬年進化的結晶,最初人類並不相信它是思維和情緒的中心,但在十七世紀以後,經過一些醫生及解剖學家的研究及努力,於是對於腦的結構、腦的基本元素 ‥ 神經元的功能及神經元,組成網路時的連接機能,有了較深入的瞭解,也因此產生了 《 突觸理論 》 ( synaptoldgy ) 的學說,為現代的類神經科學奠訂了基礎。

Artificial Neural Networks
E N D
Presentation Transcript
國立中興大學行銷研究所 Artificial Neural Networks 人工類神經網路
前言 • 主宰人類思考及行為的大腦,是人類經過數百萬年進化的結晶,最初人類並不相信它是思維和情緒的中心,但在十七世紀以後,經過一些醫生及解剖學家的研究及努力,於是對於腦的結構、腦的基本元素‥神經元的功能及神經元,組成網路時的連接機能,有了較深入的瞭解,也因此產生了 《突觸理論》(synaptoldgy)的學說,為現代的類神經科學奠訂了基礎。 • 人類的腦神經系統都是由神經網絡所構成的,由於有神經網絡的存在,使得人類具有學習的能力,但是此種學習能力,在現代科學結晶的電腦中,卻不存在。因此科學家及工程師們,為了使電腦具有學習的能力,便模擬人類的神經模型,建立一個類似於人類的人工神經網絡,希望能藉著此一網絡,使電腦能具有學習的能力。
類神經網路概述 • 類神經網路的架構來自對人類神經系統的認識,它是由許多非線性的運算單元(神經元neuron),和運算單元間的眾多連結(links)所組成。
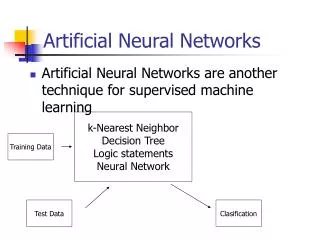
類神經網路概述—三項功能 • 學習 類神經網路可以隨著外在環境的變化來改變它的行為模式,為了使類神經網路能夠在動態環境中發揮功效,適當的學習模式是類神經網路系統的基本條件。 • 回想 當類神經網路受到一個輸入刺激,進而依據網路架構產生一個輸出值時,即稱為「回想」。 • 歸納推演 歸納推演是從一個系統中的局部觀察,而描述出其整體的特性;類神經網路擁有對輸入的資料萃取特徵的能力。
類神經網路概述 • 類神經網路如同看不清內部運作的黑盒子,不能告訴我們正確決策之所以正確的原因,或解決方案為什麼有效,只能讓人知道「事實就是如此」。 • 適用問題:最佳化、辨識/分類、預測、評估/決策 • 應用產業:財務預測、醫學診斷、辨識支票數字
歷史溯源 • 1940年代,開始有人研究類神經元如何運作。 • 1943年,Warren McCulloch (a neurophysiologist at Yale University)與Walter Pits (a logician)提出最早的數學模式(MP模型,即「形式神經元」),解釋生物神經元如何運作,並發表了經典文章 A Logical Calculus Immanent in Nervous Activity. 此文刺激了人工智慧的發展。 • 1949年Hebb提出改變神經元連接強度的Hebb規則 • 1957年Rosenblatt引進了感知器 (Perceptron)的概念,不過仍無法解決一般性問題。 • 1962年Widrow均自適應線性元件
歷史溯源(續) • 1969年,人工智慧大師Minsky在其Perceptron書中,提出當時的神經網路理論,無法解決邏輯上的X0R無法分類的問題。由於Minsky在學術上的地位相當高,並且又由於當時VonNeumann電腦的盛行,使得人工智慧得到迅速的發展,並有顯著的成就,整個學術界因此沉醉於數位電腦的成功之中,而忽略了發展新的人工智慧技術及模擬電腦的迫切性。從此,神經網路的研究,便墜入了黑暗期。
歷史溯源(續) • 雖然在這這樣的打擊下,還是有許多的學者,在此艱難的情況下,仍然致力於神經網絡的研究。例如:提出自適應共振理論的Grossberg,提出自組織映射理論的芬蘭學者Kogonen,提出神經認知機理論的Fukushima,致力於和神經網路有關的數學理論研究的Fukushima,提出BSB模型的Anderson及提出BP(BackPropa-gation)理論的Webos…等,他們都為往後神經網路理論的研究,奠訂了相當的基礎。
歷史溯源(續) • 1982年,John Hopfield發明倒傳遞—一種避開先前缺陷的訓練網路方法,使得研究再度熱絡,研究範圍延展到商業界,協助解決營運上的問題。 • 其後又有Rumellhart及McClelland等人所提出的平行分散式處理(PDP)理論、Kosko提出的雙向聯想記憶網路、Hecht-Nielsen的反向傳播網路、Holland的分類系統...等等,漸漸使得類神經網路理論的研究蓬勃起來。
歷史溯源(續) • 類神經網路在1980年代廣為發展的原因: • 電腦已經普及。 • 類神經網路與已知的統計方法密切相關,所以分析家更樂於使用。 • 大部分公司作業系統開始自動化,資料取得容易。 • 類神經網路開始可以使用在實務上,也是資料採礦經常運用的工具。
歷史溯源(續) • 近年來,美國、歐洲及日本等先進國家的科學家及企業家對神經網路的研究,展現了相當大的熱情,許多和類神經網路有關的學術會議,也相繼展開,如1986年四月美國物理學家在SnowBird召開的國際神經網路會議、1987年在SanDiego召開神經網路國際會議、...等,其後國際神經網路學會也隨之誕生,許多和神經網路有關的期刊也相繼出版,如:1988年創刊的"神經網路"雜誌,1990年3月問世的IEEE神經網路會刊...等,由於在這種熱絡的大環境下,神經網路的研究,漸漸的被推上高峰。
類神經網路模型 不動產估價 • 類神經網路接受特定的輸入(房屋資訊),並產生特定的結果(房屋估價),我們不需瞭解複雜的計算過程,只要使用所得出的估價。 暖氣類型 車庫大小 估價值 屋齡 起居室空間
不動產估價—預測步驟 • 收集所有會影響銷售價格的房屋特徵變項。 • 使用以往實際銷售資料來訓練類神經網路(將所有變數數值轉換成介於-1~1之間的新數值) • 將資料隨機分為訓練集和驗證集 • 類神經網路會藉由比較預測值與實際值去調整內部的權重值,以改進預測結果的準確性。 • 當權重值不再改變或達到預設訓練次數時,就是訓練完成的時候。 • 此時,再以一組未試過的新例子(測試資料集)測試,若感到滿意,預測模型即完成。
範例收集 • 好的範例的要件: • 範例數目充足 • 範例分佈均勻 • 範例數據正確 • 範例來源:記錄、實驗、模擬、問卷 • 範例之分類:訓練、測試、驗證範例
不動產估價—變數描述 用來描述一棟房子的共通變數:
範例收集 • 訓練範例之數目: • 簡單問題:=5*輸入神經數目*輸出數目,(50範例之數目250) • 一般問題:=10*輸入神經數目*輸出數目,(100範例之數目500) • 困難問題:=20*輸入神經數目*輸出數目,(200範例之數目1000) • 測試範例之數目: • 大到足以確保測試*結果的可信賴度
不動產估價—數值轉換 • 連續變數: • 整數 轉換值=2(原始值-中位數)/(最大值-最小值+1) ex: 管線個數為9個,值域範圍為5~17, 轉換後的新數值為 2(9-11)/(17-5+1)= -0.3077 • 實數 轉換值=2(原始值-中位數)/(最大值-最小值) ex: 起居室面積為1614平方呎,值域範圍為714~4185平方呎, 轉換後的新數值為 2(1614-2449.5)/(4185-714)= -0.4813 • 類別變數: 在-1~1之間選擇一個小數來表示每一個項目,如果有三個項目,可分別指定為-1、0、1
不動產估價—訓練組範例 ……
不動產估價—Results 1.0000 暖 氣 類神經網路模型 0.3333 車庫 0.75 估價值 0.0000 管線設施 生活空間 0.2593 …… 0.75 (輸出) × $147,000 (值域 ) + $103,000 (值域底數) = 房價估價 $213,250
類神經網路結構型態 1.簡單的類神經網路,只取 四個輸入單元,產生一個 輸出單元。 2.結果相同於統計上的邏輯 回歸(logistic regression) 增加隱藏層的數目可使網路更有能力捕捉更多的關係型態。若隱藏層的神經援過多,會有造成過度學習的風險,通常一個隱藏層是必要的。
類神經網路結構型態 類神經網路可以產生一個或多個輸出單元 網路中有一個中繼層叫「隱藏層」(hidden layer),可使網路在辨認型態時更有能力
組合函數=ΣWT×X 類神經網路單元 Activation function • 每項輸入變數有自己的加權值 • 組合函數(combination function)將所有輸入變數的值加權加總成一個值 • 轉換函數(transfer function)依組合函數的結果計算輸出值,輸出值通常介於0~1之間。 輸入變數X1 W1 Σ 輸入變數X2 W2 輸出 W3 輸入變數X3 活化函數=組合函數+轉換函數
轉換函數 輸出 • 線性函數最少用,一個只包含線性轉換的前饋式類神經網路就是在做線性回歸。 • S型函數(sigmoid)與雙曲線正切函數(hyperbolic tangent)的最大差異在於輸出值的範圍不同,前者介於0~1,後者則在-1~1之間。 1.0 線型函數 0.5 0.0 S型函數 -0.5 雙曲線正切函數 -1.0
Logistic(x) = 1/(1+e-x) • tanh(x)=(ex-e-x)/(ex+e-x)
類神經網路的分類 依學習演算法分類可分為: • 監督式類神經網路 監督式學習法從不斷修正網路中的傳遞權重,以減少誤差,直到差距小於臨界值。 ANN 輸入 輸出 誤差 真實值
類神經網路的分類 • 非監督式類神經網路 訓練過程中只需提供輸入資料,不需提供輸出資料,網路依照資料的特性自己去學習及調整權重。 ANN 輸入 輸出 聚類結果
類神經網路的分類 依連結架構分類: • 可分為前饋式、回饋式 類神經網路 前饋式類神經網路 回饋式類神經網路至少含有一個 回饋迴圈;回饋式架構常用於處理動態現象或動態的時間序列,擁有更強的學習能力。
隱藏層數量代表網路理解型態的能力,而隱藏層數量的判斷:隱藏層數量代表網路理解型態的能力,而隱藏層數量的判斷: 1) 是否會過度訓練 2) 訓練範例的數量 常數輸入項(偏權值)bias:值為1的常數輸入,也有權重,並且包含在組合函數之內。 組合函數=ΣWT×X+wbj 前饋式類神經網路 [輸入層] [隱藏層] [輸出層] 1.0000 -0.24754 -0.23057 0.48854 0.47909 0.3333 -0.26228 -0.53499 0.57265 0.42183 0.0000 -0.04826 $176,228 0.49815 -0.35789 0.33530 -0.24434 0.58282 -0.33192 0.2593 -0.22200 單位元輸出項 輸入權值 常數輸入項
倒傳導類神經網路 • 倒傳導步驟: • 網路取得訓練例子,用現有權重計算輸出的結果 • 倒傳導計算出輸出值與實際值的誤差 • 誤差經由迴授回到網路,調整權重以取得最小的誤差 誤差修正負向傳播 訊息正向傳播
倒傳導類神經網路 • Delta法則: 先測量輸入對輸出的單元藉由調整每一個權重去減少誤差,經過足夠的訓練後,權重不再劇烈變動,誤差也不再減少,即訓練完成。 • Delta法則的參數 • 動量:權重改變目前變化方向的傾向 • 學習速度:控制權重變化的快慢 • 局部最佳解:存在與網路中全然不同的局部權重組合,產生了更好了結果。
1)變數愈多,所需時間愈多, 手動去除不具預測能力的項 目可以大幅提昇網路效能。 2)挑選預測影響力大的項目,並 只使用這些變數訓練網路,可 以使用決策數來完成。 1)基本上,每個輸出的訓練資料 數量最好相同。 2)訓練資料需要包含所有可能的 輸出值,確保網路能夠對稀有 罕見的事件做出正確得判斷。 Ex: 引擎故障率 變數愈多,網路需要的訓練資料愈多,每個權重至少需要30個例子,最好要100個 選擇訓練資料 • 選擇訓練資料的考量點: • 涵蓋所有特性的值 • 變數的數量 • 訓練範例的數量 • 輸出的數量
準備資料—準備輸入資料通常是類神經網路最為複雜的部份準備資料—準備輸入資料通常是類神經網路最為複雜的部份 其原因為: • 1.選擇正確的資料及例子,讓網路訓練十分困 難,通常要訓練許多次才能得到較佳的結果 • 2.調整(Mapping)資料使每一個項目都介於到-1及+1之間,讓網路更容易瞭解,此過程充滿複雜的程序,若遇到歪斜不良的資料就更難處理了
連續值的變項 • 錢的數量(銷售價,週銷售額) • 平均值(平均銷售量) • 比率(負債收入比,價格收入比) • 物理特性測量值(居住空間坪數,溫度)
當連續值落在最大值及最小值所定義範圍的之內,我們可以將其調整到-1及+1之間,其調整方式如下:當連續值落在最大值及最小值所定義範圍的之內,我們可以將其調整到-1及+1之間,其調整方式如下: 連續值的調整 原始值 – 最小值 ________________________ 調整值 = 2 - 1 * 最大值 –最小值+1
若值大於或小於範圍 • 使用更大的範圍 • 拒絕、捨去超出範圍的值 • 低於最小值以最小值代替 高於最大值以最大值代替 • 將最小值轉到-0.9,最大值轉到+0.9,而非轉到-1與+1 • 沒關係大多數的值都接近於0,少數的超出值不會有顯著的影響
偏態資料的影響 • 收入曲線若向低端偏移,會使得類神經網路很難在收入分析上具有優勢 • 偏移的曲線會讓類神經網路無法在重要區域有效,因為值(value)太過集中,使的計算無法施行 • 資料偏移對於決策樹沒太大影響,因為其是依排序(rank)來計算
調整偏態資料的解決方法 1.離散法(Discreting):將偏移的收入資料分成數個範圍,本案例我們將資料以五等份來區分 • 此方法在此案例中較無效用,因為資料還是集中在第一、二個區域,沒有將偏移的資料分散 • 我們在轉換過程中失去了原始資料的型態
偏態資料的解決方法 2.取對數函數(logarithm):取以10為底的log來將其調整 3.將資料標準化(standardize):將資料以平均數(mean)及標準差(standard deviation)將資料標準化
有順序、離散的變項 • 次數(小孩數目、購買數量) • 年齡 • 次序性的項目(低、中、高)
有順序值的調整 • 年齡的的範圍通常在0到100之間,但實際調整的範圍則看我們所使用的資料而定 • 我們以小孩數量為例,來說明順序值的轉換 • 值得注意的是,這樣等距離的分配,保留了原先彼此順序的關係
有順序值的調整 • 溫度計碼法(Thermometer codes)的方式是將資料以不等比例的方式轉換,較能區分其中差異性,用在學習成績、債卷等級來說十分適合 • 以行銷實務上來說,沒有小孩的家庭是和有一個小孩的家庭是大大不同的 • 若超過8個以上的變項,使用溫度計碼就會減低它的效力
類別值的變項 • 性別、婚姻狀況(已婚、未婚、離婚) • 狀態號碼 • 產品號碼 • 郵遞區號
類別值的調整 • 將其當作是離散、有次序的值來處理 • 我們以婚姻狀態來說明 • 以網路觀點來說,調整後資料顯示,單身和未知是相當遙遠的,而離婚和結婚卻不是。這些無異議且不明確的次序會讓網路混淆,進而使的訓練無效果
類別值的調整 • 類別值較佳的調整方法為:Break the categories into flags • 我們可以將資料型態打破,使用N的編碼,指定為+1或-1的標旗,更可以將其中編碼簡化成為N-1的編碼 N Coding N-1 Coding
解釋結果 • 以連續值來說 在訓練集 (Training Set)中輸出值$103,000對應值-1而$250,000對應值1,若最終結果跑出來對應值是0的話,我們可以很清楚此值應該是: $103,000+$250,000/2=$176,500 • 以二位元或類別值來說 在訓練集 (Training Set)中,理想上會以0為分野,大於0歸為一類;小於0歸為一類;或是以-0.33及+0.33分為三個區段,但很多情況下,網路會產生居中的值,使得解讀十分困難,所以我們可以透過信心水準的方式來更準確的判定其中的值
以此圖來看,若以零為切斷點來分別A、B的話, 會判斷錯很多結果梢高於0的A,所以我們在此案例中選定切斷點0.35來作為區隔處