Scheduling
E N D
Presentation Transcript
Main Points • Scheduling policy: what to do next, when there are multiple threads ready to run • Or multiple packets to send, or web requests to serve, or … • Definitions • response time, throughput, predictability • Uniprocessor policies • FIFO, round robin, optimal • multilevel feedback as approximation of optimal • Multiprocessor policies • Affinity scheduling, gang scheduling • Queueing theory • Can you predict a system’s response time?
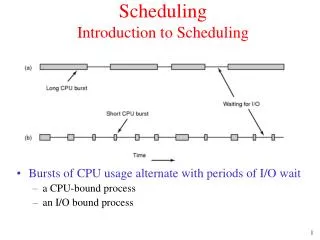
Diagram of Process State P1 P2 Maximum CPU utilization obtained with multiprogramming
Dispatcher • Dispatcher module gives control of the CPU to the process selected by the short-term scheduler; this involves: • switching context • switching to user mode • jumping to the proper location in the user program to restart that program • Dispatch latency – time it takes for the dispatcher to stop one process and start another running
Example • You manage a web site, that suddenly becomes wildly popular. Do you? • Buy more hardware? • Implement a different scheduling policy? • Turn away some users? Which ones? • How much worse will performance get if the web site becomes even more popular?
Definitions • Task/Job • User request: e.g., mouse click, web request, shell command, … • Latency/response time • How long does a task take to complete? • Throughput • How many tasks can be done per unit of time? • Overhead • How much extra work is done by the scheduler? • Fairness • How equal is the performance received by different users? • Predictability • How consistent is the performance over time?
More Definitions • Workload • Set of tasks for system to perform • Preemptive scheduler • If we can take resources away from a running task • Work-conserving • Resource is used whenever there is a task to run • For non-preemptive schedulers, work-conserving is not always better • Scheduling algorithm • takes a workload as input • decides which tasks to do first • Performance metric (throughput, latency) as output • Only preemptive, work-conserving schedulers to be considered
Scheduling Criteria • CPU utilization – keep the CPU as busy as possible • Throughput – # of processes that complete their execution per time unit • Turnaround time –amount of time to execute a particular process • Waiting time –amount of time a process has been waiting in the ready queue • Response time –amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)
Scheduling Criteria • CPU utilization – MAX • Throughput – MAX • Turnaround time – MIN • Waiting time – MIN • Response time – MIN
First In First Out (FIFO) • Schedule tasks in the order they arrive • Continue running them until they complete or give up the processor • Example: memcached • Facebook cache of friend lists, … • On what workloads is FIFO particularly bad?
P1 P2 P3 0 24 27 30 First-Come, First-Served (FCFS) Scheduling Suppose that the processes arrive in the order (at or close to the same time) ProcessBurst Time P1 24 P2 3 P3 3 • Suppose that the processes arrive in the order: P1 , P2 , P3 The Gantt Chart for the schedule is: • Waiting time for P1 = 0; P2 = 24; P3 = 27 • Average waiting time: (0 + 24 + 27)/3 = 17 • Turnaround time for P1 = ?; P2 = ?; P3 = ?
P2 P3 P1 0 3 6 30 FCFS Scheduling (Cont) Suppose that the processes arrive in the order (at or close to the same time) P2 , P3 , P1 • The Gantt chart for the schedule is: • Waiting time for P1 = 6;P2 = 0; P3 = 3 • Average waiting time: (6 + 0 + 3)/3 = 3 • Much better than previous case • Convoy effect short process behind long process
Shortest Job First (SJF) • Always do the task that has the shortest remaining amount of work to do • Often called Shortest Remaining Time First (SRTF) • Suppose we have five tasks arrive one right after each other, but the first one is much longer than the others • Which completes first in FIFO? Next? • Which completes first in SJF? Next?
P3 P2 P4 P1 3 9 16 24 0 Example of SJF Process Arrival TimeBurst Time P1 0.0 6 P2 2.0 8 P3 4.0 7 P4 5.0 3 • SJF scheduling chart • Average waiting time = (3 + 16 + 9 + 0) / 4 = 7
Shortest-Job-First (SJF) Scheduling • Associate with each process the length of its next CPU burst. Use these lengths to schedule the process with the shortest time • SJF is optimal – gives minimum average waiting time for a given set of processes • The difficulty is knowing the length of the next CPU request
Determining Length of Next CPU Burst • Can only estimate the length • Can be done by using the length of previous CPU bursts, using exponential averaging
Examples of Exponential Averaging • =0 • n+1 = n • Recent history does not count • =1 • n+1 = tn • Only the actual last CPU burst counts • If we expand the formula, we get: n+1 = tn+(1 - ) tn-1+ … +(1 - )j tn-j+ … +(1 - )n +1 0 • Since both and (1 - ) are less than or equal to 1, each successive term has less weight than its predecessor
Starvation and Sample Bias • Suppose you want to compare FIFO and SJF on some sequence of arriving tasks • Compute average response time as the average for tasks that start/end in some window • Is this valid or invalid?
Round Robin • Each task gets resource for a fixed period of time (time quantum) • If task doesn’t complete, it goes back in line • Need to pick a time quantum • What if time quantum is too long? • Infinite? • What if time quantum is too short? • One instruction?
Round Robin vs. FIFO • Assuming zero-cost time slice, is Round Robin always better than FIFO?
Round Robin vs. Fairness • Is Round Robin always fair?
Max-Min Fairness • How do we balance a mixture of repeating tasks: • Some I/O bound, need only a little CPU • Some compute bound, can use as much CPU as they are assigned • One approach: maximize the minimum allocation given to a task • Schedule the smallest task first, then split the remaining time using max-min
Priority Scheduling • A priority number (integer) is associated with each process • The CPU is allocated to the process with the highest priority (smallest integer highest priority) • Preemptive • nonpreemptive • SJF is a priority scheduling where priority is the predicted next CPU burst time • Problem Starvation • low priority processes may never execute • Solution Aging • as time progresses increase the priority of the process
Multi-level Feedback Queue (MFQ) • Goals: • Responsiveness • Low overhead • Starvation freedom • Some tasks are high/low priority • Fairness (among equal priority tasks) • Not perfect at any of them! • Used in Linux (and probably Windows, MacOS)
MFQ • Set of Round Robin queues • Each queue has a separate priority • High priority queues have short time slices • Low priority queues have long time slices • Scheduler picks first thread in highest priority queue • Tasks start in highest priority queue • If time slice expires, task drops one level
Uniprocessor Summary • FIFO is simple and minimizes overhead. • If tasks are variable in size, then FIFO can have very poor average response time. • If tasks are equal in size, FIFO is optimal in terms of average response time. • Considering only the processor, SJF is optimal in terms of average response time. • SJF is pessimal in terms of variance in response time.
Uniprocessor Summary • If tasks are variable in size, Round Robin approximates SJF. • If tasks are equal in size, Round Robin will have very poor average response time. • Tasks that intermix processor and I/O benefit from SJF and can do poorly under Round Robin. • Max-min fairness can improve response time for I/O-bound tasks. • Round Robin and Max-min fairness both avoid starvation. • By manipulating the assignment of tasks to priority queues, an MFQ scheduler can achieve a balance between responsiveness, low overhead, and fairness.
Scheduling Applicationson Multiprocessors • Make effective use of multiple cores for running sequential tasks • Adapt scheduling algorithms for parallel applications
Scheduling Sequential Applicationson Multiprocessors • Use a centralized MFQ • Centralized lock on I/O can be a bottleneck • Cache effects of a single ready list: • Cache coherence overhead • MFQ data structure would ping between caches • Fetching data from other caches can be even slower than re-fetching from DRAM • Cache reuse • Thread’s data from last time it ran is often still in its old cache • MFQ for each processor • Once a thread is scheduled on a processor, it is returned to the same processor • Balancing workload must be managed
Scheduling Parallel Applications on Multiprocessors • Might be a natural decomposition of parallel application onto a set of processors • Ex. Image • Competition between processes for processor resources. • Techniques • Oblivious scheduling • Gang Scheduling
Oblivious Scheduling Parallel Programs Each thread is scheduled as a completely independent entity Each processor time-slices its ready list independently of the other processors
Oblivious Scheduling Design Patterns • Bulk synchronous Parallelism • Split work into roughly equal sized chunks • At each step, computation is limited by slowest processor • Producer-Consumer Parallelism • The results of one thread is fed to the next thread. • Preempting a thread can stall all processes in the chain
Oblivious Scheduling Problems • Considerations • Critical Path Delay • Locks • Parallel I/O • In each of these the scheduler may not know the application decomposition to best split the work across processors.
Gang Scheduling Parallel Programs • Schedule all the tasks of a program together • Application picks some decomposition of work into some number of threads and those threads run together or not at all.
Space Sharing Scheduler activations: kernel informs user-level library as to # of processors assigned to that application, with upcalls every time the assignment changes
Energy-Aware Scheduling • Consideration of scheduling on battery life • Scheduling optimization • Processor high/low power modes. OS can decide which is appropriate • Disable one or more chips to conserve • Power off I/O devices
Real-Time Scheduling • Real-time constraints: Computation that must be completed by a deadline • Widely used techniques • Over provisioning • Earliest Deadline first • Priority donation
Real-Time Scheduling • Over Provisioning • Ensure that all real-time tasks, in aggregate, use only a fraction of the system’s processing power. • Earliest Deadline First (EDF) • Sorts processes by deadline • Priority Donation • When a high priority waits for a lower one, (with equal real-time deadlines) it donates priority to make sure the lower one can finish.
Algorithmic Evaluation • What is the best case scenario for minimizing processing delay? • Keeping arrival rate, service time constant • Methods • Deterministic Modeling • Queueing Models
Queueing Theory • Can we predict what will happen to user performance: • If a service becomes more popular? • If we buy more hardware? • If we change the implementation to provide more features?