Trace Scheduling, Superblock Scheduling, and Hyperblock Scheduling
Trace Scheduling, Superblock Scheduling, and Hyperblock Scheduling. 임경환. Introduction. VLIW and superscalar processors need sufficient ILP to effectively utilize the parallel hardware. ILP within basic blocks is limited for control-intensive programs.


Trace Scheduling, Superblock Scheduling, and Hyperblock Scheduling
E N D
Presentation Transcript
Trace Scheduling, Superblock Scheduling, and Hyperblock Scheduling 임경환
Introduction • VLIW and superscalar processors need sufficient ILP to effectively utilize the parallel hardware. • ILP within basic blocks is limited for control-intensive programs. • Optimizations across basic block are needed • Trace Scheduling • Superblock Scheduling • Hyperblock Scheduling
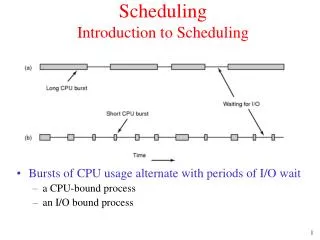
Trace Scheduling • Basic Idea • Increase ILP along the important execution path by removing constraints due to the unimportant path. Code motion to increase ILP Compensation Code R1 = R2+R3 0.1 0.9 R1 = R2+R3 R1 = R2+R3
Trace Scheduling • Trace • Sequence of instructions • Including branches • Not including loops. • B1,B3,B4,B5,B7 is the most frequently executed path • Three traces in this path • B1,B3 • B4 • B5,B7 B1 B2 B3 B4 B5 B6 B7
Trace Scheduling B1 Add compensation code, if needed B1 Each trace is scheduled independently B2 B3 B3 B2 B4 B4 B5 B5 B6 B7 B6 B7
Trace Scheduling • Compensation code • Case 1: Moving an instruction below a side exit (simple) Instr 1 Instr 2 Instr 2 Instr 3 Instr 3 Instr 4 Instr 1 Instr 4 Instr 1 Instr 5 Instr 5
Trace Scheduling • Compensation code • Case 2: Moving an instruction above a side exit (speculative execution) Instr 1 Instr 1 Instr 2 Instr 5 Instr 3 Instr 2 Instr 4 Instr 3 Instr 5 Instr 4
Trace Scheduling • Compensation code • Case 3,4 is related with side entrance • Relatively more complex Instr 3 Instr 1 Instr 2 Instr 4 Instr 2 Instr 3 Instr 3 Instr 4 Instr 4 Instr 1 Instr 5 Instr 5
Superblock Scheduling • Superblock removes problems associated with side entrances • Superblock • A trace which has no side entrances. • Control may only enter from the top but may leave at one or more exit points.
Superblock Scheduling • Forming the superblock • Traces are identified using execution profile information. • Using tail duplication to eliminate side entrances • Tail duplication • A copy is made of the tail portion of the trace from the first side entrance to the end. • All side entrances are moved to the corresponding duplicate basic blocks.
C’ D’ Superblock Scheduling • Example of tail duplication. A B trace superblock C D
Superblock Scheduling • Superblock ILP optimization • Superblock enlarging optimizations • Superblock dependence removing optimizations • Superblock Scheduling • Speculative execution support
Superblock Scheduling • Enlarging the superblock • Loop peeling • Modifies a superblock loop which tends to iterate only a few times • Loop unrolling • Can apply on the superblock loop which tends to iterate many times
Superblock Scheduling • Loop peeling • The loop body is replaced by straight-line code consisting of the first several iterations. • The original loop body is moved to the end of the function to compute additional iterations.
Superblock Scheduling • Example of loop peeling 90% of this loop iterates only 3 time for(i=0; i<n; i++) . . . 3 iterations of original loop for(i=0; i<n; i++) . .
Superblock Scheduling • Superblock dependence removing • Register renaming • Operation migration • Moves an instruction from a superblock where its result is not used to a less frequently executed superblock • Induction variable expansion • Accumulator variable expansion
Example of dependence removing loop: r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 loop: r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 if (r4 < 400) goto loop iter1 unroll 2 times r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 iter2 if (r4 < 400) goto loop
loop: loop: r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 Register renaming iter1 iter1 r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 r11 = load(r2) r13 = load(r4) r15 = r11 * r13 r6 = r6 + r15 r2 = r2 + 4 r4 = r4 + 4 iter2 iter2 if (r4 < 400) goto loop if (r4 < 400) goto loop Superblock Scheduling
r16 = 0 loop: loop: r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 Accumulator variable expansion iter1 iter1 r11 = load(r2) r13 = load(r4) r15 = r11 * r13 r6 = r6 + r15 r2 = r2 + 4 r4 = r4 + 4 r11 = load(r2) r13 = load(r4) r15 = r11 * r13 r16 = r16 + r15 r2 = r2 + 4 r4 = r4 + 4 iter2 iter2 if (r4 < 400) goto loop if (r4 < 400) goto loop Superblock Scheduling r6 = r6 + r16
r16 = 0 r16 = 0 loop: loop: r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 8 r4 = r4 + 8 r1 = load(r2) r3 = load(r4) r5 = r1 * r3 r6 = r6 + r5 r2 = r2 + 4 r4 = r4 + 4 Induction variable expansion iter1 iter1 r11 = load(r12) r13 = load(r14) r15 = r11 * r13 r16 = r16 + r15 r12 = r12 + 8 r14 = r14 + 8 r11 = load(r2) r13 = load(r4) r15 = r11 * r13 r16 = r16 + r15 r2 = r2 + 4 r4 = r4 + 4 iter2 iter2 if (r4 < 400) goto loop if (r4 < 400) goto loop Superblock Scheduling r12 = r2+4 r14 = r4+4 r6 = r6 + r16
Superblock Scheduling • Superblock Scheduling • Construct dependence graph • List scheduling • Speculative execution support • Two restrictions • 1. The destination of J is not used before it is redefined when B is taken • 2. J will never cause an exception that may terminate program execution when branch B is taken • Restriction 2 is more important • Restricted percolation model • General percolation model
Hyperblock Scheduling • When execution paths have similar frequency • Superblock scheduling couldn’t deal this problem effectively • Hyperblock scheduling • Combine basic blocks from multiple paths of control (using if-conversion) • For programs without heavily biased branches, hyperblocks provide a more flexible framework
Hyperblock Scheduling • Predicated execution • Efficient method to handle conditional branches • When the predicate has value T, the instruction is executed normally • When the predicate has value F, the instruction is treated as a no_op • Using predicated execution, we can eliminate conditional branch • If-conversion
if (A[j]<= 50) j = j+2; Else j = j+1; ld r3,addr(A) ld r4,mem(r3+r2) pred_gt p1,r4,50 add r2,r2,2 if P1_F add r2,r2,1 if P1_T ld r3,addr(A) ld r4,mem(r3+r2) bgt r4,50,L1 add r2,r2,2 L1: add r2,r2,1 Hyperblock Scheduling • Example of if-then-else predication (in the IMPACT model)
Hyperblock Scheduling • Hyperblock • Set of predicated basic blocks in which control may only enter from the top, but may exit from one or more locations. • Very similar with superblock • Making hyperblock • Hyperblock block selection • Hyperblock formation
Hyperblock Scheduling • Hyperblock block selection • Decide which basic blocks in a region to include in the hyperblock • Three feature of each block are examined • Execution frequency • Block size • Instruction characteristics • Using heuristic function
Hyperblock Scheduling • Hyperblock Formation • Tail duplication • Loop peeling • Node splitting • Eliminate dependences created by control path merges • Duplicates all blocks subsequent to the merge point for each path • If-conversion
Hyperblock Scheduling • Control flow information • Instructions within a hyperblock are not sequential. • Require more complex analysis • Predicate hierarchy graph (PHG) • Determine if two instructions can ever executed in a single path • If they can, then there is a control flow path between these two instructions
Hyperblock Scheduling • Example of PHG 0 Same path: AND P4 = c1·c2 pred_clear p4 pred_ne p3,r2,0 pred_eq p5,r2,0 pred_ne p4,r0,0 if p3_T pred_eq p5,r0,0 if p3_T mov r2,r0, if p4_T sub r2,r2,r0 if p5_T add r1,r1,1 cond c1 = (r2 != 0) ~c1 = (r2 == 0) p3 Meet multiple path:OR P5 = ~c1+c1·~c2 cond c2 = (r2 != 0) ~c2 = (r2 == 0) ANDing p4 and p5 p4·p5 = (c1·c2) ·(~c1+c1 ·~c2) = 0 There is no control path between p4, p5 p4 p5
Hyperblock Scheduling • Hyperblock-Specific Optimizations • Instruction promotion • Removes the dependence between the predicated instruction and the instruction which sets the corresponding predicate value • Instructions Merging • Combine two instructions in a hyperblock with complementary predicates into a single instruction
Conclusion • Trace Scheduling can increase ILP • But, side entrance is too complex to handle • Superblock Scheduling removes the side entrance of the trace • It mainly focuses on the heavily biased branches. • Hyperblock Scheduling • For programs without heavily biased branches, hyperblocks can provide a more flexible framework