Residues Aligned
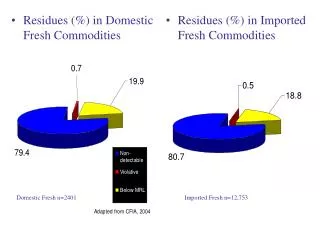
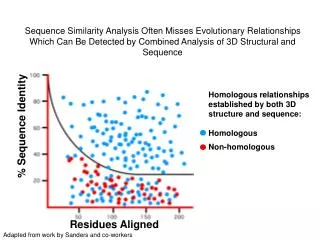
Sequence Similarity Analysis Often Misses Evolutionary Relationships Which Can Be Detected by Combined Analysis of 3D Structural and Sequence. Homologous relationships established by both 3D structure and sequence: Homologous Non-homologous. % Sequence Identity. Residues Aligned.

Residues Aligned
E N D
Presentation Transcript
Sequence Similarity Analysis Often Misses Evolutionary Relationships Which Can Be Detected by Combined Analysis of 3D Structural and Sequence Homologous relationships established by both 3D structure and sequence: Homologous Non-homologous % Sequence Identity Residues Aligned Adapted from work by Sanders and co-workers
Structure can often provide valuable clues to biochemical and biophysical aspects of protein function Structure-based Functional Genomics
Biological Functionsof Genes and Proteins • Genetic Function / Phenotype • Cellular Function • Biochemical Function • Detailed Atomic Mechanism • Biochemical Function • Detailed Atomic Mechanism
An Important Approach to the Protein Folding Problem is to Characterize the “Natural Language of Proteins” Representative 3D Structure from Each of Several Thousand Sequence Families of Domains
National Institutes of HealthProtein Structure Initiative (PSI) Long-Range Goal To make the three-dimensional atomic level structures of most proteins easily available from knowledge of their corresponding DNA sequences http://www.nigms.nih.gov/psi.html/ J. Norvell
Expected PSI Benefits • Structure provides information on function and will aid in the design of experiments • Development of better therapeutic targets from comparisons of protein structures from: • Pathogens vs. hosts • Diseased vs. normal tissues J. Norvell
PSI Benefits (con’t) • Collection of structures will address key biochemical and biophysical problems • Protein folding, prediction, folds, evolution, etc. • Benefits to biologists • Technology developments • Structural biology facilities • Availability of reagents and materials • Experimental outcome data on protein production and crystallization J. Norvell
PSI Pilot Phase • 5-year pilot phase, September, 2000 • Pilot phase Goals • Development of high throughput structure genomics pipeline to produce unique, non-redundant protein structures • Pilots for testing all facets and strategies of structural genomics • PSI target selection policy • Representatives of protein sequence families • Public release of all targets, progress, results, and structures J. Norvell
PSI Pilot Research Centers • Seven research centers funded in FY2000 • Two additional research centers funded in FY2001 • Co-funding by NIAID for two of the nine research centers • Many subprojects J. Norvell
PSI Pilot Phase -- Lessons Learned • Structural genomics pipelines can be constructed and scaled-up • High throughput operation works for many proteins • Genomic approach works for structures • Bottlenecks remain for some proteins • A coordinated, 5-year target selection policy must be developed • Homology modeling methods need improvement J. Norvell
Northeast Structural Genomics Consortium: A SG Research Network Bioinformatics Barry Honig, Columbia University Mark Gerstein, Yale University Sharon Goldsmith, Columbia University Chern Goh, Yale University Igor Jurisica, Ontario Cancer Inst. Andrew Laine, Columbia University Jessica Lau, Rutgers University Jinfeng Liu, Columbia University Diana Murray, Cornell Medical School Burkhard Rost, Columbia University Mike Wilson, Yale University X-ray Crystallography Wayne Hendrickson, Columbia University Peter Allen, Columbia University George DeTitta, Hauptman-Woodward John Hunt, Columbia University Rich Karlin, Columbia University Joe Luft, Hauptman-Woodward Alex Kuzin, Columbia University Phil Manor, Columbia University Liang Tong, Columbia University Kalyan Das, Rutgers University Protein Production / Biophysics Gaetano Montelione, Rutgers University Thomas Acton, Rutgers University Stephen Anderson, Rutgers University Cheryl Arrowsmith, Ontario Cancer Inst. YiWen Chiang, Rutgers University Natasha Dennisova, Rutgers Univedrsity Masayori Inouye, RWJMS - UMDNJ Lichung Ma, Rutgers University Rong Xiao, Rutgers University Adlinda Yee, Ontario Cancer Instit Protein NMR Thomas Szyperski, SUNY Buffalo James Aramani, Rutgers University Cheryl Arrowsmith, Ontario Cancer Inst. John Cort, Pacific Northwest Natl Labs Michael Kennedy, Pacific Northwest Natl Labs Gaouhua Liu , SUNY Buffalo Theresa Ramelot, Pacific Northwest Natl Labs Janet Huang, Rutgers University Gaetano Montelione, Rutgers University GVT Swapna, Rutgers University Bin Wu, Ontario Cancer Inst.
Goals of the NESG Consortium Short Term Develop a Scalable Platform for Structural and Functional Proteomics of Prokaryotic and Eukaryotic Proteins Long Term Characterize the repertoire of eukaryotic protein structural domain families
The NESG Publication Network PubNet Douglas, Montelione, Gerstein Bioinformatics, 2005 in press
Target Selection Strategy
Target Selection for Structural ProteomicsC. Orengo, Snowbird, UT 4.17.04 How many protein families can we identify in the genomes with/without structural representatives? Which families should we target to maximise the structural coverage of the genomes? Can we select families to optimise function coverage?
Rost Clusters: Structural Genomics Targets • Protein domain families / clusters • Full length proteins < 340 amino acids • No member > 30% identity to PDB structures • No regions of low complexity • Not predicted to be membrane associated ~ 20,000 “NESG Clusters”
NESG Domain Clusters Human cytomegalovirus Aeropyrum pernix Lactococcus lactis Aquifex aeolicus M. thermoautotrophicum Arabidopsis thaliana Neisseria meningitidis Archaeglobus fulgidis Other Bacillus subtilis Pyrococcus furiosus Brucella melitensis Pyrococcus horikoshi Caenorhabditis elegans Saccharomyces cerevisiae Campylobacter jejuni Staphylococcus aureus Caulobacter crescentus Streptococcus pyogenes Drosophila melanogaster Streptomyces coelicolor Deinococcus radiodurans Thermoplasma acidophilum Escherichia coli Thermotoga maritima Fusobacterium nucleatum Thermus thermophilus Haemophilus influenzae Vibrio cholerae Helicobacter pylori Homo sapiens • Protein domain families / clusters • Full length proteins < 340 amino acids • No member > 30% identity to PDB structures • No regions of low complexity • Not predicted to be membrane associated WR41 ET8 1 Euka: 2 Proka Cloned / Expressed > 1000 Human Proteins Liu, Hegi, Acton, Montelione, & Rost PROTEINS 2004. 56: 188-200 Wunderlich et al. PROTEINS 2004 56: 181-187 Acton et al. Meths Enzymol. 2005 in press
Protein Structure Production
Primer Prímer Program http://www-nmr.cabm.rutgers.edu/bioinformatics/index.html Everett, Acton, & Montelione 2004. J Struct Funct Genomics.
Auto-Steps with the Biorobot 8000 DNA Mini-preps PCR Reaction Qiaquick Purify Set up-96 well Colony PCR PCR Purification RestrictionDigest Transform Cycle Sequencing Ligation Big Dye removal
96- Well Expression Overnight culture Transfer ~200 ul of overnight culture to appropriate well 24 Well Blocks 2 ml of MJ9
HSQC and HetNOE Screening Amenability to Structural Determination by NMR Is Determined on NiNTA-Purified Samples HR969
Critical NMR Observation From SPiNE Some 30% of full-length, expressed, soluble eukaryotic proteins from the Rost Clusters produced in E. coli by NESG are DISORDERED based on Heteronuclear 1H-15N NOE Data It may not be possible to determine 3D structures of a large portion of the Rost domain families in isolation!
Sample Optimization - Buffer Screening Microdialysis Buttons- Optimization for NMR Vary Buffer Conditions - Stability Screen for ppt. Small sample mass (50 ug/button) 100 mM Arginine Bagby S, Tong KI, Liu D, Alattia JR, Ikura M. 1997. J Biomol NMR.
Analytical Gel Filtration with Light Scattering Aggregation Screening - Crystallization LS RI Proterion - 96 Well Less Sample More Conditions Monodisperse Conditions Philip Manor, Roland Satterwhite and John Hunt
ÄKTAxpress™ 4 modules in parallel16 samples AC-GF Affinity Chromatography (AC) HiTrap™ Chelating HP, 1 and 5 ml Gel Filtration (GF) HiLoad 16/60 Superdex 200 pg AC 5 hours AC/GF 12 hours
Solubility / 2004 Stats Solubility vs Organism 2004 Production 2004 HR Success Many HR (Human) proteins in advanced stages of NMR 3 HR Crystal structures *defined as greater than 60% soluble by SDS-PAGE analysis T. Acton et al
NESG PROGRESS SUMMARY Jan 1, 2005 Intrinsically Disordered Proteins Full-length Proteins Produced in E. coli Organism% Unfolded E. coli 8% yeast 18% fly / worm 25% human 35%
Phylogenetic Distribution of 160 NESG Structures Most (>95%) completed NESG structures are members of eukaryotic protein domain families Eukaryotic Archea Some 35 (~20%) NESG structures submitted to the PDB are eukaryotic proteins Eubacteria
Leverage of NESG Structures Total Leverage ~20,000 Structures Novel Leverage ~ 4,000 Structures upper panel shows the number of new models that could be built for ten entirely sequenced eukaryotes (tan) and for the human genome (green) lower panel: number of proteins for which the sequence-unique structures experimentally determined (red) by each consortium could be used to buildhomology models (light green). Liu and Rost