Download

1 / 13
140 likes | 341 Views
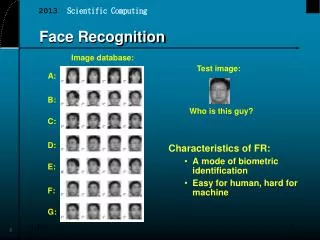
Face Recognition in Video. Int. Conf. on Audio- and Video-Based Biometric Person Authentication (AVBPA ’03) Guildford, UK June 9-11, 2003 Dr. Dmitry Gorodnichy Computational Video Group Institute for Information Technology National Research Council Canada http://www.cv.iit.nrc.ca/~dmitry.

E N D
Face Recognition in Video Int. Conf. on Audio- and Video-Based Biometric Person Authentication (AVBPA ’03)Guildford, UK June 9-11, 2003 Dr. Dmitry GorodnichyComputational Video GroupInstitute for Information Technology National Research Council Canada http://www.cv.iit.nrc.ca/~dmitry
What makes FR in video special ? Constraints: • Real-time processing is required. • Low resolution: 160x120 images or mpeg-decoded. • Low-quality: week exposure, blurriness, cheap lenses. Importance: • Video is becoming ubiquitous. Cameras are everywhere. • For security, computer–human interaction, video-conferencing, entertainment … Essence: • It is inherently dynamic! • It has parallels with biological vision! NB: Living organisms also process very poor images*, yet they are very successful in tracking, detection and recognition. * - except for a very small area (fovea)
Lessons from biological vision • Images are of very low resolution except in the fixation point. • The eyes look at points which attract visual attention. • Saliency is: in a) motion, b) colour, c) disparity, d) intensity. • These channels are processed independently in brain (Think of a frog catching a fly or a bull running on a torero) • Intensity means: frequencies, orientation, gradient . • Brain process the sequences of images rather than one image. - Bad quality of images is compensated by the abundance of images. • Animals & humans perceive colour non-linearly. • Colour & motion are used for segmentation. • Intensity is used for recognition. • Bottom-up (image driven) visual attention is very fast and precedes top-down (goal-driven) attention: 25ms vs 1sec.
Localization first. Then recognition • Try to recognize a face at right • What about the next one? What did you do? – • First you detected face-looking regions. • Then, if they were too small or badly orientated, you did nothing. Otherwise, you turned your face – right? • …to align your eyes with the eyes in the picture. • …since this was the coordinate system in which you stored the face. • This is what biological vision does. - Localization (and tracking) of the object precedes its recognition - These tasks are performed by two different parts of visual cortex. So, why computer vision should not do the same?
These mesmerizing eyes Did you notice that you’ve started examining this slideby looking at the eyes (or circles) at left? - These pictured are sold commercially to capture infants attention. Now imagine that the eyes blinked …- For sure you’ll be looking at them! No wonder, animals and humans look at each other’s eyes. - This is apart from psychological reasons. • Eyes are the most salient features on a face. • Besides, there two of them, which creates a hypnotic effect (which is due to the fact that the saliency of a pixel just attended is inhibited to avoid attending it again soon.) • Finally, they also the best (and the only) stable landmarks on a face which can be used a reference. Intra-ocular distance (IOD) make a very convenient unit of measurement!
Which part of the face is the most informative?What is the minimal size of a recognizable face? • By studying previous work: [CMU, MIT, UIUC, Fraunhofer, MERL, …] • By examining averaged faces: • By computing statistical relationship between face pixels in 1500 faces from the BioID Face Database: 16x16 24x24 12x12 9x9 Using the RGB colours, each point in this 576x576 array shows, how frequently two pixels of the 24x24 face are darker one another, brighter one another or are the same(within a certain boundary) The presence of high contrast RGB colours in the image indicates the strong relationship between the face pixels. Such the strongest relationship is observed for 24x24 images centered on the eye as shown on the next slide.
Anthropometrics of face Surprised to the binary nature of our faces? But it’s true - Tested with 1500 faces from BioID face database and multiple experiments with perceptual user interfaces [Nouse’02, BlinkDet’03]. 2.IOD .IOD 24 2. IOD Do you also see that colour is not important for recognition? - while for detection, it is.
Canonical eye-centered face model Procedure: after the eyes are located, the face is extracted from video and resized to the canonical 24x24 form, in which it is memorized or recognized. Size 24 x 24 is sufficient for face memorization & recognition and is optimal for low-quality video and for fast processing. Canonical face model suitable for Face Recognition in documents [Identix’02] Canonical face model suitable for on-line Face Memorization and Recognition in video [Gorodnichy’03] 2. .IOD d 24 2. .IOD
Face Processing Tasks “I look and see…” Face Segmentation “Something yellow moves” Face Detection “It’s a face” Face Tracking (crude) “Lets follow it!” Face Localization (precise) “It’s at (x,y,z,a,b,g)” Facial Event Recognition Face Classification “S/he smiles, blinks” “It’s face of a child” Face Memorization Face Identification “Face unknown. Store it!” “It’s Mila!” Applicability of 160x120 video to the tasks, according to face anthropometrics Hierarchy of face recognition tasks … • – goodb – barely applicable- – not good (tested with Perceptual User Interfaces)
Perceptual Vision Interfaces face detection blink detection face tracking (crude) nose tracking (precise) colour calibration x y ( za ) “click” event face classification face memorization face identification PUI binary event ON x y , z a , b g OFF recognition /memorization Unknown User! monitor Multi-channel video processing framework Goal: To detect, track and recognize face and facial movements of the user.
Recent Advances in PUI 1. NouseTM (Use Nose as Mouse) Face Tracking - based on tracking rotation-invariant convex shape nose feature [FGR’02] - head motion- and scale- invariant & sub-pixel precision "NouseTM brings users with disabilities and video game fans one step closer to a more natural way of interacting hands-free with computers" - Silicon Valley North magazine, Jan 2002 "It is a convincing demonstration of the potential uses of cameras as natural interfaces." - The Industrial Physicist, Feb. 2003 2. Eye blink detection in moving heads - based on computing second-order change [Gorodnichy’03] & non-linear change detection [Durucan’01]- is currently used to enable people with brain injury [AAATE’03] 1 & 2:After each blink, eyes and nose positions are retrieved. If they form an equilateral triangle (i.e.face is parallel to image plane), than face is extracted and recognized / memorized. Figure 1. This logo of the NouseTM Technology website is written by nose. t-2 t-1 t Figure 2. A camera tracks the point of each player’s nose closest to the camera and links it to the red “bat” at the top (or bottom) of the table to return the omputer ball across the “net.” (The Industrial Physicist) Figure 3. Commonly used first-order change (left image) has many pixels due to head motion (shown in the middle). Second-order change (right image) detects the local change only (change in a change), making it possible to detect eye blinks in moving heads, which was previously not possible.
Recognition with Associative Memory • We use Pseudo-Inverse Associative Memory for on-line memorization and storing of faces in video. • The advantages of this memory over others, as well as the Cpp code, are available from our website. • Main features: • It stores binary patterns as attractors. • The accociativity is achieved by converging from any state to an attractor: • Faces are made attractors by using the Pseudo-Inverse learning rule: C = VV+ or • Saturation of the network is avoided by using the desaturation technique [Gorodnichy’95]: Cii = D * Cii (0<D<1) or • Converting 24x24 face to binary feature vector: A) Vi =Ii - Iave , B ) Vi,j =sign(Ii - Ij ), C ) Vi,j =Viola(i,j,k,l), D ) Vi,j =Haar(i,j,k,l) PINN website: www.cv.iit.nrc.ca/~dmitry/pinn
Summary & Demos • The face is • detected: using motion at far range (non-linear change detection), using colour at close range (non-linear colour mapping to perceptual uniform space) • than tracked until convenient forrecognition: using blink detection and nose tracking • than localized and transformed to the canonical 24x24 representation, • than recognized using the PINN associative memory trained pixel differences. In experiments:With 63 faces from BioD database and 9 faces of our lab users (all of which are shown) stored, the system has no problem recognizing our users after a single (or several) blinks. In many cases, as a user involuntary blinks, s/he is even not aware of the fact that his/her face is memorized / recognized. E.g. images retrieved from blink (at left) are recognized as the right image More at www.perceptual-video.com/faceinvideo.html