Download

1 / 23
240 likes | 498 Views
Automatic Identification of Cognates, False Friends, and Partial Cognates. University of Ottawa, Canada. Outline. Overview of the Thesis Research Contribution Cognate and False Friend Identification Partial Cognate Disambiguation CLPA- Cognate and False Friend Annotator

E N D
Automatic Identification of Cognates, False Friends, and Partial Cognates University of Ottawa, Canada
Outline • Overview of the Thesis • Research Contribution • Cognate and False Friend Identification • Partial Cognate Disambiguation • CLPA- Cognate and False Friend Annotator • Conclusions and Future Work
Overview of the Thesis Tasks • Automatic Identification of Cognates and False Friends • Automatic Disambiguation of Partial Cognates Areas of Applications • CALL,MT, Word Alignment, Cross-Language Information Retrieval CALL Tool - CLPA
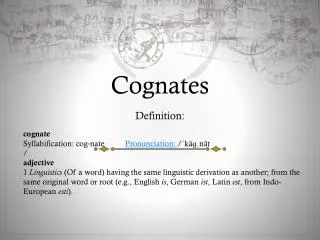
Definitions • Cognates or True Friends (Vrais Amis), are pairs of words that are perceived as similar and are mutual translations. nature - nature, reconnaissance - recognition • False Friends (Faux Amis) are pairs of words in two languages that are perceived as similar but have different meanings. main (=hand) -main (principal, essential), blesser (=to injure) -bless (bénir in French) • Partial Cognates words that share the same meaning in two languages in some but not all contexts note – note,facteur - factor or mailman, maker
Research Contribution • Novel method based on ML algorithms to identify Cognates and False Friends • A method to create complete lists of Cognates and False Friends • Define a novel task: Partial Cognate Disambiguation, and solve it using a supervised and a semi-supervised method • Combine and use corpora from different domains • Implement a CALL Tool – CLPA to annotate Cognates and False Friends
Cognates and False Friends Identification • Our method • Machine Learning techniques with different algorithms • Instances: French-English pairs of words • Feature Space: 13 orthographic similarity measures • Classes: Cog_FF and Unrelated Experiments done for: • Each measure separately • Average of all measures • All 13 measures
Complete Lists of Cognates and False Friends • Method • Use the XXDICE orthographic similarity measure • Use list of pairs of words in two languages (the words that are translation of each other, or not, or monolingual lists of words) • Use a bilingual dictionary to determine if the words contained in a pair are translation of each other
Complete Lists of Cognates and False Friends • Evaluation • On the entry list of a French-English bilingual dictionary • 55% - Cognates • 2% - False Friends (5,619,270 pairs) • We created pair of words from two large monolingual list of words in French and English • 11,469,662 – Orthographical Similar (0.8%) • 3,496 Cognates (0.03%) • 3,767,435 False Friends (32%)
Cognates and False Friends Identification Conclusion • We tested a number of orthographic similarity measures individually, and also combined using different Machine Learning algorithms • We evaluated the methods on a training set using 10-fold cross validation, on a test set • We proposed an extension of the method to create complete lists of Cognates and False Friends • The results show that, for French and English, it is possible to achieve very good accuracy based on the orthographic measures of word similarity
Partial Cognate Disambiguation • Task • To determine the sense/meaning (Cognate or False Friend with the equivalent English word) of an Partial Cognate in a French context Note Cog Le comité prend note de cette information. The Committee takes note of this reply. FF Mais qui a dû payer la note? So who got left holding the bill?
Data • Use a set of 10 Partial Cognates • Parallel sentences that have on the French side the French Partial Cognate and on the English side the English Cognate (English False Friend) - labeled as COG (FF) • Collected from EuroPar, Hansard • ~ 115 sentences each class for Training • ~ 60 sentences each class for Testing
Supervised Method Traditional ML algorithms Features - used the bag-of-words (BOW) approach of modeling context, with the binary feature values - context words from the training corpus that appeared at least 3 times in the training sentences Classes COG and FF
Monolingual Bootstrapping Foreach pair of partial cognates (PC) 1. Train a classifier on the training seeds – using the BOW approach and a NB-K classifier with attribute selection on the features 2. Apply the classifier on unlabeled data – sentences that contain the PC word, extracted from LeMonde (MB-F) or from BNC (MB-E) 3. Take the first k newly classified sentences, both from the COG and FF class and add them to the training seeds (the most confident ones – the prediction accuracy greater or equal than a threshold =0.85) 4. Rerun the experiments training on the new training set 5. Repeat steps 2 and 3 for t times endFor
Bilingual Bootstrapping 1. Translate the English sentences that were collected in the MB-E step into French using an online MT tool and add them to the French seed training data. 2. Repeat the MB-F and MB-E steps for T times.
Additional Data • LeMonde • An average of 250 sentences for each class • BNC • An average of 200 sentences for each class • Multi-Domain corpus • An average of 80 sentences for each class
Partial Cognate Disambiguation Conclusions • Simple methods and available tools are used with success for a task hard to solve even forhumans • Additional use of unlabeled data improves the learning process for the Partial Cognates Disambiguation task • Semi-Supervised Learning proves to be “as good as” Supervised Learning
Future Work • Apply the Cognate and False Friend Identification method, and create complete list for other pair of languages • Increase the accuracy results for the Partial Cognate Disambiguation task • Use lemmatization for French texts and human evaluation for CLPA