Download

1 / 22
230 likes | 472 Views
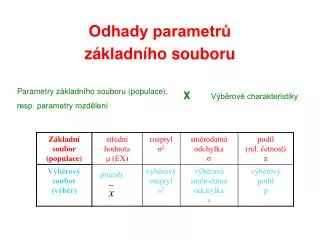
Teória štatistického odhadu (TO). Podstatou teórie odhadu je neznáme parametre základného súboru odhadovať pomocou výberových charakteristík. Rozlišujeme: 1. Bodový odhad 2. Intervalový odhad. Bodový odhad

E N D
Teória štatistického odhadu (TO) Podstatou teórie odhadu je neznámeparametre základného súboru odhadovať pomocou výberových charakteristík Rozlišujeme: 1. Bodový odhad 2. Intervalový odhad
Bodový odhad Základom bodového odhadu je odhadnúť parameter G základného súboru pomocou údajov z výberového súboru, tj. pomocou výberovej charakteristiky un . Parameter pritom odhadujeme jedným číslom, (jedným bodom) odtiaľ názov bodový odhad tj.: un = G resp. čo čítame : estimátorom (odhadom ) parametra Gje un . Výberová charakteristika je náhodná premenná, ktorej hodnoty sa menia v závislosti od toho, ktoré jednotky základného súboru tvoria výberový súbor. Rozdiel medzi G a un definuje chybu odhadu tj.: Prirodzenou požiadavkou je, aby chyba odhadu bola čo najmenšia. To dosiahneme vtedy ak výberová charakteristika spĺňa základné vlastnosti bodových odhadov.
K odhadu charakteristiky G základného súboru nevolíme teda akúkoľvek štatistiku, ale takú štatistiku, ktorá spĺňa určité kritéria – vlastnosti . Uvedieme tie najdôležitejšie: • Neskreslenosť • Konzistentnosť • Výdatnosť • Postačujúcnosť
neskreslenosť • Najdôležitejšou vlastnosťou je aby zvolená štatistika neviedla k systematickému nadhodnocovaniu či podhodnocovaniu, tj. aby neviedla k systematickým chybám. Požadujeme teda, aby stredná hodnota výberovej štatistiky bola rovná odhadovanej charakteristike. Ak platí: • nazývame výberovú štatistiku neskresleným (nevychýleným, nestranným) odhadom charakteristiky základného súboru. Rozdiel: • nazývame skreslením (vychýlením). Ak pri rastúcich rozsahoch výberu sa skreslenie stráca tj.: • hovoríme o asymptoticky neskreslenom odhade.
2. konzistencia tj výberová charakteristika un je konzistentným odhadom parametra G základného súboru, ak sa so zväčšovaním rozsahu výberového súboru výberová charakteristika blíži parametru G. Podmienka konzistencie teda vyjadruje požiadavku, aby s rastúcim rozsahom výberu rástla aj pravdepodobnosť toho, že použitá štatistika un sa bude líšiť od skutočnej hodnoty parametra základného súboru G len veľmi málo ε > 0. tj.:
3. výdatnosť tj. výdatným odhadom parametra G základného súboru nazývame takú charakteristiku un , ktorej rozptyl je zo všetkých výberových charakteristík poskytujúcich neskreslený odhad parametra G najmenší. 4. postačujúcnosť Výberová štatistika je postačujúcou, ak okrem nej neexistuje žiadna iná štatistika, ktorá by poskytovala ďalšie doplňujúce informácie o odhadovanej charakteristike základného súboru
K bodovému odhadu parametrov základného súboru najčastejšie využívame tieto metódy: • - metóda momentov • - metóda maximálnej vierohodnosti • - metóda najmenších štvorcov.
Na základe vlastností, ktoré musí spĺňať výberová charakteristika, platí, že výberový priemer , je, neskresleným konzistentným a výdatným odhadom strednej hodnoty základného súboru , čozapíšeme: a čítame: estimátorom (bodovým odhadom) strednej hodnoty základného súboru je výberový priemer . Ak odhadujeme priemer základného súboru výberovým priemerom dopúšťame sa chyby odhadu, ktorú definujeme: pričom jej veľkosť nevieme presne určiť. Ale môžeme odhadnúť tzv. štandardnú chybu odhadu,ktorá predstavuje priemernú veľkosť chýb odhadov pri mnohokrát opakovaných výberoch daného rozsahu. Štandardnú chybu pri známej štandardnej odchýlke základného súboru a rozsahu výberového súboru vypočítame
Avšak štandardnú odchýlku základného súboru často nepoznáme, preto nemôžeme štandardnú chybu výberového priemeru určiť presne, a tak ju odhadujeme pomocou výberovej štandardnej chyby odhadu výberového priemeru , ktorú definujeme
Pre rozptyl základného súboru platí, že jeho bodovým odhadom (neskresleným konzistentným a výdatným), je výberový rozptyl tj.: čo čítame: estimátorom (bodovým odhadom) rozptylu základného súboru je výberový rozptyl , ktorý vypočítame podľa vzťahu Pre štandardnú odchýlku základného súboru platí, že jej bodovým odhadom, (neskresleným konzistentným a výdatným), je výberová štandardná odchýlka čo čítame: estimátorom, (bodovým odhadom) štandardnej odchýlky základného súboru je výberová štandardná odchýlka , ktorú vypočítame ako odmocninu s výberového rozptylu Skutočnosť, že pri bodových odhadoch dochádza k výberovým chybám, veľkosť ktorých nie je možné presne určiť, vedie k tomu, že sa bodové odhady dopĺňajú o intervalové odhady
Intervalové odhady Intervalovým odhadom parametra G základného súboru sa nazýva taký odhad, kedy sa odhadovaný parameter nachádza s pravdepodobnosťou v intervale , tj.: Interval sa nazýva interval spoľahlivosti. Hranice g1 a g2 sú funkcie výberovej charakteristiky un . Ak sú hranice intervalu spoľahlivosti konečné čísla definujeme pravdepodobnosť tj. pravdepodobnosť, že parameter základného súboru G je menší ako g1 sa rovná a pravdepodobnosť, že prekročí hodnotu g2 sa rovná . Súčet pravdepodobností označuje pravdepodobnosť, že parameter základného súboru G nie je z intervalu spoľahlivosti a nazýva sa riziko odhadu ( riziko podhodnotenia, riziko nadhodnotenia)
Riziko odhadu a interval spoľahlivosti 1- 2 1 g2 g1
Pravdepodobnosť sa nazýva koeficient spoľahlivosti alebo jednoducho spoľahlivosť odhadu, a je hladina významnosti. Za predpokladu, že koeficient spoľahlivosti je číslo blízke jednej, možno s určitosťou tvrdiť, že parameter základného súboru je z intervalu spoľahlivosti. Zvyšovaním spoľahlivosti sa však súčasne interval spoľahlivosti rozširuje, čím sa znižuje presnosť odhadu - a naopak, so znižovaním spoľahlivosti sa interval spoľahlivosti zužuje, čím sa zvyšuje presnosť odhadu. Bodový odhad potom môžeme považovať za extrémny prípad intervalového odhadu s nulovou šírkou intervalu ( odhad je síce presný ale stráca na spoľahlivosti ). Pri praktických výpočtoch najčastejšie zostavujeme intervaly spoľahlivosti obojstranné, ak je parameter základného súboru ohraničený zdola aj zhora, kedy aj sú rôzne od nuly. O symetrickom intervale hovoríme vtedy ak riziko nadhodnotenia aj podhodnotenia je rovnaké (v ďalšom texte sa budeme zaoberať len symetrickými intervalmi),
Intervalový odhad strednej hodnoty je kvantil normovaného normálneho rozdelenia / normsinv (1-α/2)
Intervalový odhad je možné zapísať v tvare prípustná chyba odhadu predstavujúca polovicu šírky symetrického intervalu spoľahlivosti a je daná výrazom: b.) ak nepoznáme rozptyl základného súboru a n >30 má veličina u tvar
c.) ak nepoznáme rozptyl základného súboru a n je menší ako 30 má veličina tvar alebo Kvantil studentovho rozdelenia / tinv(α,n – 1)
Od čoho závisí veľkosť prípustnej chyby ?? • 1. od zvolenej spoľahlivosti odhadu (1- ) • 2. strednej - štandardnej chyby priemeru, ktorá je ovplyvnená: - variabilitou znaku – nevieme ju ovplyvniť - veľkosťou výberového súboru, ktorý ovplyvniť môžme! Potrebný rozsah súboru pri vopred zvolenej spoľahlivostia požadovanej presnosti môžme určiť nasledovne:
Intervalový odhad rozptylu a štandardnej odchýlky Pri konštrukcii intervalu spoľahlivosti z veličiny: je dolný kvantil / chiinv(α/2, n – 1) je horný kvantil /chiinv(1-α/2, n – 1) rozdelenia z (n-1) stupňami voľnosti