Stanford Streaming Supercomputer
Stanford Streaming Supercomputer. Eric Darve Mechanical Engineering Department Stanford University. Overview of Streaming Project. Main PIs: Pat Hanrahan, hanrahan@graphics.stanford.edu Bill Dally, billd@csl.stanford.edu Objectives: Cost/Performance: 100:1 compared to clusters.

Stanford Streaming Supercomputer
E N D
Presentation Transcript
Stanford Streaming Supercomputer Eric Darve Mechanical Engineering Department Stanford University
Overview of Streaming Project • Main PIs: • Pat Hanrahan, hanrahan@graphics.stanford.edu • Bill Dally, billd@csl.stanford.edu • Objectives: • Cost/Performance: 100:1 compared to clusters. • Programmable: applicable to large class of scientific applications. • Porting and developing new code made easier: stream language, support of legacy codes. Eric Darve - Stanford Streaming Supercomputer
Performance/Cost Cost estimate – about $1K/node Preliminary numbers, parts cost only, no I/O included. Expect 2x to 4x to account for margin and I/O Eric Darve - Stanford Streaming Supercomputer
News Center News Releases | Publications | Resources | Multimedia Gallery News Release Archive | Awards FOR IMMEDIATE RELEASE October 21, 2002 Sandia National Laboratories and Cray Inc. finalize $90 million contract for new supercomputer Collaboration on Red Storm System under Department of Energy’s Advanced Simulation and Computing Program (ASCI) ALBUQUERQUE, N.M. and SEATTLE, Wash. — The Department of Energy’s Sandia National Laboratories and Cray Inc. (Nasdaq NM: CRAY) today announced that they have finalized a multiyear contract, valued at approximately $90 million, under which Cray will collaborate with Sandia to develop and deliver a new massively parallel processing (MPP) supercomputer called Red Storm. In June 2002, Sandia reported that Cray had been selected for the award, subject to successful contract negotiations.
Performance/Cost Comparisons • Earth Simulator (today) • Peak 40TFLOPS, ~$450M • 0.09MFLOPS/$ • Sustained 0.03MFLOPS/$ • Red Storm (2004) • Peak 40TFLOPS, ~$90M • 0.44MFLOPS/$ • SSS (proposed 2006) • Peak 40TFLOPS, < $1M • 128MFLOPS/$ • Sustained 30MFLOPS/$ (single node) • Numbers are sketchy today, but even if we are off by 2x, improvement over status quo is large Eric Darve - Stanford Streaming Supercomputer
ES RedStorm SSS ASCI machines Desktop SSS GFLOPS Eric Darve - Stanford Streaming Supercomputer
How did we achieve that? Eric Darve - Stanford Streaming Supercomputer
VLSI Makes Computation Plentiful VLSI: very large-scale integration. This is the current level of computer microchip miniaturization (refers to microchips containing in the hundreds of thousands of transistors.) • Abundant, inexpensive arithmetic • Can put 100s of 64-bit ALUs on a chip • 20pJ per FP operation • (Relatively) high off-chip bandwidth • 1Tb/s demonstrated, 2nJ per word off chip • Memory is inexpensive $100/Gbyte nVidia GeForce4 ~120 Gflops/sec ~1.2 Tops/sec Velio VC3003 1Tb/s I/O BW Eric Darve - Stanford Streaming Supercomputer
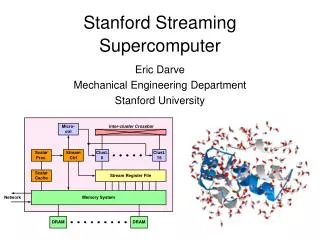
Current Architecture: few ALUs / chip = expensive and limited performance. Objective for SSS architecture: Keep hundreds of ALUs/chip busy. Difficulty: Locality of data: we need to match 20Tb/s ALU bandwidth to ~100Gb/s chip bandwidth. Latency tolerance:to cover 500 cycle remote memory access time. Chip 64-bit ALU (to scale) But VLSI imposes some constraints Architecture of Pentium 4 Arithmetic is cheap, global bandwidth is expensive Local << global on-chip << off-chip << global system Eric Darve - Stanford Streaming Supercomputer
The Stream Model exposes parallelism and locality in applications • Streams of records passing through kernels • Parallelism • Across stream elements • Across kernels • Locality • Within kernels • Producer-consumer locality between kernels Eric Darve - Stanford Streaming Supercomputer
Streams match scientific computation to constraints of VLSI Stream Cache Local Registers Memory Stream Reg File Grid of K1 5 5 Cells Cells 50 Ops 7 Indices K2 6 Table Table Results 1 100 Ops 8 0.5 8 Results 2 K3 3 3 70 Ops Results 2 8 K4 8 Results 3 80 Ops Indices 5 300 Ops Grid of 4 Results 4 900W Cells 9.5Words 12Words 58Words Stream program matches application to Bandwidth Hierarchy 32:4:1 Eric Darve - Stanford Streaming Supercomputer
Scientific programs stream well StreamFEM results show L:S:M ratios of 206:13:1 to 50:3:1 Eric Darve - Stanford Streaming Supercomputer
BW Hierarchy of SSS Eric Darve - Stanford Streaming Supercomputer
Stream processor = Vector processor + Local registers • Like a vector processor, stream processors • Amortize instruction overhead over records of a stream • Hide latency by loading (storing) streams of records • Can exploit producer consumer locality at the SRF (VRF) level • Stream processors add local registers and microcoded kernels • >90% of all references from local registers • Increases effective bandwidth and capacity of SRF (VRF) by 10x • Enables 10x number of ALUs • Enables SRF to capture working set Eric Darve - Stanford Streaming Supercomputer
Brook: streaming language • C with streaming • Make data parallelism explicit • Declare communication pattern • Streams • View of records in memory • Operated on in parallel • Accessing stream values not is permitted outside of kernels Kernel Eric Darve - Stanford Streaming Supercomputer
Kernel Brook Kernels • Kernels • Functions which operate only on streams • Stream arguments are read-only or write-only • Reduction variables (associative operations only) • Restricted communication between records • No state or “static” variables • No global memory access Eric Darve - Stanford Streaming Supercomputer
Brook Example: Molecular Dynamics struct Vector { float x, y, z ;} ; typedef stream struct Vector Vectors ; kernel void UpdatePosition ( Vectors sPos, Vectors sVel, const float timestep, out Vectors sNewPos ) { sNewPos.x = sPos.x + timestep * sVel.x; sNewPos.y = sPos.y + timestep * sVel.y; sNewPos.z = sPos.z + timestep * sVel.z; } Eric Darve - Stanford Streaming Supercomputer
struct Vector { float x, y, z ;} ; typedef stream struct Vector Vectors ; void main () { struct Vector Pos[MAX] = {…} ; struct Vector Vel[MAX] = {…} ; Vectors sPos, sVel, sNewPos ; streamLoad (sPos, Pos, MAX) ; streamLoad (sVel, Vel, MAX) ; UpdatePosition (sPos, sVel, 0.2f, sNewPos) ; streamStore (sNewPos, Pos) ; } Eric Darve - Stanford Streaming Supercomputer
StreamMD: motivation • Application: study the folding of human proteins. • Molecular Dynamics: computer simulation of the dynamics of macro molecules. • Why this application? • Expect high arithmetic intensity. • Requires variable length neighborlists. • Molecular Dynamics can be used in engine simulation to model spray, e.g. droplet formation and breakup, drag, deformation of droplet. • Test case chosen for initial evaluation: box of water molecules. DNA molecule Human immunodeficiency virus (HIV) Eric Darve - Stanford Streaming Supercomputer
Numerical Algorithm • Interaction between atoms is modeled by the potential energy associated to each configuration. Includes: • Chemical bond potentials. • Electrostatic interactions. • Van der Waals interactions. • Newton’s second law of motion used to compute the trajectory of all atoms: • Velocity Verlet time integrator (leap-frog): Eric Darve - Stanford Streaming Supercomputer
High-Level Implementation in Brook • Cutoff is used to compute non-bonded forces: two particles do not interact if they are at a distance larger than cutoff radius. • Gridding technique is used to accelerate search of all atoms within cutoff radius. • Stream of variable length is associated to each cell of the grid: contains all the water molecules inside the cell. • High level Brook functionality are used: • streamGatherOP: used to construct the list of all water molecules inside a cell. • streamScatterOP: used to reduce the partial forces computed for each molecule. Memory f+g (g) n++ GatherOP ScatterOP SRF n f Eric Darve - Stanford Streaming Supercomputer
FDIV FADD FDIV FSUB FSUB FSUB FSUB FSUB FSQRT SPREAD FSUB FMUL FMUL SPREAD FSUB FSUB 100 FADD FMUL SPREAD FSQRT FSUB FMUL FMUL FADD FMUL FADD FDIV FADD FDIV FSUB FSUB FSQRT FSUB FMUL FMUL FSUB FSUB FADD FMUL FSQRT FSUB FMUL FMUL FADD FADD FMUL FDIV FADD FDIV SPREAD SPREAD FSUB FSUB SPREAD FSQRT FSUB 160 FSUB FMUL FMUL FSUB FADD FMUL FSQRT FSUB FMUL FMUL FADD FADD FMUL FDIV FADD PASS FSUB FSUB FDIV FSUB FMUL FMUL FADD FMUL FADD FSUB FSQRT FDIV FMUL FMUL FADD FMUL FMUL FMUL FMUL FSQRT FADD FMUL FADD FADD FMUL FSQRT FMUL FMUL FMUL FADD FMUL FADD FMUL FMUL FMUL FADD 220 FADD FMUL FMUL PASS FMUL PASS PASS FLE FMUL FADD FMUL FMUL NSELECT FMUL FMUL FMUL FMUL FMUL FADD FMUL FMUL FMUL FDIV FMUL FMUL FMUL FMUL PASS FADD FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FADD FMUL FMUL PASS FMUL FMUL FMUL FMUL FADD FADD FMUL FMUL FADD FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FADD FMUL FMUL FMUL FMUL PASS FMUL FMUL SELECT FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FSUB FMUL FMUL PASS PASS FMUL FMUL FADD FADD PASS FLE FMUL FMUL FADD FADD FADD FMUL FMUL FADD FMUL FMUL PASS PASS FADD FMUL FMUL PASS FADD FMUL FMUL FADD FADD FMUL FMUL FADD FADD FADD FADD FADD FADD FMUL FMUL FADD FADD FADD FMUL FADD FMUL FADD FADD PASS FADD FADD FADD SPREAD FADD FADD FADD FMUL SELECT SPREAD PASS FADD FSUB FADD FMUL SELECT FSUB FADD FADD PASS SPREAD FADD FADD SPREAD SELECT FADD FADD FSUB FADD SELECT SPREAD SELECT FADD FADD FSUB PASS SELECT SPREAD SELECT FSUB FADD FMUL SELECT SPREAD SPWRITE SELECT FADD FSUB FADD SELECT SPREAD SPWRITE SELECT FSUB FADD SELECT SPREAD SPWRITE SELECT FADD FADD FSUB SELECT SPWRITE SELECT FADD FSUB FADD PASS SELECT SPWRITE SELECT FADD FADD FADD SELECT SPWRITE SELECT FADD FADD SPWRITE DEC_CHK_UCR 280 SPWRITE LOOP DEC_UCR 32 SPWRITE IADD PASS PASS NSELECT DATA_OUT NSELECT DATA_OUT 340 StreamMD Results 120 FSUB FSUB FSUB FLT FABS FABS FLT FLT FLT SELECT FABS FLT SELECT NSELECT FSUB FLT SPREAD NSELECT FSUB FSUB SELECT SPREAD FSUB SPREAD NSELECT FSUB SPREAD FSUB SPREAD FSUB FSUB FSUB SPREAD PASS FSUB FSUB FSUB SPREAD FSUB FSUB SPREAD • Preliminary schedule obtained using the Imagine architecture: • High arithmetic intensity: all ALUs are kept busy. Gflops expected to be very high. • SRF bandwidth is sufficient. About 1 word for 30 instructions. • Results helped guide architectural decisions for SSS. FSUB FMUL FSUB FMUL FSUB FSUB FMUL FSUB FMUL SPREAD FSUB FSUB PASS PASS FSUB FSUB FMUL FMUL FMUL FMUL FADD FADD FMUL FSUB FMUL FSUB FMUL FSUB FMUL FINVSQRT_LOOKUP FADD FMUL FADD FSUB PASS FSUB FMUL FADD FADD PASS FSUB FSUB FMUL FMUL FMUL FADD FMUL FINVSQRT_LOOKUP FADD PASS FINVSQRT_LOOKUP PASS FMUL FMUL FADD PASS FSUB FMUL FMUL FMUL FADD FSUB FSUB FMUL FINVSQRT_LOOKUP FADD FSUB FMUL PASS FMUL FMUL FSUB FMUL FADD FSUB PASS FMUL FSUB FADD FMUL FINVSQRT_LOOKUP FSUB FSUB FMUL FMUL FINVSQRT_LOOKUP FSUB FMUL FMUL FSUB FADD FMUL FMUL FSUB FMUL FADD FINVSQRT_LOOKUP FMUL FSUB FSUB FMUL PASS FMUL FMUL FMUL FMUL PASS FMUL FMUL FADD FMUL FINVSQRT_LOOKUP FMUL FADD FMUL FMUL FSUB PASS 170 FSUB FMUL FMUL FSUB PASS FADD FADD FMUL FMUL FMUL FINVSQRT_LOOKUP FSUB FMUL FMUL FMUL FMUL FMUL FMUL FINVSQRT_LOOKUP FMUL FADD FINVSQRT_LOOKUP FMUL FMUL FSUB PASS FMUL FMUL FMUL FMUL FMUL FMUL FMUL FSUB FINVSQRT_LOOKUP FMUL FMUL FMUL FMUL FMUL FMUL FSUB PASS FMUL FMUL FSUB FSUB FMUL FMUL FMUL FSUB FSUB FSUB FMUL FMUL PASS FMUL FMUL FMUL FMUL FMUL PASS FSUB FMUL FMUL FMUL FMUL FMUL FMUL FSUB FMUL FSUB FMUL FMUL FMUL FMUL FMUL FMUL FSUB FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FSUB FMUL FMUL FMUL FMUL FMUL FADD FMUL PASS FMUL FMUL FMUL FMUL FMUL FSUB FMUL FADD FMUL FMUL PASS FMUL FSUB FMUL FMUL FMUL FSUB FADD FMUL FMUL FMUL PASS PASS FMUL FADD FADD FSUB FMUL FMUL FMUL FMUL FADD FLE FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL FADD PASS FADD FMUL FADD FMUL PASS FMUL FMUL FMUL FMUL FADD FMUL FMUL 220 FMUL FMUL FMUL FMUL FMUL FMUL FLE FADD FMUL FMUL FMUL FMUL FMUL FADD FMUL FMUL FMUL FMUL FMUL FADD FADD FADD FMUL FMUL PASS PASS FMUL PASS NSELECT FMUL FMUL FMUL FMUL PASS FMUL FMUL FMUL FADD NSELECT PASS FMUL FMUL FMUL PASS PASS FMUL FMUL FMUL FMUL PASS FMUL FMUL FMUL FMUL PASS FADD FMUL FMUL FMUL PASS FMUL FMUL FMUL FMUL PASS FMUL FMUL FMUL FMUL FMUL FMUL FMUL FMUL PASS FSUB FMUL FMUL FADD PASS PASS FMUL FMUL FMUL FMUL FADD FMUL FMUL FMUL FMUL FMUL FADD FADD PASS FMUL FMUL FMUL FMUL FMUL FMUL FMUL FADD PASS FMUL FADD FMUL FMUL PASS FADD FADD FMUL FMUL PASS FMUL FMUL FADD FADD FMUL FADD FADD FADD FMUL FADD FADD FMUL PASS FADD FADD FMUL FADD FADD FADD FADD FADD PASS FADD FADD FMUL FADD NSELECT SPREAD FADD FADD FADD FMUL SPREAD FADD FADD FADD FSUB SPREAD SELECT FSUB FADD FADD FADD NSELECT SPREAD SELECT FSUB FADD FADD NSELECT SPREAD PASS FSUB FADD FADD NSELECT SPREAD SELECT FMUL FSUB FADD NSELECT SPREAD SPWRITE SELECT FADD FSUB FADD NSELECT SPREAD SPWRITE SELECT FSUB NSELECT SPREAD SPWRITE SELECT 260 FSUB NSELECT SPWRITE SELECT FSUB FADD FADD SPWRITE SELECT FADD SPWRITE SELECT SPWRITE DEC_CHK_UCR SPWRITE DEC_UCR LOOP 32 SPWRITE PASS T DATA_OUT DATA_OUT NSELECT Imagine SSS Eric Darve - Stanford Streaming Supercomputer
Observations • Arithmetic intensity is sufficient. Bandwidth is not going to be the limiting factor in these applications. Computation can be naturally organized in a streaming fashion. • The interaction between the application developers and the language development group has helped insured that Brook can be used to code real scientific applications. • Architecture has been refined in the process of evaluating these applications. • Implementation is much easier than MPI. Brook hides all the parallelization complexity from the user. The code is very clean and easy to understand. The streaming versions of these applications are in the range of 1000-5000 lines of code. Eric Darve - Stanford Streaming Supercomputer
A GPU is a stream processor • The GPU on a Graphics Card is streaming processor. • n VIDIA recently announced that their latest graphics card, the NV30, will be programmable and capable of delivering 51 Gflops peak performance (1.6 Gflops for Pentium 4). Can we use this computing power for scientific application? Eric Darve - Stanford Streaming Supercomputer
Cg: Assembly or High-level? Assembly … DP3 R0, c[11].xyzx, c[11].xyzx; RSQ R0, R0.x; MUL R0, R0.x, c[11].xyzx; MOV R1, c[3]; MUL R1, R1.x, c[0].xyzx; DP3 R2, R1.xyzx, R1.xyzx; RSQ R2, R2.x; MUL R1, R2.x, R1.xyzx; ADD R2, R0.xyzx, R1.xyzx; DP3 R3, R2.xyzx, R2.xyzx; RSQ R3, R3.x; MUL R2, R3.x, R2.xyzx; DP3 R2, R1.xyzx, R2.xyzx; MAX R2, c[3].z, R2.x; MOV R2.z, c[3].y; MOV R2.w, c[3].y; LIT R2, R2; ... or PhongShader Cg COLOR cPlastic = Ca + Cd * dot(Nf, L) + Cs * pow(max(0, dot(Nf, H)), phongExp); Eric Darve - Stanford Streaming Supercomputer
Cg uses separate vertex and fragment programs VertexProcessor FragmentProcessor FramebufferOperations Assembly &Rasterization Application Framebuffer Textures Program Program Eric Darve - Stanford Streaming Supercomputer
Characteristics of NV30 & Cg • Characteristics of GPU: • optimized for 4-vector arithmetic • Cg has vector data types and operationse.g. float2, float3, float4 • Cg also has matrix data typese.g. float3x3, float3x4, float4x4 • Some Math: • Sin/cos/etc. • Normalize • Dot product:dot(v1,v2); • Matrix multiply: • matrix-vector: mul(M, v); // returns a vector • vector-matrix: mul(v, M); // returns a vector • matrix-matrix: mul(M, N); // returns a matrix Eric Darve - Stanford Streaming Supercomputer
Example: MD Innermost loop in C: computation of LJ and Coulomb interactions. for (k=nj0;k<nj1;k++) { //loop over indices in neighborlist jnr = jjnr[k]; //get index of next j atom (array LOAD) j3 = 3*jnr; //calc j atom index in coord & force arrays jx = pos[j3]; //load x,y,z coordinates for j atom jy = pos[j3+1]; jz = pos[j3+2]; qq = iq*charge[jnr]; //load j charge and calc. product dx = ix – jx; //calc vector distance i-j dy = iy – jy; dz = iz – jz; rsq = dx*dx+dy*dy+dz*dz; //calc square distance i-j rinv = 1.0/sqrt(rsq); //1/r rinvsq = rinv*rinv; //1/(r*r) vcoul = qq*rinv; //potential from this interaction fscal = vcoul*rinvsq; //scalarforce/|dr| vctot += vcoul; //add to temporary potential variable fix += dx*fscal; //add to i atom temporary force variable fiy += dy*fscal; //F=dr*scalarforce/|dr| fiz += dz*fscal; force[j3] -= dx*fscal; //subtract from j atom forces force[j3+1]-= dy*fscal; force[j3+2]-= dz*fscal; }
Inner loop in Cg /* Find the index and coordinates of j atom */ jnr = f4tex1D (jjnr, k); /* Get the atom position */ j1 = f3tex1D(pos, jnr.x); j2 = f3tex1D(pos, jnr.y); j3 = f3tex1D(pos, jnr.z); j4 = f3tex1D(pos, jnr.w); We are fetching coordinates of atom: data is stored as texture We compute four interactions at a time so that we can take advantage of high performance of vector arithmetic. Eric Darve - Stanford Streaming Supercomputer
/* Get the vectorial distance, and r^2 */ d1 = i - j1; d2 = i - j2; d3 = i - j3; d4 = i - j4; rsq.x = dot(d1, d1); rsq.y = dot(d2, d2); rsq.z = dot(d3, d3); rsq.w = dot(d4, d4); /* Calculate 1/r */ rinv.x = rsqrt(rsq.x); rinv.y = rsqrt(rsq.y); rinv.z = rsqrt(rsq.z); rinv.w = rsqrt(rsq.w); Computing the square of distance We use built-in dot product for float3 arithmetic Built-in function: rsqrt
Highly efficient float4 arithmetic /* Calculate Interactions */ rinvsq = rinv * rinv; rinvsix = rinvsq * rinvsq * rinvsq; vnb6 = rinvsix * temp_nbfp; vnb12 = rinvsix * rinvsix * temp_nbfp; vnbtot = vnb12 - vnb6; qq = iqA * temp_charge; vcoul = qq*rinv; fs = (12f * vnb12 - 6f * vnb6 + vcoul) * rinvsq; vctot = vcoul; /* Calculate vectorial force and update local i atom force */ fi1 = d1 * fs.x; fi2 = d2 * fs.y; fi3 = d3 * fs.z; fi4 = d4 * fs.w; This is the force computation
Computing total force due to 4 interactions ret_prev.fi_with_vtot.xyz += fi1 + fi2 + fi3 + fi4; ret_prev.fi_with_vtot.w += dot(vnbtot, float4(1, 1, 1, 1)) + dot(vctot, float4(1, 1, 1, 1)); Computing total potential energy for this particle Return type is: struct inner_ret { float4 fi_with_vtot; }; Contains x, y and z coordinates of force and total energy.
Conclusion • 3 representative applications show high bandwidth ratios: streamMD, streamFlo, StreamFEM. • Feasibility of streaming established for scientific applications: high arithmetic intensity, bandwidth hierarchy is sufficient. • Available today: NVidia NV30 graphics card. • Future work: • StreamMD to GROMACS (Folding @ Home) • StreamFEM and StreamFLO to 3D • Multinode versions of all applications • Sparse solvers for implicit time-stepping • Adaptive meshing • Numerics Eric Darve - Stanford Streaming Supercomputer