Download

1 / 31
310 likes | 472 Views
Cap. 4 Controllo genetico delle proteine pp. 94-111. Sintesi 04. Ogni sequenza di amminoacidi in un peptide è codificata da una sequenza di nucleotidi in un gene Le prime relazioni ipotizzate fra DNA e proteine sono state: un gene – un enzima e un gene – un polipeptide

E N D
Sintesi 04 • Ogni sequenza di amminoacidi in un peptide è codificata da una sequenza di nucleotidi in un gene • Le prime relazioni ipotizzate fra DNA e proteine sono state: un gene – un enzima e un gene – un polipeptide • Colinearità: una sequenza di nucleotidi – una sequenza polipeptidica • I geni controllano le reazioni metaboliche controllando la produzione di enzimi; alterazioni della sequenza genica si riflettono in alterazioni della sequenza proteica • Nei vertebrati, meno del 10% del genoma codifica per proteine; il dibattito su ruolo e funzione del restante 90% è aperto
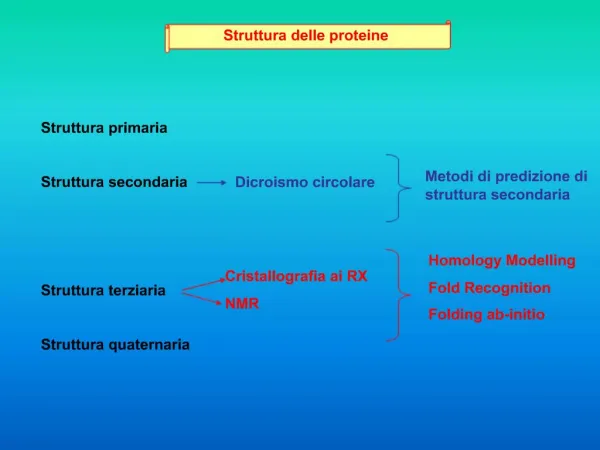
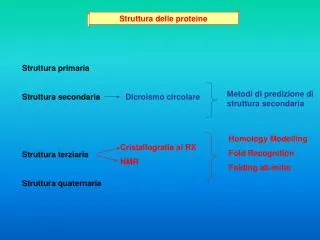
Le proteine hanno: • Una struttura primaria, data dalla successione degli amminoacidi nel peptide • Una struttura secondaria, cioè un andamento regolare in alcuni tratti, dovuto al ripetersi periodico di amminoacidi con caratteristiche costanti. Es.: -elica, foglietto • Una struttura terziaria, tridimensionale, dovuta alle interazioni fra amminoacidi, e fra amminoacidi e ambiente • (non sempre) una struttura quaternaria, quando diversi peptidi si uniscono a formare una proteina complessa, multimerica Che rapporti fra proteine e geni?
Analisi biochimica delle malattie metaboliche: alcaptonuria Fenotipo: urina scura
Genetica biochimicaBeadle e Tatum: un gene – un enzima Colture di Neurospora Terreno minimo: Sali inorganici, una fonte di C (glucosio o saccarosio), una fonte di N, biotina Terreno completo: terreno minimo + tutti gli amminoacidi, tutti i nucleotidi e vitamine Indvidui prototrofi e auxotrofi (o mutanti nutrizionali)
Esperimenti di Beadle e Tatum Mutanti di Neurospora auxotrofi per l’arginina, o arg- Ceppi diversi portano la mutazione in tre diverse regioni del genoma: arg-1, arg-2 e arg-3 Mutanti arg-3 crescono solo se al terreno minimo si aggiunge arginina; mutanti arg-2 se vengono aggiunte arginina o citrullina; mutanti arg-1 se vengono aggiunte arginina o citrullina o ornitina
Esperimenti di Beadle e Tatum: un gene – un enzima Conclusioni: arg-1, arg-2 e arg-3 codificano per tre enzimi che intervengono in successione nella conversione di un precursore in ornitina, di questa in citrullina, e di questa in arginina arg-1 arg-2arg-3 enzima 1 enzima 2 enzima 3 precursore ornitina citrullina arginina
Beadle e Tatum deducono le catene di rezioni biochimiche (e l’ordine di azione dei geni) dalle molecole che si accumulano nei mutanti
Welcome to OMIM, Online Mendelian Inheritance in Man. This database is a catalog of human genes and genetic disorders authored and edited by Dr. Victor A. McKusick and his colleagues at Johns Hopkins and elsewhere, and developed for the World Wide Web by NCBI, the National Center for Biotechnology Information. The database contains textual information and references. It also contains copious links to MEDLINE and sequence records in the Entrez system, and links to additional related resources at NCBI and elsewhere. http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?db=OMIM
Sequenza proteica: determinabile con il metodo di Sanger • Si purifica la proteina, cioè la si separa da impurità e da altre specie chimiche; • La si degrada per mezzo di enzimi proteolitici, ognuno dei quali agisce solo se c’è uno specifico amminoacido all’estremità carbossi-terminale.
Yanofsky: Colinearitàgene TrpA di Escherichia coli wt TYR LEU THR GLY 1 2 3 4 CYS LEU THR GLY TYR ARG THR GLY TYR LEU ILE GLY TYR LEU THR ARG Diversi mutanti (1-4) non sintetizzano triptofano perché l’enzima necessario (TrpA) è modificato. La posizione dell’amminoacido alterato nei mutanti può essere determinata per sequenziamento peptidico
Yanofsky: Colinearitàgene TrpA di Escherichia coli wt TYR LEU THR GLY 1 2 3 4 CYS LEU THR GLY TYR ARG THR GLY TYR LEU ILE GLY TYR LEU THR ARG ATA GAC TAT GGG ACA GCC TGT AGG mut1 mut2 mut3 mut4 Corrispondenza fra le posizioni di mutazione nucleotidica e sostituzione amminoacidica
Tutto il DNA fa proteine? NO: Nell’uomo, 3 miliardi di bp; 30 000 geni Dimensioni medie di un gene 10 000 bp Totale geni umani 300 milioni di bp 10% del genoma E il resto? Regioni non geniche: --GTTCCACACACACACACACACACACACACACATTA— DNA spazzatura (junk DNA)?
Cosa fa il DNA non genico? • Regola il funzionamento degli altri geni (Zuckerkandl) • Niente, ma male non fa: junk DNA (Ohno) • Parassita il resto del DNA: selfish DNA (Orgel e Crick; Dawkins) • Fa da scheletro al resto del DNA (Cavalier-Smith)
Cosa fa il DNA non genico? • Regola il funzionamento degli altri geni (Zuckerkandl) • Niente, ma male non fa: junk DNA (Ohno) • Parassita il resto del DNA: selfish DNA (Orgel e Crick; Dawkins) • Fa da scheletro al resto del DNA (Cavalier-Smith) • Qualche dato: • La perdita di ampli tratti di DNA non genico non ha effetti fenotipici: 1. non valida il generale. • Replicare una grande quantità di DNA è costoso: 2. poco probabile. • In certi casi, variazioni del volume cromosomico provocano variazioni del volume del nucleo, ma 4. non è valida il generale.
Cosa c’è in un cromosoma tipico 35% LINE: Long Intespersed Elements SINE: Short Intespersed Elements
DNA ripetuto: tandem repeats, Elementi interdispersi corti (SINE) e lunghi (LINE) Short tandem repeats, o STR (microsatellite): 1-6 bp, ripetuti da alcune volte a decine di volte Variable-number of tandem repeats, o VNTR (minisatellite): più lunghi, ripetuti da alcune volte a decine di volte 100-300 bp 5000-35000 bp
DNA fingerprinting Alec Jeffreys et al.: Hypervariable minisatellite regions in human DNA, Nature, 314:67-73, 1985.
DNA fingerprinting in Yersinia pestis 1.: antiqua 2.: medievalis 3.: orientalis 4., 5. ceppi sconosciuti
Riassunto 04 • Beadle e Tatum dimostrano in Neurospora che c’è una corrispondenza diretta un gene – un enzima • Yanofsky dimostra in E. coli la colinearità fra sequenza di nucleotidi e sequenza polipeptidica • Alterazioni della sequenza genica si riflettono in alterazioni della sequenza proteica: malattie del metabolismo • Nei vertebrati, meno del 10% del genoma codifica per proteine; il dibattito su ruolo e funzione del restante 90% è aperto