Download

1 / 21
210 likes | 231 Views
This article discusses stochastic planning using decision diagrams, specifically focusing on Markov decision processes (MDP) and their application in value iteration. It also explores the use of boolean decision diagrams (BDDs) and approximate value iteration. The article concludes with experiments and future research directions.

E N D
Stochastic Planning using Decision Diagrams Sumit Sanghai
Stochastic Planning • MDP model ? • Finite set of states S • Set of actions A, each having a transition probability matrix • Fully observable • A reward function R associated with each state
Stochastic Planning … • Goal ? • Policy which maximizes the expected total discounted reward in an infinite horizon model • Policy is a mapping from state to action • Problem ? • Total reward can be infinite • Solution ? • Associate a discount factor b
Expected Reward Model • Expected Reward Model • Vp(s) = R(s) + båt Pr(s,p(s),t) Vp(t) • Optimality ? • Policy p is optimal if Vp>= Vp` for all s and p` • Thm : There exists an optimal policy • Its value function is denoted as V*
Value Iteration • Vn+1(s) = R(s) + maxab åt Pr(s,a,t) Vn(t) V0(s) = R(s) • Stopping condition : • if maxs {Vn+1(s) – Vn(s)} < e(1-b) / 2b then Vn+1 is e/2 close to V* • Thm : Value Iteration gives optimal policy • Problem ? • Can be slow if state space too large
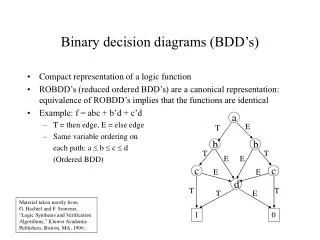
Boolean Decision Diagrams • Graph Representation of Boolean Functions • BDD = Decision Tree – redundancies • Remove duplicate nodes • Remove any node with both child pointers pointing to the same child
x1 x1 x2 x2 x2 x2 x3 x3 x3 x3 x3 x3 x3 0 1 1 0 0 1 0 1 BDDs… x x x f 1 2 3 0 0 0 1 0 0 1 0 0 1 0 0 0 1 1 1 1 0 0 0 1 0 1 1 1 1 0 1 1 1 1 0
1 2 1 or = 2 2 1 0 1 0 1 1 1 0 BDDs operations
Linear Growth Exponential Growth Variable ordering (a1 ^ b1) v (a2 ^ b2) v (a3 ^ b3)
BDD no magic • Number of boolean functions • 2^{2^n} • With polynomial nodes • Exponential functions
ADDs • BDDs + real valued domain • Useful to represent probabilities
MDP, State Space and ADDs • Factored MDP • S characterized by {X1, X2, …, Xn} • Action a from s to s` a from {X1, X2, …, Xn} to {X1`, X2`,…,Xn`} • Pr(s,a,s`) ? • Pra(Xi`|X1, X2,…,Xn) • Each can be represented using ADD
Value Iteration Using ADDs • Vn+1(s) = R(s) + b maxa {åt P(s,a,t) Vn(t)} • R(s) : ADD • P(s,a,t)=Pa(X1`=x1`,…,Xn`=xn`|X1=x1,…,Xn=xn) = ÕiP(Xi`=xi`|X1=x1,…,Xn=xn) Vn+1(X1,…,Xn) = R(X1,…Xn) + b maxa {åX1`,…,Xn`Õi Pa(Xi`|X1,…,Xn) Vn(X1`,…,Xn`)} • 2nd term on RHS can be obtained by quantifying X1` first as true or false and multiplying its associated ADD with Vn and summing over all possibilities to eliminate X1` åX1`,…,Xn` {Õi=2 to n {Pa(Xi`|X1,…,Xn)} (Pa(X1`=true|X1,…, Xn) Vn(X1`=true,…,Xn`) + Pa(X1`=false|X1,…, X_n) Vn(X1`=false,…,Xn`) )}
Value Iteration Using ADDs(other possibilities) • Which variables are necessary ? • variables appearing in the value function • Order of variables during elimination ? • Inverse order • Problem ? • Repeated computation of Pr(s,a,t) • Solution ? • Precompute Pa(X1`,…,Xn`|X1,…,Xn) • Mutliply the dual action diagrams
Value Iteration… • Space vs Time ? • Precomputation : huge space required • No precomputation : time wasted • Solution (do something intermediate) • Divide variables into sets (restriction ??) and precompute for them • Problems with precomputation • Precomputation for sets containing variables which do not appear in value function • Dynamic precomputation
Experiments • Goals ? • SPUDD vs Normal value iteration • What is SPI ? • How is comparison done ? • Worst case of SPUDD • Missing links ? • SPUDD vs Others • Space vs Time experiments
Future Work • Variable reordering • Policy iteration • Approximate ADDs • Formal model for structure exploitation • BDDs eg. Symmetry detection • First order ADDs
x1 x1 x2 x2 x2 x2 x3 x3 x3 x3 x3 0.9 1.1 0.1 6.7 [0.9,1.1] 0.1 6.7 Approximate ADDs
Approximate ADDs • At each leaf node ? • Range : [min,max] • What value and error do you associate with that leaf ? • How and till when to merge the leaves ? • max_size vs max_error • Max_size mode • Merge closest pairs of leaves till size < max_size • Max_error mode • Merge pairs such that error < max_error
Approximate Value Iteration • Vn+1 from Vn ? • At each leaf node do calculation for both min and max : eg [min1,max1]*[min2,max2] = [min1*min2, max1*max2] • What about maxa step ? • Reduce again • When to stop ? • When the ranges for every state in 2 consecutive value functions overlap or lie within some tolerance (e) • How to get policy ? • Find actions which maximize value functions (when range is replaced by midpoints) • Convergence ?
Variable reordering • Intuitive ordering • Variables which are correlated should be placed together • Random • Pick pairs of variables and swap them • Rudell’s sifting • Pick a variable, find a better position • Experiments : Sifting did very well