Download

1 / 21
210 likes | 1.74k Views
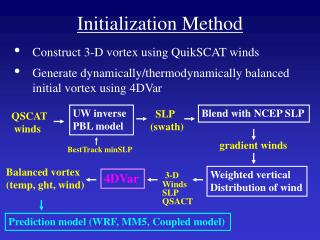
Multiprocessor Initialization. An introduction to the use of Interprocessor Interrupts. Multiprocessor topology. Back Side Bus. Local APIC. Local APIC. IO APIC. CPU #0. CPU #1. Front Side Bus. peripheral devices. system memory. bridge. The Local-APIC ID register. 31. 24.

E N D
Multiprocessor Initialization An introduction to the use of Interprocessor Interrupts
Multiprocessor topology Back Side Bus Local APIC Local APIC IO APIC CPU #0 CPU #1 Front Side Bus peripheral devices system memory bridge
The Local-APIC ID register 31 24 0 reserved APIC ID This register is initially zero, but its APIC ID Field (8-bits) is programmed by the BIOS during system startup with a unique processor identification- number which subsequently is used when specifying the processor as a recipient of inter-processor interrupts. Memory-Mapped Register-Address: 0xFEE00020
The Local-APIC EOI register 31 0 write-only register This write-only register is used by Interrupt Service Routines to issue an ‘End-Of-Interrupt’ command to the Local-APIC. Any value written to this register will be interpreted by the Local-APIC as an EOI command. The value stored in this register is initially zero (and it will remain unchanged). Memory-Mapped Register-Address: 0xFEE000B0
The Spurious Interrupt register 31 8 7 0 reserved E N spurious vector Local-APIC is Enabled (1=yes, 0=no) This register is used to Enable/Disable the functioning of the Local-APIC, and when enabled, to specify the interrupt-vector number to be delivered to the processor in case the Local-APIC generates a ‘spurious’ interrupt. (In some processor-models, the vector’s lowest 4-bits are hardwired 1s.) Memory-Mapped Register-Address: 0xFEE000F0
Interrupt Command Register • Each Pentium’s Local-APIC has a 64-bit Interrupt Command Register • It can be programmed by system software to transmit messages (via the Back Side Bus) to one or several other processors • Each processor has a unique identification number in its APIC Local-ID Register that can be used for directing messages to it
ICR (upper 32-bits) 31 24 0 reserved Destination field The Destination Field (8-bits) can be used to specify which processor (or group of processors) will receive the message Memory-Mapped Register-Address: 0xFEE00310
ICR (lower 32-bits) 15 31 19 18 12 10 8 7 0 R / O Vector field Delivery Mode 000 = Fixed 001 = Lowest Priority 010 = SMI 011 = (reserved) 100 = NMI 101 = INIT 110 = Start Up 111 = (reserved) Destination Shorthand 00 = no shorthand 01 = only to self 10 = all including self 11 = all excluding self Trigger Mode 0 = Edge 1 = Level Level 0 = De-assert 1 = Assert Destination Mode 0 = Physical 1 = Logical Delivery Status 0 = Idle 1 = Pending Memory-Mapped Register-Address: 0xFEE00300
MP initialization protocol • Set shared processor-counter equal to 1 • Step 1: issue an ‘INIT’ IPI to all-except-self • Delay for 10 milliseconds • Step 2: issue ‘Startup’ IPI to all-except-self • Delay for 200 microseconds • Step 3: issue ‘Startup’ IPI to all-except-self • Delay for 200 microseconds • Check the value of the processor-counter
Issue ‘INIT’ IPI # address Local-APIC via register FS mov $sel_fs, %ax mov %ax, %fs # broadcast ‘INIT’ IPI to ‘all-except-self’ mov $0x000C4500, %eax mov %eax, %fs:0xFEE00300) .B0: btl $12, %fs:(0xFEE00300) jc .B0
Issue ‘Startup’ IPI # broadcast ‘Startup’ IPI to all-except-self # using vector 0x11 to specify entry-point # at real memory-address 0x00011000 mov $0x000C4611, %eax mov %eax, %fs:(0xFEE00300) .B1: btl $12, %fs:(0xFEE00300) jc .B1
Timing delays • Intel’s MP Initialization Protocol specifies the use of some timing-delays: • 10 milliseconds ( = 10,000 microseconds) • 200 microseconds • We can use the 8254 Timer’s Channel 2 for implementing these timed delays, by programming it for ‘one-shot’ countdown mode, then polling bit #5 at i/o port 0x61
Mathematical examples EXAMPLE 1 Delaying for 10-milliseconds means delaying for 1/100-th of a second (because 100 times 10 milliseconds = one-thousand milliseconds) EXAMPLE 2 Delaying for 200-microseconds means delaying 1/5000-th of a second (because 5000 times 200 microseconds = one-million microseconds) GENERAL PRINCIPLE Delaying for x–microseconds means delaying for 1000000/x seconds (because 1000000/x times x-microseconds = one-million microseconds)
Mathematical theory PROBLEM: Given the desired delay-time in microseconds, express the desired delay-time in clock-frequency pulses and program that number into the PIT’s Latch-Register RECALL: Clock-Frequency-in-Seconds = 1193182 Hertz ALSO: One second equals one-million microseconds APPLYING DIMENSIONAL ANALYSIS Pulses-Per-Microsecond = Pulses-Per-Second / Microseconds-Per-Second Delay-in-Clock-Pulses = Delay-in-Microseconds * Pulses-Per-Microsecond CONCLUSION For a desired time-delay of x microseconds, the number of clock-pulses may be computed as x * (1193182 /1000000) = 1193182 / (1000000 / x ) as dividing by a fraction amounts to multiplying by that fraction’s reciprocal
Delaying for EAX microseconds # We use the 8254 Timer/Counter Channel 2 to generate a # timed delay (expressed in microseconds by value in EAX) mov %eax, %ecx # copy delay-time to ECX mov %1000000, %eax # microseconds-per-sec xor %edx, %edx # extended to quadword div %ecx # perform dword division mov %eax, %ecx # copy quotient into ECX mov $1193182, %ecx # input-pulses-per-sec xor %edx, %edx # extended to quadword div %ecx # perform dword division # now transfer the quotient from AX to the Channel 2 Latch
Mutual Exclusion • Shared variables must not be modified by more than one processor at a time (‘mutual exclusion’) • The Pentium’s ‘lock’ prefix helps enforce this • Example: every processor adds 1 to count lock incl (count) • Example: all processors needs private stacks mov 0x1000, %ax lock xadd [new_SS], %ax mov %ax, %ss
ROM-BIOS isn’t ‘reentrant’ • The video service-functions in ROM-BIOS that we use to display a message-string at the current cursor-location (and afterward advance the cursor) modify global storage locations (as well as i/o ports), and hence must be called by one processor at a time • A shared memory-variable (called ‘mutex’) is used to enforce this mutual exclusion
Implementing a ‘spinlock’ mutex: .word 1 spin: btw $0, mutex jnc spin lock btrw $0, mutex jnc spin # <CRITICAL SECTION OF CODE GOES HERE> lock btsw $0, mutex
Demo: ‘smphello.s’ • Each CPU needs to access its Local-APIC • The BSP (“Boot-Strap Processor”) wakes up other processors by broadcasting the ‘INIT-SIPI-SIPI’ message-sequence • Each AP (“Application Processor”) starts executing at a 4K page-boundary, and needs its own private stack-area • Shared variables need ‘exclusive’ access
In-class exercise • Include this procedure that multiple CPUs will execute simultaneously (without ‘lock) total: .word 0 # the shared variable add_one_thousand: mov $1000, %cx nxinc: addw $1, (total) loop nxinc ret
We may need a ‘barrier’ • We can use a software construct (known as a ‘barrier’) to stop CPUs from entering a block of code until a prescribed number of them are all ready to enter it together arrived: .word 0 # shared variable barrier: lock incw (arrived) await: cmpw $2, (arrived) jb await call add_one_thouand