Impact of Collaborative Classifier Agents on Distributed Document Classification Learning
This study explores the effectiveness of collaborative classifier agents in distributed document classification. Motivated by limitations in centralized classification, we investigate knowledge distribution, fault tolerance, and adaptability. Using a simulation approach, we compare collaboration effectiveness across agent models with two learning algorithms: Pursuit Learning and Nearest Centroid Learning. Experimental results demonstrate that collaborative learning improves classification efficiency and adaptability but also reveals challenges in knowledge sharing as distribution increases. Future research will expand on different text collections and agent collaboration dynamics.


Impact of Collaborative Classifier Agents on Distributed Document Classification Learning
E N D
Presentation Transcript
Studying the Impact of Learning in Distributed Document Classification Collaborative Classifier Agents by WeimaoKe, JavedMostafa, and YueyuFu {wke, jm, yufu}@indiana.edu Laboratory of Applied Informatics Research Indiana University, Bloomington Laboratory of Applied Informatics Research (LAIR)
Outline • Introduction • Motivation and research questions • Research model and methodology • Experimental design • Experimental results • Summary and future work
Intro: Centralized classification A Centralized Classifier Classifier Knowledge
Intro: Why not centralized? • Global repository is rarely realistic • Scalability • Intellectual property restrictions • … ?
Intro: Knowledge distribution Arts Sciences Distributed repositories History Politics
Intro: Distributed classification Distributed Classification Classifier Knowledge Assignment Classification
Intro: Collaborative classification Collaboration for classification Classifier Knowledge Assignment Classification
Motivation & Research Questions • Why distributed classification? • The nature of knowledge distribution • Advantages of distributed classification: fault tolerance, adaptability, flexibility, privacy, etc. • Problems/Questions • Classifier agents have to learn and collaborate. But how? • Effectiveness and efficiency of agent collaboration? • The dynamics of agent collaboration?
Methodology: Agent simulation • To compare • Centralized approach (upper-bound) • Distributed approach without collaboration (lower-bound) • Distributed approach with collaboration • Two learning/collaboration algorithms: • Algorithm 1: Pursuit Learning • Algorithm 2: Nearest Centroid Learning • Two parameters • r: Exploration Rate • g: Maximum Collaboration Range • Evaluation Measure • Effectiveness: precision, recall, F measure • Efficiency: time for classification • Precision = a / (a + b) • Recall = a / (a + c) • F1 = 2 * P * R / (P + R)
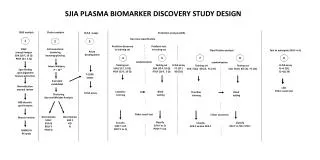
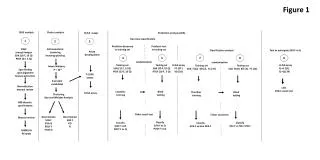
Exp design: Data collection • Reuters Corpus Volumes 1 (RCV1) • 37 classes / categories • “Knowledge” represented by the training class vectors • Training set: 6,394 documents • Test set: 2,500 documents • Feature selection: 4,084 unique terms
Exp design: baselines Knowledge division 1 agent • Without collaboration Upper bound baseline 2 agents 4 agents … 37agents Lower bound baseline
Exp design: agent collaboration Knowledge division 1 agent • With collaboration • Algorithms • Pursuit leaning • Nearest centroid learning • Parameters • Exploration rate • Max collaboration range Upper bound baseline 2 agents 4 agents … 37 agents Lower bound baseline
Exp design: Agent simulation model 2 • Parameters for learning/prediction: • 1. Exploration rate (r) • 2. Max collaboration range (g) 1 2 Doc Distributor 1 3 Documents # Classifier agent 4 Collaboration request Collaboration response
Exp results: Collaboration effectiveness PL optimal zone random
Exp results: learning dynamics Learning converged?
Summary • Classification effectiveness decreases dramatically when knowledge becomes increasingly distributed. • Pursuit Learning • Efficient – without analyzing contents • Effective, although not content sensitive • “The Pursuit Learning approach did not depend on document content. By acquiring knowledge through reinforcements based on collaborations this algorithm was able to construct/build paths for documents to find relevant classifiers effectively and efficiently.” • Nearest Centroid Learning • Inefficient – analyzing content • Effective • Future work • Other text collections • Knowledge overlap among the agents • Local neighborhood