Download

1 / 34
360 likes | 857 Views
MOLEKÜLER VERİLERİN FORMATLANMASI (NEXUS,MEGA,FASTA). Biyoinformatik , biyolojik bilgilerin yaratılması ve saklanması için veritabanlarının oluşturulmasıdır . Bu konudaki çalışmaların çoğu biyolojik verilerin analizi ile ilgilidir.

E N D
Biyoinformatik, biyolojik bilgilerin yaratılması ve saklanması için veritabanlarının oluşturulmasıdır. • Bu konudaki çalışmaların çoğu biyolojik verilerin analizi ile ilgilidir. • Artan sayıdaki projelerde biyolojik bilgilerin organizasyonu gerekmektedir. • Bu alanda oluşturulan veritabanlarının büyük bir kısmını nükleik asitler oluşturmaktadır
Milyonlarca nükleotidin depolanması ve organizasyonu için veritabanlarının oluşturulması, araştırıcıların bu bilgilere ulaşabilmeleri ve yeni veriler girebilmeleri için ilk aşamadır. • Biyoinformatik'te nükleotid dizi bilgilerinin organizasyonu ve depolanması görevini üstlenmiş üç kuruluş vardır: • Genbankası(GenBank), • Avrupa Moleküler Biyoloji Laboratuvarı (EMBL) • DNA Japonya veritabanıdır (DDBJ)
Dizi bilgileri veritabanlarında iki formda bulunur; • Bunlardan birincisi; yazarlar/diziyi veritabanına ilk işleyenler, kaynak gösterimleri, biyolojik atıflar ve dizinin kendisiyle; intronlar, eksonlar, başlangıç ve bitiş kodonlarıvb bilgiyi içeren bir tablodan oluşan tam bilgi • İkincisi ise; hızlı benzerlik araştırmaları için kullanılan ve sadece diziyi içeren FASTA formatıdır. Accession (ulaşma) numaraları, herbir diziyi belirleyen özgün kimliklerdir ve dizi veritabanına ilk kez girildiğinde verilir.
BİYOİNFORMATİKTEKULLANILAN ÖNEMLİ TERİMLER Accessionnumber (GenBank): Bir dizi GenBank’a kaydedildiği zaman bu kayıt için verilen yada kayda özel kimlik numarasıdır. Bir büyük harf ve ardından gelen 5 rakam veya 2 büyük harf ve 6 rakamdan oluşur. Accessionnumber (RefSeq): Bütün bir RefSeq dizisine atanmış kimlik numarasıdır. Sırasıyla iki büyük harf, bir alt çizgi (_) ve 6 rakamdan oluşur (NT_123456). * NT_123456 birleştirilmiş kontigler * NM_123456 mRNA’lar (mRNA’dan oluşturulmuş cDNA’lar) * NP_123456 proteinler * NC_123456 kromozomlar
BLAST: (Basic LocalAlignmentSearchTool): Aynı yada farklı organizmalar arasında nukleotid yada protein dizisi karşılaştırılması ve benzer bölgelerin araştırılması için kullanılan yüksek hızda bir bilgisayar programı. • CDS: Bir nukleotid dizisinin kodonları oluşturan bölgesi yada kodlayan dizi. • ConservedSequence: Bir DNA molekülünde (bir proteindeki Aa dizisinde) evrim süresince değişmeden kalmış olan baz dizisi.
Contig: Bir kromozomun üst üste çakışma gösteren, klonlanmış farklı DNA parçaları grubu. • Domain: Bir proteinin bağımsız olarak katlanabildiği ve çalışılabildiği kabul edilen parçası. • EST (ExpressedSequenceTag): Bir Cdna molekülünün, bir genin kimliği olarak kullanılabilecek kısa bir parçası. Genlerin konumlanmasından ve haritalanmasında kullanılır. • Motif: Protein dizisi içinde kısa, korunmuş bir bölge. Motifler genellikle domainlerin yüksek derecede korunmuş bölgeleridir.
DİZİ FORMATLARI • 1. GenBank DNA Dizi Formatı • 2. Avrupa Moleküler Biyoloji Laboratuvarı (EMBL ) Veri Kütüphanesi Formatı • 3. FASTA Sekans Formatı • 4. National Biomedical Research Foundation / Protein Information Resource SekansFormatı • 5. Stanford Üniversitesi / Intelligenetics Sekans Formatı • 6. Genetik Bilgisayar Grubu ( GCG ) Sekans Formatı • 7. National Biomedical Research Vakfı / Protein Information Resource’dan Elde edilen Sekans Dosyasının Formatı • 8. Genetik Veri Çevresi ( GDE ) Sekans Formatı
Gen Bank DNA Dizi Formatı: Girilen her dizinin tanımlayıcı bilgileri verilir. Bu bilgiler her satırda ilk bilgi olarak, her biri bir belirleyici ile birlikte gruplara ayrılmış şekilde yazılır. • Örneğin; referans için RF gibi, • LOCUS lokusun ismi • DEFINITION girişin tanımı • ACCESSION orijinal kaynağın accession numarası • KEYWORDS bu girişin karşı referanslarının yapılabilmesi için anahtar kelimeler • SOURCE DNA’nın elde edildiği organizma
Avrupa Moleküler Biyoloji Laboratuvarı Veri Kütüphanesi Formatı (EMBL) • ID veritabanındaki dizi için kimlik numarası • AC dizinin başlangıcını gösteren accessionnumber • DT girişin ve modifikasyonların tarihi • KW anahtar kelimeler • OS, OC kaynak organizma
FASTA >AJ867261_Ovis_orientalis CTGGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTATTATTCACGCCTGACTTA CTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTAACACTCCCCCTCACATCAAA CCTGAATGATACTTCCTATTTGCATACGCAATCTTACGATCAATCCCTAATAAACTAGGA GGAGTCCTCGCCCTAATCCTCTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACA TCAAAGCAACGGAGCATAATATTCCGACCAATCAGTCAATGTGTATTCTGAATCCTAGTA GCCGACCTATTAACACTCACATGAATTGGAGGCCA >DQ097429|OA_MOR12_C CTAGGTGCCATCCTACTGATCCTCATCCTCATGCTACTAGTACTATTTACGCCTGACCTA CTCGGAGACCCAGACAACTACACCCCAGCAAATCCACTTAACACTCCCCCTCACATCAAA CCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGA GGAGTCCTCGCCCTAATCCTCTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACA TCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA GCTGACCTATTAACACTCACATGAATTGGAGGCCA >DQ097430_OA_KAR15_C* CTAGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTACTATTCACGCCTGACTTA CTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTAACACTCCCCCTCACATCAAA CCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGA GGAGTCCTCGCCCTAATCCTCTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACA TCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA GCCGACCTATTAACACTCACATGAATTGGAGGCCA
MEGA #Mega Title: Cytb_Konya sheep.txt #AJ867261_Ovis_orientalis CTGGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTATTATTCACGCCTGACTTA CTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTAACACTCCCCCTCACATCAAA CCTGAATGATACTTCCTATTTGCATACGCAATCTTACGATCAATCCCTAATAAACTAGGA GGAGTCCTCGCCCTAATCCTCTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACA TCAAAGCAACGGAGCATAATATTCCGACCAATCAGTCAATGTGTATTCTGAATCCTAGTA GCCGACCTATTAACACTCACATGAATTGGAGGCCA #DQ097429|OA_MOR12_C CTAGGTGCCATCCTACTGATCCTCATCCTCATGCTACTAGTACTATTTACGCCTGACCTA CTCGGAGACCCAGACAACTACACCCCAGCAAATCCACTTAACACTCCCCCTCACATCAAA CCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGA GGAGTCCTCGCCCTAATCCTCTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACA TCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA GCTGACCTATTAACACTCACATGAATTGGAGGCCA #DQ097430_OA_KAR15_C* CTAGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTACTATTCACGCCTGACTTA CTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTAACACTCCCCCTCACATCAAA CCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGA GGAGTCCTCGCCCTAATCCTCTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACA TCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA GCCGACCTATTAACACTCACATGAATTGGAGGCCA
NEXUS (1) #NEXUS [TITLE: Cytb_Konya sheep.txt] begin data; dimensionsntax=3 nchar=335; format datatype=DNA missing=N gap=-; matrix AJ867261_Ovis_orientalis CTGGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTATTATTCACGCCTGACTTACTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTA ACACTCCCCCTCACATCAAACCTGAATGATACTTCCTATTTGCATACGCAATCTTACGATCAATCCCTAATAAACTAGGAGGAGTCCTCGCCCTAATCCT CTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACATCAAAGCAACGGAGCATAATATTCCGACCAATCAGTCAATGTGTATTCTGAATCCTAGTA GCCGACCTATTAACACTCACATGAATTGGAGGCCA DQ097429|OA_MOR12_C CTAGGTGCCATCCTACTGATCCTCATCCTCATGCTACTAGTACTATTTACGCCTGACCTACTCGGAGACCCAGACAACTACACCCCAGCAAATCCACTTA ACACTCCCCCTCACATCAAACCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGAGGAGTCCTCGCCCTAATCCT CTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACATCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA GCTGACCTATTAACACTCACATGAATTGGAGGCCA DQ097430_OA_KAR15_C* CTAGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTACTATTCACGCCTGACTTACTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTA ACACTCCCCCTCACATCAAACCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGAGGAGTCCTCGCCCTAATCCT CTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACATCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA GCCGACCTATTAACACTCACATGAATTGGAGGCCA ; endblock; beginassumptions; optionsdeftype=unord; endblock;
NEXUS (2) #NEXUS [TITLE: Cytb_Konya sheep.txt] begin data; dimensionsntax=3 nchar=335; format interleavedatatype=DNA missing=N gap=-; matrix AJ867261 Ovisorientalis CTGGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTATTATTCACGCCTGACTTACTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTA DQ097429|OA_MOR12_C CTAGGTGCCATCCTACTGATCCTCATCCTCATGCTACTAGTACTATTTACGCCTGACCTACTCGGAGACCCAGACAACTACACCCCAGCAAATCCACTTA DQ097430_OA_KAR15_C* CTAGGTGCCATCCTACTAATCCTCATCCTCATGCTACTAGTACTATTCACGCCTGACTTACTCGGAGACCCAGACAACTACACCCCAGCAAACCCACTTA AJ867261_Ovis_orientalis ACACTCCCCCTCACATCAAACCTGAATGATACTTCCTATTTGCATACGCAATCTTACGATCAATCCCTAATAAACTAGGAGGAGTCCTCGCCCTAATCCT DQ097429|OA_MOR12_C ACACTCCCCCTCACATCAAACCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGAGGAGTCCTCGCCCTAATCCT DQ097430_OA_KAR15_C* ACACTCCCCCTCACATCAAACCTGAGTGATACTTCCTATTTGCGTACGCAATCTTACGATCAATCCCTAATAAACTAGGAGGAGTCCTCGCCCTAATCCT AJ867261_Ovis_orientalis CTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACATCAAAGCAACGGAGCATAATATTCCGACCAATCAGTCAATGTGTATTCTGAATCCTAGTA DQ097429|OA_MOR12_C CTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACATCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA DQ097430_OA_KAR15_C* CTCAATCCTAGTCCTAGTAATTATACCCCTCCTCCATACATCAAAGCAACGAAGCATAATATTCCGACCAATCAGTCAATGTATATTCTGAATCCTAGTA AJ867261_Ovis_orientalis GCCGACCTATTAACACTCACATGAATTGGAGGCCA DQ097429|OA_MOR12_C GCTGACCTATTAACACTCACATGAATTGGAGGCCA DQ097430_OA_KAR15_C* GCCGACCTATTAACACTCACATGAATTGGAGGCCA ; endblock; beginassumptions; optionsdeftype=unord; endblock
Roehl 31445911223 8388324580 64233 DNA FORMATI H_1 GATCTCAAGGC 1 H_2 AGCTCTGGAAT 1 H_3 AACCTCGGAAC 1 MORFOLOJİ/AFLP/RFLP/RAPD/ISSR/SSR FORMATI 1010101010101010101010
BİR DİZİ FORMATINI DİĞERİNEDÖNÜŞTÜRMEK • Dizi hizalamaları çeşitli metin-tabanlı dosya formatlarında saklanabilir, bunların çoğu ilk olarak belli bir hizalama programı veya uygulaması ile birlikte geliştirilmiştir. • Çoğu Web-temelli araçlar sınırlı sayıda girdi ve çıktı format seçeneği verirler. Örneğin FASTA formatı ve GenBank formatı gibi ve program çıktısı genelde kolayca değiştirilemez. • Çeşitli format dönüştürme programları mevcuttur, bunlardan READSEQve EMBOSSgibi bazılarının grafik arayüzü veya komut satır arayüzüvardır. • Buna karşın BioPerl, BioRubygibi program paketlerinin buna olanak veren kendi fonksiyonları vardır
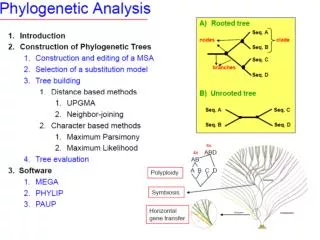
Yaygın Olarak Kullanılan Bilgisayar Programları: • Programlar hakkında genel bilgiye geçmeden evvel bir konunun altını çizmekte fayda vardır. • Genellikle filogenetik alanında çalışan akademisyenler ile bu alanda program geliştirenler ezici çoğunluk ile MAC kullanmaktadırlar. • Her ne kadar programların PC versiyonları mevcut ise de MAC versiyonları her zaman daha ileri ve üst sürümdürler. • Filogenetik ağaçların eldesinde en yaygın kullanılan sadece 3 program hakkında bilgi vereceğiz. • Ne var ki bu programların önerdikleri ağaçları bilgisayarınızda görüntülemenizi sağlayan baska bir program daha vardır. Bu da Treeview programıdır.
1. PAUP (Phylogenetic Analysis Using Parsimony): Florida Eyelet Üniversitesi’nden bir Akademisyen tarafından geliştirilen programın en son 4.0 beta versiyonu piyasaya sürlümüştür. Program ücretsiz değildir. Online olarak ulaşılabilecek oldukça kapsamlı bir elkitabı vardır. • 2. PHYLIP: İnternet üzerinden kullanımı ücretsizdir. Parsimony, farklılık matrisleri , maximumlikelihood, ve bir çok farklı metodla ağaç eldesine olanak tanımakla klamayıp aynı zamanda değişik bir çok veri tipini kullanabilmektedir(DNA, RNA, Protein, restriksüyon bölgeleri, gen frekansları vs.) . • 3. MrBayes: Adından da anlaşılacağı üzere Bayes istatistiği kullanılarak filogenetik ağaç elde etmede kullanılan bilgisayar programıdır. Bu program ücretsiz olarak internetten indirilip kullanılabilmektedir.
PAUP (Phylogenetic Analysis Using Parsimony) • Paup bir bilgisayar programı olup parsimoni kriteri altında filogenetik hipotez oluşturmakta kullanılır. Parsimoni metodu bir veri matrisinden çıkarılması muhtemel ağaçları değerlendirerek, minimum uzunluktaki ağaçları bulmaya yarayan bir algoritma ile çalışır. • Belli karakter tiplerini kullanarak ağaç oluşturmaya yarayan çeşitli algoritmalar geliştirilmiştir. PAUP programı, bütün bu algoritmaları kapsayan genel bir algoritma ile çalışır. Kullanıcı istediği herhangi bir karakter tipini ya da tiplerini harmanlayarak aynı anda analiz etme seçeneğine sahiptir.
Paup programı kullanılarak elde edilmiş bir filogenetik ağacın Treeview programındaki görüntüsü
NEXUS • Numbernexus • Takson bloğu • Karakter bloğu takson etiketleri vardır. • Nexus bir format çeşididir. • Nexus’ un formatının özelliği noktalı virgülleri herbirini gösterir ve ikinoktalı virgül arasında END yazısı yazılmışsa o bloğun bittiğini gösterir. • Nexus formatı kulanılaraakPaup programında filogenetik analiz yapılır ve filogenetik ağaçlar elde edilir. MATRİX • Veri matriksininbittiğinidenoktalı virgül sonuna END yazılır.
Kaynaklar • www.phlogeny.fr/version2_cgi/data_converter.cgi • http://www.ncbi.nlm.nih.gov/ • DNA dizilerinin analiz icinnexusformatinacevrimi YARDIMLARINDAN DOLAYI FATİH ÇOŞKUN HOCAMA TEŞEKKÜR EDERİM…
Beni dinlediğiniz için teşekkür ederim Hazırlayan :AYŞEGÜL ÇAMDERELİ 200920102070 2.ÖĞRETİM B-GRUBU