Download
1 / 1
10 likes | 161 Views
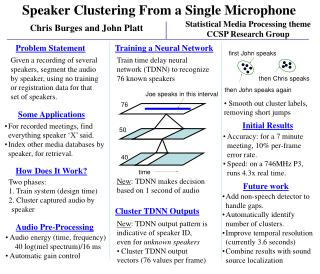
Speaker Clustering From a Single Microphone. Statistical Media Processing theme CCSP Research Group. Chris Burges and John Platt. Problem Statement. Training a Neural Network. first John speaks.

E N D
Speaker Clustering From a Single Microphone Statistical Media Processing theme CCSP Research Group Chris Burges and John Platt Problem Statement Training a Neural Network first John speaks Given a recording of several speakers, segment the audio by speaker, using no training or registration data for that set of speakers. Train time delay neural network (TDNN) to recognize 76 known speakers then Chris speaks then John speaks again Joe speaks in this interval • Smooth out cluster labels, removing short jumps 76 Some Applications Initial Results • For recorded meetings, find everything speaker ‘X’ said. • Index other media databases by speaker, for retrieval. 50 • Accuracy: for a 7 minute meeting, 10% per-frame error rate. • Speed: on a 746MHz P3, runs 4.3x real time. 40 How Does It Work? time New: TDNN makes decision based on 1 second of audio • Two phases: • Train system (design time) • Cluster captured audio by speaker Future work • Add non-speech detector to handle gaps. • Automatically identify number of clusters. • Improve temporal resolution (currently 3.6 seconds) • Combine results with sound source localization Cluster TDNN Outputs • New: TDNN output pattern is indicative of speaker ID, even for unknown speakers • Cluster TDNN output vectors (76 values per frame) Audio Pre-Processing • Audio energy (time, frequency) • 40 log(mel spectrum)/16 ms • Automatic gain control