Hierarchical Bayesian Transfer for Reinforcement Learning
Explore a method for transfer learning in sequential decision problems using a hierarchical Bayesian approach. Discover and exploit hierarchical structures within tasks. Implement Model-Based and Policy-Based Multi-Task RL to solve complex problems efficiently. Experiment with tactical games.


Hierarchical Bayesian Transfer for Reinforcement Learning
E N D
Presentation Transcript
Transfer Learning in Sequential Decision Problems:A Hierarchical Bayesian Approach Aaron Wilson, Alan Fern, Prasad Tadepalli School of EECS Oregon State University
Markov Decision Processes • MDP • M : • R : • Policy • Seek optimal policy: Environment Agent
Environment M1 Environment M2 Environment Mn Multi Task Reinforcement Learning (MTRL) • Given: A sequence of Markov Decision Processes drawn from an unknown distribution D. • Goal: Leverage past experience to improve performance on new MDPs drawn from D.
MTRL Problem • Tasks have hierarchical relationships. • Set of classes (unknown to the agent). • Natural means of transfer (class discovery).
Hierarchical Bayesian Modeling • Foundation: • Dirichlet Process Models • Unknown number of classes. • Discover hierarchical structure. • Explicit formulation of Uncertainty • Adapt machinery to the RL setting. • Well justified transfer for RL problems.
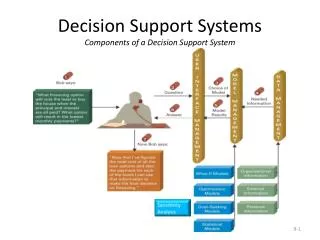
Compute Posterior Select Best Hierarchy Select Actions (Bayesian RL) Basic Hierarchical Transfer Process Process Inference
Hierarchical Bayesian Transfer for RL • Model-Based Multi-Task RL • Prior model for domain models. • Action selection: • Thompson sampling • Planning • Policy-Based Multi-Task RL • Prior for policy parameters. • Action selection: • Bayesian Policy Search algorithm.
Model-Based MTRL • Explicitly Model the Generative Process D • Hierarchy represents classes of MDPs. Class Prior Estimate D
Compute Posterior Plan Action Selection: Exploit estimate of D • Exploit the refined prior (class information). • Sample the MDPs using Thompson Sampling. • Plan with the sampled model (Value Iteration).
Domain 1 • State is a bit vector: • True reward function: • Set of 20 test maps. State
Domain 1 16 previous tasks No Transfer
Policy-Based MTRL • Policy prior. • Infer policy components. • Hierarchy represents reusable policy components. Class Prior Estimate H
Consider Wargus RTS • Multiple Unit types. • Units fulfill tactical roles. • Roles are useful in multiple maps. • Simple->hard instances • Hierarchical policy prior. • Facilitate reuse of roles.
Role Based Policies Set of Roles. Vectors of policy parameters. Who to attack. Set of role assignments. A strategy for assigning agents to roles. Assignment depends on state features. Executing role-based policy 1. Make the assignment 2. Each agent selects action
Transfer of Role-Based Policies • Bayesian Policy Search • Learns • Individual Role parameters. • Role assignment function. • Assignments of agents to roles. • Sample role-based policies • Construct an artificial distribution [Hoffman et. al. NIPS 2007, Muller Bayes Stats.1999] • Search using stochastic simulation • Model free. Bayesian Policy Search
Experiments • Tactical battles in Wargus • Transfer given expert examples. • Learning without expert examples.
Transfer from self play Use BPS on Training Map 1. Transfer to new map.
Conclusion • Hierarchical Bayesian Modeling for RL Transfer • Model-Based MTRL • Learn classes of domain models. • Transfer: Improved priors for model-based Bayesian RL. • Policy-Based MTRL • Learn re-usable policies. • Transfer: Recombine learned policy components in new tasks. • Solved tactical games in Wargus
Outline • Multi-Task Reinforcement Learning (RL). • Markov Decision Processes. • Multi-task RL setting • Policy-Based Multi-task RL • Discover classes of policy components. • Bayesian Policy Search Algorithm. • Conclusion
Policy-Based MTRL • Observed property: • Bags of trajectories. • Transfer: • Classes of policy components • Means of exploiting transferred information: • Recombine existing components in new tasks. • Consequence: • Components reused to learn hard tasks.
Outline • Markov Decision Processes • Bayesian Model Based Reinforcement Learning • Multi Task Reinforcement Learning (MTRL) • Modeling the MTRL Problem • MTRL Transfer Algorithm • Estimating parameters of the generative process. • Action Selection. • Results • Conclusion
Environment Bayesian Model Based RL • Given prior: • Plan using updated model. • Most work uses uninformed priors. • Selection of prior not supported by data. • Priors do not facilitate transfer.