Multiprocessor Scheduling
Multiprocessor Scheduling. Module 3.1 For a good summary on multiprocessor and real-time scheduling, visit: http://www.cs.uah.edu/~weisskop/osnotes_html/M8.html. Classifications of Multiprocessor Systems. Loosely coupled multiprocessor, or clusters


Multiprocessor Scheduling
E N D
Presentation Transcript
Multiprocessor Scheduling Module 3.1 For a good summary on multiprocessor and real-time scheduling, visit: http://www.cs.uah.edu/~weisskop/osnotes_html/M8.html
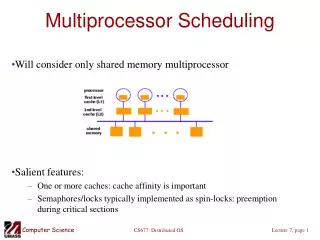
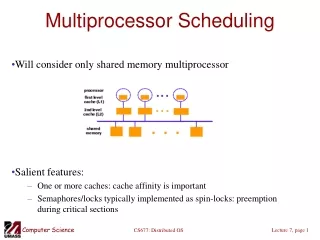
Classifications of Multiprocessor Systems • Loosely coupled multiprocessor, or clusters • Each processor has its own memory and I/O channels. • Functionally specialized processors • Such as I/O processor • Nvidia GPGPU • Controlled by a master processor • Tightly coupled multiprocessing • MCMP • Processors share main memory • Controlled by operating system • More economical than clusters
Types of parallelism • Bit-level parallelism • Instruction-level parallelism • Data parallelism • Task parallelism our focus
Synchronization Granuality • Refers to frequency of synchronization or parallelism among processes in the system • Five classes exist • Independent (SI is not applicable) • Very coarse (2000 < SI < 1M) • Course (200 < SI < 2000) • Medium (20 < SI < 200) • Fine (SI < 20) SIis called the Synchronization Interval, and measured in instructions.
Wikipedia on Fine-grained, coarse-grained, and embarrassing parallelism • Applications are often classified according to how often their subtasks need to synchronize or communicate with each other. • An application exhibits fine-grained parallelism if its subtasks must communicate many times per second; • it exhibits coarse-grained parallelism if they do not communicate many times per second, • and it is embarrassingly parallel if they rarely or never have to communicate. Embarrassingly parallel applications are considered the easiest to parallelize.
Independent Parallelism • Multiple unrelated processes • Separate application or job, e.g. spreadsheet, word processor, etc. • No synchronization • More than one processor is available • Average response time to users is less
Coarse and Very Coarse-Grained Parallelism • Very coarse: distributed processing across network nodes to form a single computing environment • Coarse: Synchronization among processes at a very gross level • Good for concurrent processes running on a multiprogrammed uniprocessor • Can by supported on a multiprocessor with little change
Medium-Grained Parallelism • Parallel processing or multitasking within a single application • Single application is a collection of threads • Threads usually interact frequently, leading to a medium-level synchronization.
Fine-Grained Parallelism • Highly parallel applications • Synchronization every few instructions (on very short events). • Fill the gap between ILP (instruction level parallelism) and Medium-grained parallelism. • Can be found in small inner loops • Use of MPI and OpenMP programming languages • OS should not intervene. Usually done by HW • In practice, this is very specialized and fragmented area
Scheduling • Scheduling on a multiprocessor involves 3 interrelated design issues: • Assignment of processes to processors • Use of multiprogramming on individual processors • Makes sense for processes (coarse-grained) • May not be good for threads (medium-grained) • Actual dispatching of a process • What scheduling policy should we use: FCFS, RR, etc. Sometimes a very sophisticated policy becomes counter productive.
Assignment of Processes to Processors • Treat processors as a pooled resource and assign process to processors on demand • Permanently assign process to a processor • Dedicate short-term queue for each processor • Less overhead. Each does its own scheduling on its queue. • Disadvantage: Processor could be idle (has an empty queue) while another processor has a backlog.
Assignment of Processes to Processors • Global queue • Schedule to any available processor • During the lifetime of the process, process may run on different processors at different times. • In SMP architecture, context switching can be done with small cost. • Master/slave architecture • Key kernel functions always run on a particular processor • Master is responsible for scheduling • Slave sends service request to the master • Synchronization is simplified • Disadvantages • Failure of master brings down whole system • Master can become a performance bottleneck
Assignment of Processes to Processors • Peer architecture • Operating system can execute on any processor • Each processor does self-scheduling from a pool of available processes • Complicates the operating system • Make sure two processors do not choose the same process • Needs lots of synchronization
Process Scheduling in Today’s SMP • M/M/M/K Queueing system • Single queue for all processes • Multiple queues are used for priorities • All queues feed to the common pool of processors • Specific scheduling disciplines is less important with more than one processor • A simple FCFS discipline with a static priority may suffice for a multi-processor system. • Illustrate using graph, p460 • In conclusion, specific scheduling discipline is much less important with SMP than UP
Threads • Executes separate from the rest of the process • An application can be a set of threads that cooperate and execute concurrently in the same address space • Threads running on separate processors yields a dramatic gain in performance
Multiprocessor Thread Scheduling --Four General Approaches (1/2) • Load sharing • Processes are not assigned to a particular processor • Gang scheduling • A set of related threads is scheduled to run on a set of processors at the same time
Multiprocessor Thread Scheduling --Four General Approaches (2/2) • Dedicated processor assignment • Threads are assigned to a specific processor. (each thread can be run on a processor.) • When program terminates, processors are returned to the processor available pool • Dynamic scheduling • Number of threads can be altered during course of execution
Load Sharing • Load is distributed evenly across the processors • No centralized scheduler required • OS runs on every processor to select the next thread. • Use global queues for ready threads • Usually FCFS policy
Disadvantages of Load Sharing • Central queue needs mutual exclusion • May be a bottleneck when more than one processor looks for work at the same time • A noticeable problem when there are many processors. • Preemptive threads will unlikely resume execution on the same processor • Cache use is less efficient • If all threads are in the global queue, all threads of a program will not gain access to the processors at the same time. • Performance is compromised if coordination among threads is high.
Gang Scheduling • Simultaneous scheduling of threads that make up a single process • Useful for applications where performance severely degrades when any part of the application is not running • Threads often need to synchronize with each other
Advantages • Closely-related threads execute in parallel • Synchronization blocking is reduced • Less context switching • Scheduling overhead is reduced, as a single sync to signal() may affect many threads
Dedicated Processor Assignment – Affinitization (1/2) • When application is scheduled, each of its threads is assigned a processor that remains dedicated/affinitized to that thread until the application runs to completion • No multiprogramming of processors, i.e. one processor per a specific thread, and no other thread. • Some processors may be idle as threads may block • Eliminates context switches; with certain types of applications this can save enough time to compensate for the possible idle time penalty. • However, in a highly parallel environment with 100 of processors, utilization of processors is not a major issue, but performance is. The total avoidance of switching results in substantial speedup.
Dedicated Processor Assignment – Affinitization (2/2) • In Dedicated Assignment, when the number of threads exceeds the number of available processors, efficiency drops. • Due to thread preemption, context switching, suspending of other threads, and cache pollution • Notice that both gang scheduling and dedicated assignment are more concerned with allocation issues than scheduling issues. • The important question becomes "How many processors should a process be assigned?" rather than "How shall I choose the next process?"
Dynamic Scheduling • Threads within a process are variable • Sharing the work between OS and application. • When a job originates, it requests a certain number of processors. The OS grants some or all of the request, based on the number of processors currently available. • Then the application itself can decide which threads run when on which processors. This requires language support as would be provided with thread libraries. • When processors become free due to the termination of threads or processes, the OS can allocate them as needed to satisfy pending requests. • Simulations have shown that this approach is superior to gang scheduling and or dedicated scheduling.