Download

1 / 18
180 likes | 298 Views
This paper explores advanced Fuzzy C-Means (FCM) clustering algorithms aimed at effectively determining the optimal number of clusters in datasets, addressing challenges like outliers and membership grading. The authors introduce a new validity index to improve clustering validation and present experimental results using various datasets, including biometric data from the IRIS dataset and Gaussian mixtures. Key contributions include an enhanced FCM model selection algorithm and insights into dimension reduction applications. The findings underscore FCM’s adaptability and robustness in clustering tasks.

E N D
FCM-Based Model Selection Algorithms for Determining theNumber of Clusters HaojunSun,ShengruiWang*,Qingshan Jiang Received 16 December 2002; received in revised form 29 March 2004; accepted 29 March 2004 Presenter Chia-Cheng Chen
Outline • Introduction • Basic algorithm • A new validity index • Experimental results • Conclusion and perspectives
Introduction • Clustering is a process for grouping a set of objects into classes or clusters so that the objects within a cluster have high similarity. • Because of its concept of fuzzy membership, FCM is able to deal more effectively with outliers and to perform membership grading, which is very important in practice.
Basic algorithm • FCM algorithm
Basic algorithm(Cont.) • FCM-based model selection algorithm
Basic algorithm(Cont.) • FBSA: FCM-Based Splitting Algorithm
Basic algorithm(Cont.) • Function S(i)
A new validity index • A new validity index
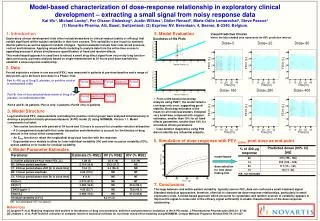
Experimental results • DataSet1 • IRIS data • This is a biometric data set consisting of 150 measurements belonging to three flower varieties • DataSet2 • Mixture of Gaussian distributions • 50 data vectors in each of the 5ve clusters • DataSet3 • Mixture of Gaussian distributions • 500 data vectors
Conclusion and perspectives • The major contributions of this paper are an improved FCM-based algorithm for determining the number of clusters and a new index for validating clustering results. • Use of the new algorithm to deal with the dimension reduction problem is another promising avenue.