Partitioning, Divide and Conquer
670 likes | 1.08k Views
Partitioning, Divide and Conquer. Partitioning Dividing the problem into parts Most strategies require coordination between the parts Embarrassingly parallel is an exception Partitioning can typically be done in two ways Dividing the data Data partitioning or domain decomposition

Partitioning, Divide and Conquer
E N D
Presentation Transcript
Partitioning, Divide and Conquer • Partitioning • Dividing the problem into parts • Most strategies require coordination between the parts • Embarrassingly parallel is an exception • Partitioning can typically be done in two ways • Dividing the data • Data partitioning or domain decomposition • Dividing the program • Functional decomposition • Divide and Conquer • Dividing a problem into sub-problems that are of the same form as the original problem • Mandelbrot program • Integration Divide and Conquer Strategies
Parallel Programming Paradigms • Result Parallelism • Focuses on the result • Break the results into components and assign processes to work on each part of the result • Specialist Parallelism • Focuses on the ability of the “work crew” • Agenda Parallelism • Focuses on the list of tasks to be performed (http://www.mcs.drexel.edu/~jjohnson/fa02/cs730/lectures/lec1.ppt) Divide and Conquer Strategies
Programming Methods • Live Data Structures • Build program in the shape of the data structure that will ultimately give the result. Each element of the data structure is a separate process • No messages exchanged, processes refer to each other. • Message Passing • Enclose every data structure within a process • Distributed Data Structures • Many processes share direct access to many other data objects. • Processes coordinate by leaving data in shared space (http://www.mcs.drexel.edu/~jjohnson/fa02/cs730/lectures/lec1.ppt) Divide and Conquer Strategies
Good Parallel Programming Environments • Augment sequential programming language most appropriate for task • Support • Process creation • Interprocess communication • As natural extensions to base language • Portable • Easy to use (conceptually and in practice) Divide and Conquer Strategies
Issues for Portability • Broad spectrum of machines • Computation/communication ratio differs dramatically among architectural classes • Portable program may run poorly on another architecture, but can tweak later • Same class machine does not mean same programming environment • Works best for • Relatively coarse grain • Non-communication intensive Divide and Conquer Strategies
Most Models of Parallelism Assume Programs Parallelized By • Process parallelism – partitioning into large number of simultaneous activities • Data parallelism – partitioning data into large number of identical sets and then synchronously applying same program operation to each set Divide and Conquer Strategies
T4 T3 T2 T1 T0 Pipeline • Processors are arranged in a pipeline (virtually) • Work is sent down the pipeline for processing • Full utilization of the processors does not occur until the pipe is full P0 P1 P2 P3 Divide and Conquer Strategies
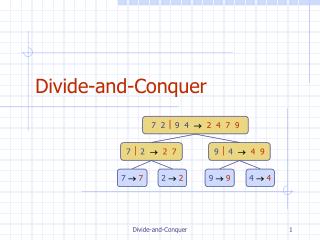
Matrix Multiplication • To make this discussion easier we will assume square matrices • The product of two n by n matrices A and B is given by • Note that all valid products are of the form Divide and Conquer Strategies
Dissection Time a00 a01 a02 a10 a11 a12 a20 a21 a22 b00 b01 b02 b10 b11 b12 b20 b21 b22 x = a00*b00+a01*b10+a02*b20 a00*b01+a01*b11+a02*b21 a00*b02+a01*b12+a02*b22 a10*b00+a11*b10+a12*b20 a10*b01+a11*b11+a12*b21 a10*b02+a11*b12+a12*b22 a20*b00+a21*b10+a22*b20 a20*b01+a21*b11+a22*b21 a20*b02+a21*b12+a22*b22 Divide and Conquer Strategies
Parallelize • Organize the PE grid as a N x N x N cube • Place the data in the processors so that each computes a sum for one of the Cij’s so the multiplication can be done in one step • All that is left to sum the products Divide and Conquer Strategies
Parallelize a02*b20 a02*b21 a02*b22 a12*b20 a12*b21 a12*b22 a22*b20 a22*b21 a22*b22 Sum Reduction a01*b10 a01*b11 a01*b12 a11*b10 a11*b11 a11*b12 a21*b10 a21*b11 a21*b12 a00*b00 a00*b01 a00*b02 a10*b00 a10*b01 a10*b02 a20*b00 a20*b01 a20*b02 Divide and Conquer Strategies
The Algorithm The algorithm for parallel matrix multiplication • Load the arrays into the processors • Everyone multiplies • Do a REDUCE.SUM from back to front • Result is in the front 3x3 plane of the cube Divide and Conquer Strategies
Using Fewer Processors b22 b12 b02 b21 b11 b01 b20 b10 b00 a02 a01 a00 a12 a11 a10 a22 a21 a20 Divide and Conquer Strategies
Using Fewer Processors b22 b12 b02 b21 b11 b01 b20 b10 a02 a01 a12 a11 a10 a22 a21 a20 Divide and Conquer Strategies
Using Fewer Processors b22 b12 b02 b21 b11 b20 a02 a12 a11 a22 a21 a20 Divide and Conquer Strategies
Using Fewer Processors b22 b12 b21 a12 a22 a21 Divide and Conquer Strategies
Using Fewer Processors b22 a22 Divide and Conquer Strategies
Improving Efficiency a00*b00+a01*b10+a02*b20 a00*b01+a01*b11+a02*b21 a00*b02+a01*b12+a02*b22 a10*b00+a11*b10+a12*b20 a10*b01+a11*b11+a12*b21 a10*b02+a11*b12+a12*b22 a20*b00+a21*b10+a22*b20 a20*b01+a21*b11+a22*b21 a20*b02+a21*b12+a22*b22 Divide and Conquer Strategies
Improving Efficiency Divide and Conquer Strategies
Farmer/Worker • One way to do data partitioning • Farmer prepares tasks for workers • Workers receive task and do the work • Work is sent back to farmer • Farmer consolidates results P0 P4 P3 P1 P5 P2 Farmer Divide and Conquer Strategies
Linda • Linda is a memory model • A model represents a particular way of thinking about problems • Every process has access to a shared pool of memory referred to as tuple space • Data tuples • Process tuples • Processes coordinate by generating, reading, and consuming tuples Divide and Conquer Strategies
David Gelernter • Linda was developed by David Gelernter, a CS professor at Yale When it came time to name the language, Mr Gelernter said he noted that Ada was named after Ada Augusta Lovelace, the daughter of Lord Byron, the English poet. Miss Lovelace is regarded as the first computer programmer because she worked for the computer pioneer Charles Babbage. Another woman named Lovelace was in the news when Mr Gelernter was casting about for a name -- Linda Lovelace, a star of pornographic films. So he named the language Linda, and it stuck. Asked about it now, Mr Gelernter grins and shrugs, "I was a graduate student at the time," he said. Divide and Conquer Strategies
David Gelernter • David Hillel Gelernter is a professor of computer science at Yale University. In the 1980s, he made seminal contributions to the field of parallel computation, specifically the tuple space model of coordination and the Linda Programming System.He received his Bachelor of Arts degree from Yale University in 1976, and his Ph.D. from the State University of New York, Stony Brook in 1982.In 1993, he was critically injured opening a mailbomb sent by Theodore Kaczynski, who at that time was an unidentified but violent opponent of technological progress, dubbed by the press as "The Unabomber". He recovered from his injuries, while sustaining permanent damage to his right hand and eye; chronicling the ordeal in his 1997 book Drawing Life: Surviving the Unabomber.He was nominated to and subsequently became a member of The National Council on the Arts. His biographical summary can be found at the National Endowment for the Arts web site(http://www.nea.gov/about/NCA/Gelernter.html) Divide and Conquer Strategies
Linda Goals • High level language for explicit parallel programming • Portability • No temporal or spatial relationships between parallel processes • Dynamic distribution of tasks at runtime supporting • Dynamic process creation • Static allocation Divide and Conquer Strategies
Linda – A Memory Model • Tuple Space • Logically shared associative memory • Collection of logically ordered sets of data (tuples) • Accomplish work by generating, using, consuming data tuples • Process tuples • Under active evaluation • When done, become data tuple • Data Tuples • Passive Divide and Conquer Strategies
Tuple Space Sender Sender Tuple Space Receiver Receiver Divide and Conquer Strategies
Linda – A Programming Model • Linda: • Smart optimizing pre-compiler • Run-time kernel • Shown to work well with shared memory • Suggested will work on distributed memory • Brenda (Trollius/Cornell) • University of MN (Transputer) • Cogent Research (OS Model) • Laden (RIT) Divide and Conquer Strategies
Characteristics of the Linda Model • Processes are decoupled • Process create, look at, destroy data objects • Will wait, if try to read non-existent object (dead lock possible!) • Objects stored in a shared space accessible to all processes • Objects identified by content rather than location Divide and Conquer Strategies
Linda Programming Paradigm • Distributed data structures accessible to many processes simultaneously • Processes accessing data structures simultaneously • Any data structure in tuple space is accessible to any process in that same tuple space • Linda processes aspire to know as little about each other as possible Divide and Conquer Strategies
Linda Operations • in/inp – input from tuple space (wait/no wait) (tuple removed in tuple space) • rd/rdp – read from tuple space (wait/no wait) (tuple remains in tuple space) • out – evaluate and then output to tuple space • eval – output to tuple space and then evaluate as series of processes Divide and Conquer Strategies
Linda Operations: out • out( t ) – new tuple t to be evaluated and then put into tuple space • t – sequence of typed values • Examples: ("a string", 12.96, 16, y) ( 0, 1 ) Divide and Conquer Strategies
Linda Operations: in • in( s ) – causes some tuple t to be withdrawn from tuple space • t – chosen arbitrarily from those that match s. • s – anti-tuple – sequence of typed fields that may be actual values or formal place holders. • t matches s if • Same number of fields • Types of fields match pairwise • Actual values in s matches values of corresponding field in t Divide and Conquer Strategies
Linda Operations: in • If s matches t then • Actual value in t assigned to formal place holder in s • Evoking process continues then continues to execute • If no match, evoking process waits until there is one • Field types • [unsigned] int, long, short, char • Float, double • Struct • Union • [] of arbitrary dimensions of above Divide and Conquer Strategies
Tuple Matching • in("a string", ?f, ?i, y ) – execution searches for passive data tuple having • First element that is "a string" • Second element that has the same type as variable f • Third element has same type as variable i • Fourth element has same value as variable y • Result: Get values for f and i Divide and Conquer Strategies
Linda Operations: inp • inp( s ) - same as in, except • No wait • Returns 1, if succeeds • Returns 0, if fails • May be inefficient depending on implementation Divide and Conquer Strategies
Linda Operations: rd/rdp • rd(s)/rdp( s ) - same as in/inp, except • tuple is read only, not removed from tuple space Divide and Conquer Strategies
Linda Operations: eval • eval( t ) - Similar to out except • Tuple is evaluated AFTER being placed in tuple space • New process is created to evaluate each field of t • When all fields completely evaluated, t becomes passive data tuple Divide and Conquer Strategies
Linda Operations: eval • Example: eval("e", 7, exp( 7 ) ) • Creates 3 element live tuple and returns immediately • Generates 3 processes: • Fist computes “e” • Second computes 7 • Third computes exp(7) • When all done, live tuple replaced by data tuple containing: ("e", 7, 1096.63… ) • Can be read with: rd("e", 7, ?value ) Divide and Conquer Strategies
Linda Operations: eval • Comparison with out for (i=0, i<100; i++) out("square roots", i, sqrt( i ) ); for (i=0, i<100; i++) eval("square roots", i, sqrt( i ) ); • Values are inherited only for explicitly referenced names, e.g., eval("Q", f( x, y ) ); Any static local or global variables in f are NOT initialized! Divide and Conquer Strategies
To Build A Linda Program • Drop 1 process into tuple space • It creates other process tuples • Process tuples execute in parallel, exchange data by • Generating data tuples • Reading data tuples • Consuming data tuples • When finished, become data tuple Divide and Conquer Strategies
Programming Example – Parallel Hello World – chello.cl #include <stdio.h> #include <unistd.h> #define NPROC 8 int real_main() { int i, hello(); out("count", 0); for (i = 0; i < NPROC; ++i) eval("hello_world", hello(i)); in("count", NPROC); for (i = 0; i < NPROC; ++i) in("hello_world", ? int); printf("All processors done\n"); return 0; } int hello(int id) { int j; char h[100]; if (gethostname(h, sizeof(h)) != 0) { fprintf(stderr, "Problem in gethostname()\n"); lexit(1); } printf("Hello World from node %s, virtual proc no: %d\n", h, id); in("count", ?j); out("count", j+1); return 0; } Divide and Conquer Strategies
Matrix Multiplication • Master –Initializes/cleans-up (real_main) • Dumps rows of A and columns of B into tuple space • Specifies first element to be computed • Handles assembly of data • Handles termination • Workers • Find out what to compute • Specifies what to be computed next • Gets appropriate row and column data • Computes element • Outputs computed element Divide and Conquer Strategies
Matrix Multiplication • Questions: • How many workers? • What tuples do we need? • How should we indicate termination? • Are there any performance issues? Divide and Conquer Strategies
real_main int real_main( argc, argv ) int argc; char **argv; { int dim, /* Actual dimension of matrix */ workers; /* the number of workers */ if ( argc != 3 ) { printf( "Usage: %s <workers> <dim>\n", *argv ); lexit( 1 ); } workers = atol( *++argv ); dim = atol( *++argv ); printf( "matrix -- workers: %d, dim: %d\n", workers, dim ); master( workers, dim ); return 0; } Divide and Conquer Strategies
master.1 void master( workers, dim ) int dim, workers; { int A[MAXARRAYSIZE][MAXARRAYSIZE], B[MAXARRAYSIZE][MAXARRAYSIZE], col_index, index, result[MAXARRAYSIZE][MAXARRAYSIZE], retriever, /* variable to temporarily hold the value read from tuplespace */ row_index, *row, /* pointer to a single row in A */ *col; /* pointer to a single col in B */ /* * Initialize the two matrices - A by row , B by col * and print them */ ... Divide and Conquer Strategies
master.2 /* Start the C-linda timer utility */ start_timer(); /* Put the the matrices in the tuple space */ for ( index = 0; index < dim; ++index ) { row = &A[ index ][ 0 ]; col = &B[ index ][ 0 ]; out( "A-row", index, row:dim ); out( "B-col", index, col:dim ); } /* Make a timer split */ timer_split( "done setting up" ); Divide and Conquer Strategies
master.3 /* Start workers */ for ( index = 0; index < workers; ++index ) { eval( "worker", worker( index, dim ) ); } /* Indicate element to work on */ out( "NEXT", 0 ); /* Retrieve each element of the product matrix*/ for ( index = 0; index < dim*dim; ++index ) { in( "Result", ?row_index, ?col_index, ?retriever ); result[ row_index ][ col_index ] = retriever; } Divide and Conquer Strategies
master.4 /* * Write out results */ ... /* Complete and print timing */ timer_split( "all done" ); print_times( ); } Divide and Conquer Strategies
worker.1 int worker( i, dim ) int i, dim; { int col[ MAXARRAYSIZE ], col_index, index, next_index, row[ MAXARRAYSIZE ], row_index, result, *cp, /* element in the column matrix */ *rp; /* element in the row matrix */ while( TRUE ) { Divide and Conquer Strategies
/* Get index of row of product matrix to compute */ in( "NEXT", ? index ); /* If no more work, indicate termination and stop */ if ( index < 0 ) { out( "NEXT", -1 ); return( 0 ); } else if ( index < dim * dim ) { /* Indicate the next node in the list */ next_index = index + 1; out( "NEXT", next_index ); } else { /* Put out a termination tuple */ out( "NEXT", -1 ); return( 0 ); } worker.2 Managing work to do tuple Divide and Conquer Strategies