Download

1 / 32
320 likes | 409 Views
Researching text collections for Croatian news, applying language and knowledge technologies for text analysis and information retrieval, collaborative projects with universities.

E N D
Language and Knowledge Technologies for News Collections in Croatia Bojana Dalbelo Bašić, Marko Tadić University of Zagreb,Faculty of Electrical Engineering and Computing / Faculty of Humanities and Social Sciences bojana.dalbelo@fer.hr, marko.tadic@ffzg.hr ITN2008Dubrovnik2008-05-21 ITN2008Dubrovnik 2008-05-21
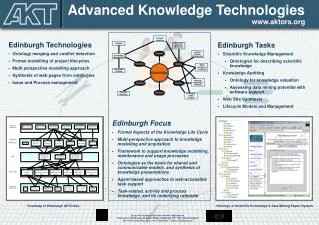
Talk overview • who we are? • what are we doing? • text collections used for research • applicable language technologies • applicable knowledge technologies ITN2008Dubrovnik 2008-05-21
Who we are? • University of Zagreb, Croatia • two faculties in a joint mission • build the systems that will develop and enable the usage of language resources and tools for Croatian ITN2008Dubrovnik 2008-05-21
Who we are 2? • Faculty of Humanities andSocial Sciences • Institute/Department ofLinguistics • Department of InformationSciences • basic computational linguistic tasks for Croatian • compiling and processing large language resources • Croatian National Corpus, Croatian Morphological Lexicon, Croatian WordNet, Croatian Dependency Treebank • digitalization of Croatian lexicographic heritage:60+ dictionaries digitalized so far • tagger, lemmatizer • chunker, parser • NERC system, gazeteers (e.g. Croatian (sur)names) ITN2008Dubrovnik 2008-05-21
Who we are 3? • Faculty of Electrical Engineering and Computing • Department of Electronics, Microelectronics, Computer and Intelligent Systems / KTLab • Knowledge Technogies Laboratory Group deals with • text preprocessing techniques for Croatian for machine learning procedures • dimensionality reduction and document clustering in the vector space model + visualisation • automatic indexing ofdocuments • intelligent, language specificand non-specific informationretrieval and extraction ITN2008Dubrovnik 2008-05-21
What are we doing? • working jointly on several research projects • AIDE: Automatic Indexing with Descriptors from Eurovoc (cooperation with the Government of the Republic of Croatia, HIDRA) • Institute of Linguistics/FFZG & ZEMRIS/FER, 2006-2008 • Computational Linguistic Models and Language Technologies for Croatian (rmjt.ffzg.hr), 2007-2011 • national research programme, prof. Marko Tadić • Sources for Croatian Heritage and Croatian European Identity, 2007-2011 • national research programme, prof. Damir Boras • CADIAL: Computer Aided Document Indexing for Accessing Legislation • joint Flemish-Croatian project, 2007-2009 • prof. Marie-Francine Moens & prof. Bojana Dalbelo Bašić ITN2008Dubrovnik 2008-05-21
What are we doing 2? • Composition of the programme RMJT • P1: Croatian language resources and their annotation • project leader: Marko Tadić • P2: Computational syntax of Croatian • project leader: Zdravko Dovedan • P3: Lexical semantics in building Croatian WordNet • project leader: Ida Raffaelli • P4: Information technology in translating Croatian and language e-learning • project leader: Sanja Seljan • P5: Knowledge discovery in textual data • project leader: Bojana Dalbelo Bašić • participation in a FP7 project CLARIN • LR & LT as a research infrastructure for e-SSH ITN2008Dubrovnik 2008-05-21
Text collections used for research • we have done research on different kinds of texts, but predominantly in journalistic genre • Croatian National Corpus (hnk.ffzg.hr) • 101,2 million tokens in size • newspaper articles: 37% (ca 37 million tokens) • magazines articles: 16% (ca 16 million tokens) • Croatian-English Parallel Corpus • 3,5 million tokens from Croatian Weekly • newspaper articles: 100%, bilingual • special text collections • database of Vjesnik articles: 2000-2003, >90,000 articles • Narodne novine collection: 1998-2008, >10,000 texts, >15 million tokens • Parallel corpus of Southeast European Times: 2007-, >25,000 articles, >4 million tokens, in 10 languages ITN2008Dubrovnik 2008-05-21
Applicable language technologies • morphological processing • important for inflectionally rich languages, e.g. • Croatian noun in 14 word-forms (7 cases, 2 numbers): N: student studenti G: studenta studenata D: studentu studentima A: studenta studente V: studentu studenti L: studentu studentima I: studentom studentima • unlike English noun in 2(4?) word-forms (2 numbers+ possesive?): Sg: student Poss: (student’s) Pl: students Poss: (students’) • present in all Slavic languages (excl. Bulgarian), German, Greek, Baltic languages, Finnish, ... ITN2008Dubrovnik 2008-05-21
Applicable language technologies 2 • recognizing to which lexeme(s) a WF belongs to • helps us in avoiding the problem of data sparsness in many text processing tasks: • information retrieval • text mining • document classification • document indexing • query processing • search engines are not “inflectionally sensitive” • speakers of inflectionally rich language use the normal/base form = lemma • e.g. www.google.hr input: noun in nominative singular • did you know that accusative and genitive are more frequent in Croatian? ITN2008Dubrovnik 2008-05-21
Applicable language technologies 3 ITN2008Dubrovnik 2008-05-21
Applicable language technologies 4 ITN2008Dubrovnik 2008-05-21
Applicable language technologies 5 ITN2008Dubrovnik 2008-05-21
Applicable language technologies 6 • Named Entity Recognition and Classification (NERC) • NEs are introducing the exact information from outer world into the world-of-text • represent answers to the basic journalistic questions: who?, where?, when?, how much? • types of NEs (according to MUC conferences) • person • organization • location • date • time • valute and measurements • percentage • system that works for Croatian with >90% precision ITN2008Dubrovnik 2008-05-21
Applicable language technologies 7 • system that works for Croatian with >90% precision ITN2008Dubrovnik 2008-05-21
Applicable language technologies 8 • semantic networks as language resources • covering the general lexicon and NEs in a language • WordNet: words are linked by meaning • synonyms, antonyms, hypo-/hyperonyms, meronyms… • realized as ontologies or taxonomies • allow for words and/or NEs • synonymy/antonymy search • evoking upper-levels in taxonomy • e.g. activating the region/state/continent when a city is mentioned or a company when a director is in focus • explicit social networking connections between NEs ITN2008Dubrovnik 2008-05-21
Applicable L&K technologies ITN2008Dubrovnik 2008-05-21
Applicable L&K technologies ITN2008Dubrovnik 2008-05-21
Applicable language technologies 8 • semantic networks as language resources • covering the general lexicon and NEs in a language • WordNet: words are linked by meaning • synonyms, antonyms, hypo-/hyperonyms, meronyms… • realized as ontologies or taxonomies • allow for words and/or NEs • synonymy/antonymy search • evoking upper-levels in taxonomy • e.g. activating the region/state/continent when a city is mentioned or a company when a director is in focus • explicit social networking connections between NEs • semantic processing: roles in sentences (agent, patient, instrument etc.) ITN2008Dubrovnik 2008-05-21
Applicable language technologies 8 • semantic networks as language resources • covering the general lexicon and NEs in a language • WordNet: words are linked by meaning • synonyms, antonyms, hypo-/hyperonyms, meronyms… • realized as ontologies or taxonomies • allow for words and/or NEs • synonymy/antonymy search • evoking upper-levels in taxonomy • e.g. activating the region/state/continent when a city is mentioned or a company when a director is in focus • explicit social networking connections between NEs • semantic processing: roles in sentences (agent, patient, instrument etc.) • event detection: from verbal frames and scenarios ITN2008Dubrovnik 2008-05-21
Applicable language technologies 8 • semantic networks as language resources • covering the general lexicon and NEs in a language • WordNet: words are linked by meaning • synonyms, antonyms, hypo-/hyperonyms, meronyms… • realized as ontologies or taxonomies • allow for words and/or NEs • synonymy/antonymy search • evoking upper-levels in taxonomy • e.g. activating the region/state/continent when a city is mentioned or a company when a director is in focus • explicit social networking connections between NEs • semantic processing: roles in sentences (agent, patient, instrument etc.) • event detection: from verbal frames and scenarios • connection with geo-data ITN2008Dubrovnik 2008-05-21
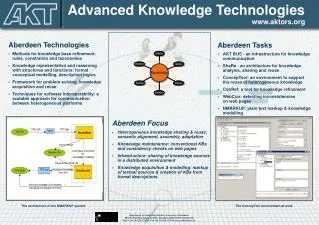
Applicable knowledge technologies • automatic document indexing • eCADIS system • developed for Croatian legal docs • applicable to any document collection • uses machine learning techniques • automatically attaches the keywords (descriptors) from a controlled thesaurus to a document • represent the document content description • integrates the corpus and document analysis ITN2008Dubrovnik 2008-05-21
CADIS system ITN2008Dubrovnik 2008-05-21
ITN2008Dubrovnik 2008-05-21
eCADIS system • integrates the information from the whole document collection • greyed n-grams are statistically relevant in the corpus i.e. collocations ITN2008Dubrovnik 2008-05-21
eCADIS system • automatic suggestion of relevant descriptors, hence the automatic indexing ITN2008Dubrovnik 2008-05-21
eCADIS system • compare it to manually attached descriptors… ITN2008Dubrovnik 2008-05-21
Applicable knowledge technologies • automatic document classification • uses a series of classifiers, combined 3500 classifiers • results represented in a vector-space model • dimensionality reduction • matrices could be huge (Vjesnik: 90,000 x 600,000) • features selected • types • lemmas • collocations • NEs • … • evaluated by F1 measure (combination of precision/recall) • F1 > 90% in most of cases ITN2008Dubrovnik 2008-05-21
Applicable knowledge technologies • visualisationof classification between pages • Croatia Weekly • English side • go= economyks = culture/sportte = turism/ecol.po = politics ITN2008Dubrovnik 2008-05-21
Applicable knowledge technologies • visualisationof classification between culture (low right) and sport (high left) • Croatia Weekly • English side • go= economyks = culture/sportte = turism/ecol.po = politics ITN2008Dubrovnik 2008-05-21
Applicable knowledge technologies • visualisationof classification for documents that differentiate between home (blue upward) and foreign policy (blue downward) • Croatia Weekly • English side • go= economyks = culture/sportte = turism/eco.po = politics ITN2008Dubrovnik 2008-05-21
Language and Knowledge Technologies for News Collections in Croatia Bojana Dalbelo Bašić, Marko Tadić University of Zagreb,Faculty of Electrical Engineering and Computing / Faculty of Humanities and Social Sciences bojana.dalbelo@fer.hr, marko.tadic@ffzg.hr ITN2008Dubrovnik2008-05-21 ITN2008Dubrovnik 2008-05-21